

RallyGallery
-
Posts
41 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by RallyGallery
-
-
Just an update on this error message. The server is working perfectly but the following messages appear every 5 minutes in the log:
Dec 25 14:40:06 PCServer kernel: Buffer I/O error on dev sdb1, logical block 9959896, async page read
Dec 25 14:45:06 PCServer ntfs-3g[10525]: ntfs_attr_pread_i: ntfs_pread failed: Input/output error
Dec 25 14:45:06 PCServer ntfs-3g[10525]: Failed to read vcn 0x0 from inode 5: Input/output error(Exactly the same three lines of error that occurred on Christmas Day, as today).
As per the advice from JorgeB, I checked the disks but I don't have a disk assigned as sdb in the array or as an unassigned disk. I have an external disk via a usb enclosure separate to the array which is used to hold security camera footage from Blue Iris which runs as a Windows VM. That is also working perfectly.
If anything this is more of an irritation to know what it is! Any help is greatly appreciated.
-
Happy Christmas everyone.
Just a quick post. My server seemed to stop Plex and various other dockers early on Christmas morning and I rebooted and it all seemed to work ok. Plex now works. However, looking at the logs I get the following errors:
Dec 25 14:40:06 PCServer kernel: Buffer I/O error on dev sdb1, logical block 9959896, async page read
Dec 25 14:45:06 PCServer ntfs-3g[10525]: ntfs_attr_pread_i: ntfs_pread failed: Input/output error
Dec 25 14:45:06 PCServer ntfs-3g[10525]: Failed to read vcn 0x0 from inode 5: Input/output errorwhich repeats every few minutes. I attach the logs file also to this post. PCServer is the name of the unRAID server.
I have checked all disks, cache disks and m2 drives and nothing is showing any errors. I have replaced cache drives before this this error seems to be very different. I wondered if it was the USB stick but again that seems ok and the system boots fine.
I am now wondering if it's maybe a Windows VM?
Can anyone point me in the right direction? Many thanks for any help.
-
Sorted!
I added the new drive again and now it works.As you said a bug.
So for reference, once you add the larger drive, stop the array, unassign it from the pool, let the balance run and you have one drive in the pool. Stop the array, add new drive back in again and hey presto, it works.
Thanks ever so much for your help.
-
 1
1
-
-
Many thanks for your help. I will give it a go, The new disk is in the array as an unassigned device, so will see it what happens. Will report back the results and hopefully this thread will be closed. Only having 480Gb is not a problem. My VM's and downloads and transcode stuff are on two separate NVME drives in their own separate pools.
Appreciate your time.
-
Thanks for your help. As you suggested I have removed the new SSD and it's now as an unassigned device. Cache pool has rebalanced and dockers are working fine. Just a single cache drive currently. New diagnostics attached.
To replaced the old cache drive I :
- Stopped the docker se4rvice.
- Stopped the array
- Removed the 'defective' SSD from the cache pool
- Shut down server
- Removed old drive and put in the new 500gb drive.
- Restarted the server.
- Assigned the new SSD to the cache pool
- Start server
- Cache pool rebalanced and we end up with my initial problem as per the post.
Thanks for any help you can give.
-
I have had a cache pool of two SSD in raid 1 running with no issues. In the last two weeks I have noticed many errors in the main log with one of the SSD's. I decided to buy a new SSD and replace it. The cache pool drives have been 500GB.
Drive replaced with no problems, but.....The new drive was purchased as 500GB as per the original drive, the original 'good' drive still in the cache' reports 480GB (sdf). I have tried to put this in raid 1 but nothing happens. Is this because that unRAID thinks the two drives are not of the same capacity? I suspect it is, which is a nuisance as I purchased 500GB drives to match.
Have seen log file with :
Sep 11 10:53:02 PCServer ool www[7241]: /usr/local/emhttp/plugins/dynamix/scripts/btrfs_balance 'start' '/mnt/cache' '-dconvert=raid1,soft -mconvert=raid1,soft' Sep 11 10:53:02 PCServer kernel: BTRFS error (device sdf1): balance: invalid convert data profile raid1
Full diagnostics file attached.

