




RallyGallery
Members
-
Joined
-
Last visited
-
Today by pure chance I had a look at the reads and writes in the 'Main' tab of my drives. All disks and cache drives, NVMeE drives normal. I noticed that the boot usb stick had a minimal amount of writes to it but the reads counter was huge and increasing every few seconds. I turned all the dockers off and also shutdown the Windows VM I use every day and the counter for the reads stopped. I turned on one by one the docker apps I have and it didn't change anything. However, when I started the Windows VM up it slowly increased again, a few reads every 10 seconds or so. The VM has a Nvidia graphics card attached to it passed through along with the sound and there is also a USB card attached and passed through for usb drives that I use. The unRaid usb boot stick is not in this usb card and is completely separate to the Windows VM. I have a second server running a Windows VM and the settings seem to match to this one I am having the 'problem' with. As far as I can tell I haven't got any logging going on and the 'reads' increase as soon as the Windows VM is turned on so it doesn't seem to be a Windows process or program in the VM. The unraid USB stick can't be seen by the Windows VM in any case. I have had a look around the forums and tried CoPilot but nothing really has helped. Any thoughts from anyone? As ever any help is greatly appreciated.
-
JorgeB - Server has been running with no errors for 24 hours now. The HBA card was the issue. Disk 4 was offline but I have got it back online and rebuilt and zero errors on any of the drives and all SMART info on all drives ok, cache pool is functioning with no issues. A clean install from backup I think also took away any doubts. Thanks for all your help and time. Really appreciated. itimpi - also thanks for the advice. Will try the HBA card in another PC to test. I will purchase another HBA card from ebay as I can't trust this one in the server. I can use it in a non-critical system. Thanks also to you for your help and input.
-
Hi JorgeB. An update and I may have sorted the problem based on your help and advice. I took out the USB stick, deleted all the files and copied a backup of the stick I had made before the upgrade. Rebooted and system was fine but immediately got errors. This has led me to believe that the HBA card has got a fault even though it boots up and sees the drives. I have taken the HBA card out and used normal sata cables to connect all the drives and rebooted the array with no errors so far. The array has been up for 30 mins and error logs are clear. Will leave it going overnight and see what happens. The original HBA card was off eBay and was second hand but had been flashed into IT mode so it wasn't brand new. Will buy another one in time once I am happy with the server. Thanks again.
-
JorgeB, many thanks for looking through the files. I have re-seated the HBA card and rebooted the server, same fault. I swapped the card into another slot, same fault. The HBA card detects all the drives and you can go into the configuration utility at bootup and everything seems in order. It sees all the drives and gives correct information. This started with me going to unRAID beta 7 and even though I ran back to the older stable version it seems odd that everything has coincided together. My last role of the dice is to take the USB and copy the backup files from unRAID 6.12 onto it and see what happens. That is exactly the system that was working before I went to the beta version. I am clutching at straws but worth a go? Else, maybe the card has faulted and I will purchase a new card and see what that does. Thanks again for your help, time and assistance.
-