Is there a work around for this?

-
Have done an extended smart test and no errors found
-
I checked all the connections and made sure they were all ok. Rebooted server and can do a SMART test now. Diagnostics attached. Also screenshot of the disk status and I think this disk is failing.
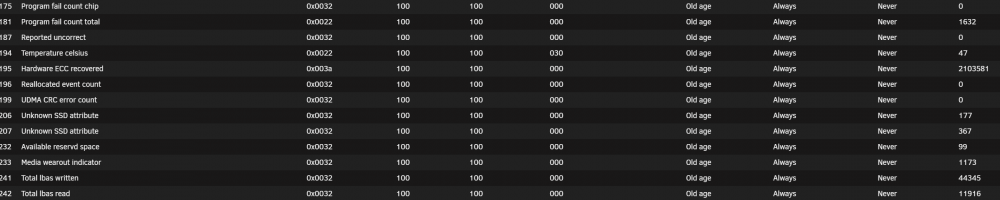
-
Full Diagnostics file.
-
I have a cache pool made up of two SSD 480gb SSD drives in a raid 1. Over the last few days I have noticed that my trim cron job has errored. Just looked at the server and the log file is nearly full. It is full of entries such as :
Sep 6 21:01:19 PCServer kernel: sd 10:0:0:0: [sdi] tag#28 UNKNOWN(0x2003) Result: hostbyte=0x04 driverbyte=0x00 cmd_age=0s Sep 6 21:01:19 PCServer kernel: sd 10:0:0:0: [sdi] tag#28 CDB: opcode=0x2a 2a 00 11 52 0f 00 00 00 80 00 Sep 6 21:01:19 PCServer kernel: blk_update_request: I/O error, dev sdi, sector 290590464 op 0x1:(WRITE) flags 0x1800 phys_seg 16 prio class 0 Sep 6 21:01:19 PCServer kernel: BTRFS warning (device sdf1): lost page write due to IO error on /dev/sdi1 (-5) Sep 6 21:01:19 PCServer kernel: BTRFS warning (device sdf1): lost page write due to IO error on /dev/sdi1 (-5) Sep 6 21:01:19 PCServer kernel: BTRFS warning (device sdf1): lost page write due to IO error on /dev/sdi1 (-5) Sep 6 21:01:19 PCServer kernel: BTRFS error (device sdf1): error writing primary super block to device 2 Sep 6 21:01:24 PCServer kernel: scsi_io_completion_action: 53 callbacks suppressed Sep 6 21:01:24 PCServer kernel: sd 10:0:0:0: [sdi] tag#4 UNKNOWN(0x2003) Result: hostbyte=0x04 driverbyte=0x00 cmd_age=0s Sep 6 21:01:24 PCServer kernel: sd 10:0:0:0: [sdi] tag#4 CDB: opcode=0x2a 2a 00 00 12 9c 88 00 00 18 00 Sep 6 21:01:24 PCServer kernel: print_req_error: 54 callbacks suppressed Sep 6 21:01:24 PCServer kernel: blk_update_request: I/O error, dev sdi, sector 1219720 op 0x1:(WRITE) flags 0x0 phys_seg 3 prio class 0
I have a feeling that the second cache drive is failing? I can not also undertake a smart report.
I would say the drive is failing or has failed? Unraid is not showing any errors in the 'Main tab'. The drive in question has a lot more reads and writes.
As part of a cache pool, I should be able to stop the array. Unassign the drive, power down the server, install new SSD, assign it and it should rebuild?
Any help or advice is greatly appreciated.
-
On 4/26/2021 at 9:22 AM, JorgeB said:
If the UD NVMe device was formatted with a relatively recent version of UD you can assign it to a new pool, start the array, then add the other NVMe device.
Thanks for the post. The NVME was formatted with version 6.9 so maybe it will keep the data when I assign it to the drive pool? It will be the only one in the pool, so that should also not complicate anything. The new NVME will be in a separate pool and it will be brand new so no issues with losing data there.
-
I have just watched the latest @SpaceInvaderOne video on drive pools and managing them. My server is two years old and I have two ssd's in raid 1 for my docker containers which I will leave well alone. I also have an NVME drive mounted as an unassigned device which has my Windows VM running and it works really well.
Now with unRaid 6.9 I am thinking of creating some drive pools.
I have got another NVME drive coming which I will install and create a drive pool on that one device and use it for files downloaded etc. That's easy to setup.
However, I was thinking of creating another drive pool with the original nvme for VM's. If I move the current unassigned devices nvme drive into this new pool, it will wipe the drive if I am correct? What is the best way to retain the VM data held on this current installed nvme drive and move it all to the new drive pool?
I just want to ensure I use the best (and easiest) procedure to minimise any problems along the way and thought the community would have the best ideas. Thanks for any help.
-
Just a quick shout out for for some guidance.
I used the @SpaceInvaderOne video to setup a Minecraft server and also used Cloudflare. Worked a treat. Ran for a week or so. Then had an update for Binhex's container (great work on all your containers, use them for everything!) and it updated with no errors but then the minecraft server was not available on the local network or via the internet. When you connect to the WebUI for the container (user name and password work fine) you get the following message in the window:
"There is no screen to be attached matching minecraft."
and that's it. Previously the WebUI showed all the data for the minecraft server, who connected, what the world was doing, etc.
There was another container update and I had the glibc error which I corrected with the post in this thread and that's all fixed so no problems there. However, I still get the console window error and the minecraft server not being able to connect. The container starts and runs, had a look through logs and couldn't see anything obvious.
Log posted below. Any help is greatly appreciated (username and password deleted from logs).
Created by...
___. .__ .__
\_ |__ |__| ____ | |__ ____ ___ ___
| __ \| |/ \| | \_/ __ \\ \/ /
| \_\ \ | | \ Y \ ___/ > <
|___ /__|___| /___| /\___ >__/\_ \
\/ \/ \/ \/ \/
https://hub.docker.com/u/binhex/
2021-04-05 03:28:04.575012 [info] Host is running unRAID
2021-04-05 03:28:04.620424 [info] System information Linux 85aa981c4a94 5.10.21-Unraid #1 SMP Sun Mar 7 13:39:02 PST 2021 x86_64 GNU/Linux
2021-04-05 03:28:04.675189 [info] OS_ARCH defined as 'x86-64'
2021-04-05 03:28:04.730666 [info] PUID defined as '99'
2021-04-05 03:28:04.793458 [info] PGID defined as '100'
2021-04-05 03:28:04.905287 [info] UMASK defined as '000'
2021-04-05 03:28:04.956405 [info] Permissions already set for volume mappings
2021-04-05 03:28:05.109976 [info] Deleting files in /tmp (non recursive)...
2021-04-05 03:28:05.163616 [info] CREATE_BACKUP_HOURS defined as '12'
2021-04-05 03:28:05.217617 [info] PURGE_BACKUP_DAYS defined as '14'
2021-04-05 03:28:05.276984 [info] ENABLE_WEBUI_CONSOLE defined as 'yes'
2021-04-05 03:28:05.329073 [info] ENABLE_WEBUI_AUTH defined as 'yes'
2021-04-05 03:28:05.382607 [info] WEBUI_USER defined as '*********'
2021-04-05 03:28:05.435596 [info] WEBUI_PASS defined as '********'
2021-04-05 03:28:05.489763 [info] WEBUI_CONSOLE_TITLE defined as 'Minecraft Java'
2021-04-05 03:28:05.540730 [info] CUSTOM_JAR_PATH defined as '/config/minecraft/minecraft_server.jar'
2021-04-05 03:28:05.593004 [info] JAVA_VERSION defined as '8'
2021-04-05 03:28:05.671902 [info] JAVA_INITIAL_HEAP_SIZE defined as '2048'
2021-04-05 03:28:05.724184 [info] JAVA_MAX_HEAP_SIZE defined as '4096M'
2021-04-05 03:28:05.780979 [info] JAVA_MAX_THREADS defined as '8'
2021-04-05 03:28:05.834088 [info] Starting Supervisor...