Sorry it's taken a day or so. Latest diagnostics attached. This time when I started the array, Disk 1 is now offline where as it started with the initial problems as Disk 3 and then the second time I booted no errors at all. The shares all showed up correctly this time but then after 2 mins were not visible at all on the shares page. The VM starts but the docker containers are not working. I do not believe the array hard drives have any errors or problems, perhaps one of the SSD's has got an issue but again when I booted the second time the dockers all worked then the cache drive started flooding the log with errors. Any help is gratefully received but I am wondering if reinstalling the USB stick with a backup taken a week ago and going from there. Plus, maybe upgrading both cache SSD drives to zfs and starting my dockers from scratch. moog-diagnostics-20240704-1450.zip
-
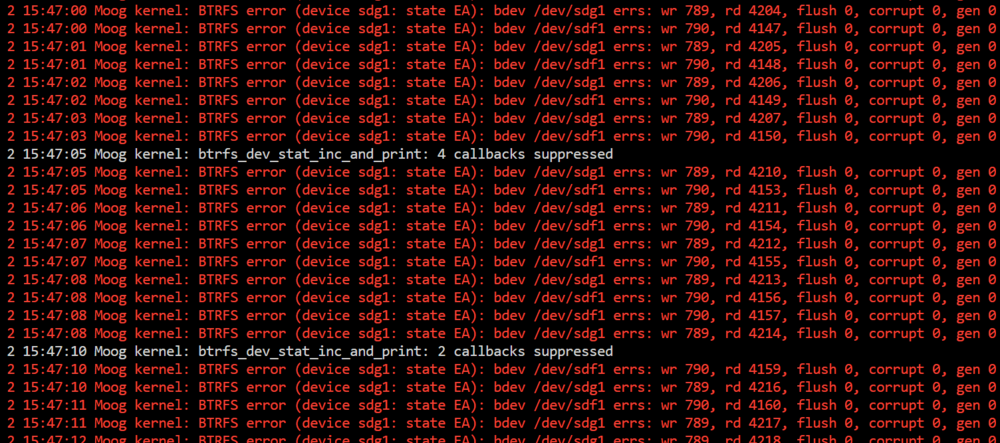
The cache drive is in a pool of 2 raid 1 SSD's. I wonder if one of the disks has failed in some way: I took this screen shot from the second of the cache drives: text error warn system array login Jul 2 15:06:52 Moog kernel: sd 10:0:4:0: [sdf] 468862128 512-byte logical blocks: (240 GB/224 GiB) Jul 2 15:06:52 Moog kernel: sd 10:0:4:0: [sdf] Write Protect is off Jul 2 15:06:52 Moog kernel: sd 10:0:4:0: [sdf] Mode Sense: 7f 00 10 08 Jul 2 15:06:52 Moog kernel: sd 10:0:4:0: [sdf] Write cache: enabled, read cache: enabled, supports DPO and FUA Jul 2 15:06:52 Moog kernel: sdf: sdf1 Jul 2 15:06:52 Moog kernel: sd 10:0:4:0: [sdf] Attached SCSI disk Jul 2 15:06:52 Moog kernel: BTRFS: device fsid e2f21b80-f3ed-4181-a646-6a5f79acd47a devid 2 transid 1645519 /dev/sdf1 scanned by udevd (954) Jul 2 15:07:39 Moog emhttpd: ADATA_SU630_2K45291E89ED (sdf) 512 468862128 Jul 2 15:07:39 Moog emhttpd: import 31 cache device: (sdf) ADATA_SU630_2K45291E89ED Jul 2 15:07:39 Moog emhttpd: read SMART /dev/sdf Jul 2 15:08:50 Moog emhttpd: #011devid 2 size 223.57GiB used 84.03GiB path /dev/sdf1 Jul 2 15:08:50 Moog kernel: BTRFS info (device sdg1): bdev /dev/sdf1 errs: wr 1, rd 0, flush 0, corrupt 0, gen 0 Jul 2 15:36:41 Moog kernel: sd 10:0:4:0: [sdf] tag#2340 UNKNOWN(0x2003) Result: hostbyte=0x01 driverbyte=DRIVER_OK cmd_age=5s Jul 2 15:36:41 Moog kernel: sd 10:0:4:0: [sdf] tag#2340 CDB: opcode=0x28 28 00 04 ff 44 90 00 00 68 00 Jul 2 15:36:41 Moog kernel: I/O error, dev sdf, sector 83838096 op 0x0:(READ) flags 0x80700 phys_seg 1 prio class 2 Jul 2 15:36:41 Moog kernel: sd 10:0:4:0: [sdf] tag#2342 UNKNOWN(0x2003) Result: hostbyte=0x01 driverbyte=DRIVER_OK cmd_age=5s Jul 2 15:36:41 Moog kernel: sd 10:0:4:0: [sdf] tag#2346 UNKNOWN(0x2003) Result: hostbyte=0x01 driverbyte=DRIVER_OK cmd_age=5s Jul 2 15:36:41 Moog kernel: sd 10:0:4:0: [sdf] tag#2342 CDB: opcode=0x28 28 00 04 fe dd 48 00 00 80 00 Jul 2 15:36:41 Moog kernel: I/O error, dev sdf, sector 83811656 op 0x0:(READ) flags 0x80700 phys_seg 2 prio class 2 Jul 2 15:36:41 Moog kernel: sd 10:0:4:0: [sdf] tag#2346 CDB: opcode=0x28 28 00 04 93 4c b8 00 00 08 00 Jul 2 15:36:41 Moog kernel: I/O error, dev sdf, sector 76762296 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 2 Jul 2 15:36:41 Moog kernel: sd 10:0:4:0: [sdf] tag#2343 UNKNOWN(0x2003) Result: hostbyte=0x01 driverbyte=DRIVER_OK cmd_age=5s Jul 2 15:36:41 Moog kernel: sd 10:0:4:0: [sdf] tag#2343 CDB: opcode=0x28 28 00 07 7b 0d 00 00 00 08 00 Jul 2 15:36:41 Moog kernel: I/O error, dev sdf, sector 125504768 op 0x0:(READ) flags 0x80700 phys_seg 1 prio class 2 Jul 2 15:36:41 Moog kernel: BTRFS error (device sdg1): bdev /dev/sdf1 errs: wr 1, rd 1, flush 0, corrupt 0, gen 0 Jul 2 15:36:41 Moog kernel: sd 10:0:4:0: [sdf] tag#2344 UNKNOWN(0x2003) Result: hostbyte=0x01 driverbyte=DRIVER_OK cmd_age=5s Jul 2 15:36:41 Moog kernel: sd 10:0:4:0: [sdf] tag#2344 CDB: opcode=0x2a 2a 00 08 78 5e 00 00 00 40 00 Jul 2 15:36:41 Moog kernel: I/O error, dev sdf, sector 142106112 op 0x1:(WRITE) flags 