2021-04-05 03:28:06,622 INFO Included extra file "/etc/supervisor/conf.d/minecraft-server.conf" during parsing
2021-04-05 03:28:06,622 INFO Set uid to user 0 succeeded
2021-04-05 03:28:06,628 INFO supervisord started with pid 6
2021-04-05 03:28:07,631 INFO spawned: 'backup-script' with pid 124
2021-04-05 03:28:07,635 INFO spawned: 'purge-script' with pid 125
2021-04-05 03:28:07,638 INFO spawned: 'shutdown-script' with pid 126
2021-04-05 03:28:07,641 INFO spawned: 'start-script' with pid 127
2021-04-05 03:28:07,642 INFO reaped unknown pid 7 (exit status 0)
2021-04-05 03:28:07,650 DEBG 'backup-script' stdout output:
[info] Waiting 12 hours before running worlds backup...
2021-04-05 03:28:07,650 INFO success: backup-script entered RUNNING state, process has stayed up for > than 0 seconds (startsecs)
2021-04-05 03:28:07,651 INFO success: purge-script entered RUNNING state, process has stayed up for > than 0 seconds (startsecs)
2021-04-05 03:28:07,651 INFO success: shutdown-script entered RUNNING state, process has stayed up for > than 0 seconds (startsecs)
2021-04-05 03:28:07,651 INFO success: start-script entered RUNNING state, process has stayed up for > than 0 seconds (startsecs)
2021-04-05 03:28:07,652 DEBG 'purge-script' stdout output:
[info] Removing any Minecraft worlds backups with a creation date older than 14 days...
2021-04-05 03:28:07,659 DEBG 'start-script' stdout output:
[info] Minecraft folder '/config/minecraft' already exists, rsyncing newer files...
2021-04-05 03:28:07,726 DEBG 'start-script' stdout output:
[info] Checking EULA is set to 'true'...
2021-04-05 03:28:07,728 DEBG 'purge-script' stdout output:
[info] Checking for old backups in 12 hours...
2021-04-05 03:28:07,731 DEBG 'start-script' stdout output:
[info] EULA set to 'true'
2021-04-05 03:28:07,733 DEBG 'start-script' stdout output:
[info] Starting Minecraft Java process...
2021-04-05 03:28:07,740 DEBG 'start-script' stdout output:
[info] Minecraft Java process is running
2021-04-05 03:28:07,740 DEBG 'start-script' stdout output:
[info] Starting Minecraft console Web UI...
2021-04-05 03:28:07,797 DEBG 'start-script' stderr output:
2021/04/05 03:28:07 Permitting clients to write input to the PTY.