0x800 phys_seg 6 prio class 2 Jul 2 15:36:41 Moog kernel: BTRFS error (device sdg1): bdev /dev/sdf1 errs: wr 2, rd 1, flush 0, corrupt 0, gen 0 Jul 2 15:36:41 Moog kernel: sd 10:0:4:0: [sdf] tag#2345 UNKNOWN(0x2003) Result: hostbyte=0x01 driverbyte=DRIVER_OK cmd_age=5s Jul 2 15:36:41 Moog kernel: sd 10:0:4:0: [sdf] tag#2345 CDB: opcode=0x2a 2a 00 08 79 58 f0 00 00 40 00 Jul 2 15:36:41 Moog kernel: I/O error, dev sdf, sector 142170352 op 0x1:(WRITE) flags 0x800 phys_seg 1 prio class 2 Jul 2 15:36:41 Moog kernel: BTRFS error (device sdg1): bdev /dev/sdf1 errs: wr 3, rd 1, flush 0, corrupt 0, gen 0 Jul 2 15:36:41 Moog kernel: BTRFS error (device sdg1): bdev /dev/sdf1 errs: wr 4, rd 1, flush 0, corrupt 0, gen 0 Jul 2 15:36:41 Moog kernel: sd 10:0:4:0: [sdf] Synchronizing SCSI cache Jul 2 15:36:41 Moog kernel: sd 10:0:4:0: [sdf] Synchronize Cache(10) failed: Result: hostbyte=0x01 driverbyte=DRIVER_OK Jul 2 15:36:46 Moog kernel: BTRFS error (device sdg1: state EA): bdev /dev/sdf1 errs: wr 29, rd 97, flush 0, corrupt 0, gen 0 Jul 2 15:36:46 Moog kernel: BTRFS error (device sdg1: state EA): bdev /dev/sdf1 errs: wr 29, rd 98, flush 0, corrupt 0, gen 0
-
I have just booted the server back up and downloaded two logs. One as the server booted up and then another as the array came online. These two diagnostic files are attached and named accordingly. However, as I type, this the array seems to be working ok which seems incredibly strange. The shares have come back and are displaying correctly. All the docker containers are working as well as the VM's. Maybe it was 'turn it on and off again'. Maybe the diagnostics will show something? UPDATE : after 30 mins the server is starting to fail with containers not starting to work and the VMs not working now. The log files keep showing this: server booted_array offline-diagnostics-20240702-1508.zip array online-diagnostics-20240702-1509.zip
-
ok will do. Thanks for your help. Will report here
-
Hello all, A very strange sequence of events happened and just wanted to get some advice. I decided to try UnRAID 7 Beta on my backup server and it installed and ran with no problems for about 30 mins. This server has been running with zero issues or problems and has been absolutely solid for the last 12 months of running. The GUI then stopped responding and I was unable to connect to it. On the screen I have on the server rack there were pages of errors I have never seen before. I was able to reboot the server after some time and one of the hard drives had 'failed' without any warning. No errors on the drive were reported and SMART gave no hints or errors. Before the installation of unRAID Beta 7 no errors at all. I decided to roll back to version 6.12 of UnRAID and everything then seemed to function apart from disk 3 'failing again'. I removed the disk and put it in a USB caddy and inspected it in Windows via data software and the disk had no bad sectors and no errors of any kind. I put it back in the array and turned on the server. I had a new config with the drives in their original slots and parity needed to be rebuilt which completed with no errors. All seemed good. Then after an hour all the drives had 160 errors on them and the cache pool has completely failed with no docker containers functioning at all. The data is showing on the drives, however in the shares tab every single share has disappeared. Having used UnRAID for 6 years I have never seen such a situation. Note : I have backup of all the data so I am not losing anything. Plus, the USB key appears to be perfectly fine. My thought on a possible solution is to basically start again from scratch? I have a backup of my key, plus I have all the locations of the disks in the correct slots in the array in unRAID. Install 6.12 on the USB stick using the unRAID creation tool and copy my key file onto it. Boot the server Configure the array and format the disks Install dockers and VM again Copy data Install parity disk in the slot Any other advice? I really have no idea what happened! I have attached the last diagnostics file that I managed to get from the server before I have shut it down in case that helps? Any help or insights anyone can give is greatly appreciated. server-diagnostics-20240701-0828.zip
-
Have done that already. Will try again though
-
Just an update on this error message. The server is working perfectly but the following messages appear every 5 minutes in the log: Dec 25 14:40:06 PCServer kernel: Buffer I/O error on dev sdb1, logical block 9959896, async page read Dec 25 14:45:06 PCServer ntfs-3g[10525]: ntfs_attr_pread_i: ntfs_pread failed: Input/output error Dec 25 14:45:06 PCServer ntfs-3g[10525]: Failed to read vcn 0x0 from inode 5: Input/output error (Exactly the same three lines of error that occurred on Christmas Day, as today). As per the advice from JorgeB, I checked the disks but I don't have a disk assigned as sdb in the array or as an unassigned disk. I have an external disk via a usb enclosure separate to the array which is used to hold security camera footage from Blue Iris which runs as a Windows VM. That is also working perfectly. If anything this is more of an irritation to know what it is! Any help is greatly appreciated.
-
Happy Christmas everyone. Just a quick post. My server seemed to stop Plex and various other dockers early on Christmas morning and I rebooted and it all seemed to work ok. Plex now works. However, looking at the logs I get the following errors: Dec 25 14:40:06 PCServer kernel: Buffer I/O error on dev sdb1, logical block 9959896, async page read Dec 25 14:45:06 PCServer ntfs-3g[10525]: ntfs_attr_pread_i: ntfs_pread failed: Input/output error Dec 25 14:45:06 PCServer ntfs-3g[10525]: Failed to read vcn 0x0 from inode 5: Input/output error which repeats every few minutes. I attach the logs file also to this post. PCServer is the name of the unRAID server. I have checked all disks, cache disks and m2 drives and nothing is showing any errors. I have replaced cache drives before this this error seems to be very different. I wondered if it was the USB stick but again that seems ok and the system boots fine. I am now wondering if it's maybe a Windows VM? Can anyone point me in the right direction? Many thanks for any help. pcserver-syslog-20221225-1444.zip
-
Sorted! I added the new drive again and now it works. As you said a bug. So for reference, once you add the larger drive, stop the array, unassign it from the pool, let the balance run and you have one drive in the pool. Stop the array, add new drive back in again and hey presto, it works. Thanks ever so much for your help.
-
Many thanks for your help. I will give it a go, The new disk is in the array as an unassigned device, so will see it what happens. Will report back the results and hopefully this thread will be closed. Only having 480Gb is not a problem. My VM's and downloads and transcode stuff are on two separate NVME drives in their own separate pools. Appreciate your time.
-
Thanks for your help. As you suggested I have removed the new SSD and it's now as an unassigned device. Cache pool has rebalanced and dockers are working fine. Just a single cache drive currently. New diagnostics attached. To replaced the old cache drive I : Stopped the docker se4rvice. Stopped the array Removed the 'defective' SSD from the cache pool Shut down server Removed old drive and put in the new 500gb drive. Restarted the server. Assigned the new SSD to the cache pool Start server Cache pool rebalanced and we end up with my initial problem as per the post. Thanks for any help you can give. pcserver-diagnostics-20210911-1159.zip