2021/04/05 03:28:07 Using Basic Authentication
2021/04/05 03:28:07 Server is starting with command: screen -x minecraft
2021-04-05 03:28:07,798 DEBG 'start-script' stderr output:
2021/04/05 03:28:07 URL: http://127.0.0.1:8222/
2021/04/05 03:28:07 URL: http://172.17.0.2:8222/
2021-04-05 11:12:06,558 DEBG 'start-script' stderr output:
2021/04/05 11:12:06 192.168.1.180:50349 401 GET /
2021-04-05 11:12:07,979 DEBG 'start-script' stderr output:
2021/04/05 11:12:07 Basic Authentication Succeeded: 192.168.1.180:50349
2021-04-05 11:12:07,980 DEBG 'start-script' stderr output:
2021/04/05 11:12:07 192.168.1.180:50349 200 GET /
2021-04-05 11:12:08,008 DEBG 'start-script' stderr output:
2021/04/05 11:12:08 Basic Authentication Succeeded: 192.168.1.180:50349
2021-04-05 11:12:08,020 DEBG 'start-script' stderr output:
2021/04/05 11:12:08 Basic Authentication Succeeded: 192.168.1.180:50352
2021-04-05 11:12:08,020 DEBG 'start-script' stderr output:
2021/04/05 11:12:08 Basic Authentication Succeeded: 192.168.1.180:50350
2021/04/05 11:12:08 192.168.1.180:50350 200 GET /auth_token.js
2021/04/05 11:12:08 192.168.1.180:50352 200 GET /js/gotty.js
2021-04-05 11:12:08,021 DEBG 'start-script' stderr output:
2021/04/05 11:12:08 192.168.1.180:50349 200 GET /js/hterm.js
2021-04-05 11:12:08,052 DEBG 'start-script' stderr output:
2021/04/05 11:12:08 New client connected: 192.168.1.180:50353
2021-04-05 11:12:08,366 DEBG 'start-script' stderr output:
2021/04/05 11:12:08 Command is running for client 192.168.1.180:50353 with PID 151 (args="-x minecraft"), connections: 1
2021/04/05 11:12:08 192.168.1.180:50353 101 GET /ws
2021-04-05 11:12:08,400 DEBG 'start-script' stderr output:
2021/04/05 11:12:08 Command exited for: 192.168.1.180:50353
2021-04-05 11:12:08,401 DEBG 'start-script' stderr output:
2021/04/05 11:12:08 read tcp 172.17.0.2:8222->192.168.1.180:50353: use of closed network connection
2021/04/05 11:12:08 Connection closed: 192.168.1.180:50353, connections: 0
2021-04-05 11:12:08,422 DEBG 'start-script' stderr output:
2021/04/05 11:12:08 Basic Authentication Succeeded: 192.168.1.180:50349
2021-04-05 11:12:08,422 DEBG 'start-script' stderr output:
2021/04/05 11:12:08 192.168.1.180:50349 200 GET /favicon.png
-
4 hours ago, itimpi said:
This sounds wrong. It should be the full path to the vdisk file on the NVME drive and I would expect it to be something along the lines of /mnt/disks/nvme_mount_point/vdisk_file_name. You may have ended up specifying a location in RAM

Success! I have installed the VM. I changed the mount point as you pointed out and it works.
Thank you to everyone who has helped, it is really appreciated. unRaid is not just a great system, the community is superb!
-
3 hours ago, itimpi said:
This sounds wrong. It should be the full path to the vdisk file on the NVME drive and I would expect it to be something along the lines of /mnt/disks/nvme_mount_point/vdisk_file_name. You may have ended up specifying a location in RAM
ah ok, thanks very much. Will give that a go!
-
Update! The server is working well, no more failures. I decided to create a new vm on the nvme disk due to the main ine I use causing issues for some reason (as discussed above and it will be deleted). I also have another VM running on the cache disk which just runs Blue Iris. The new VM is causing a strange problem. VM creates and starts with no problem. Windows 10 setup loads and I can select the virtio store driver and select where to create the primary partition and click 'Next' and it freezes. In unraid it says the VM is paused and has an orange dot next to the icon in the unraid GUI. I have also ensured that the Primary disk location is 'manual' and select 'remote' for the unassigned nvme so it's not creating it on the cache pool.
I have fiddled around with unassigned devices setting for the nvme drive and at times when you select the windows partition you see the actual physical nvme disk and also the 30g unraid assigned space on the nvme in the select partition to create Windows 10 on.
The nvme is mounted, not shared (only want to use it to store VM's on) and no pass through. I will also create a test vm on the cache drive to see if I can create this same behaviour.
Any thoughts?
-
The good news for the screenshot is that it’s for the ‘old’ VM which I am going to delete and not worry about. I just included it for info but it actually caused more confusion! Apologies for that! I have had no more issues as such. The external hard drive says missing in the historical section of unassigned devices but it’s passed through to the vm so that all works perfectly.
In terms of the two options I want to place all the vm’s on the nvme and run them off there. Can you assist on how to move them over? I can normally work this stuff out but you are such a big help and it really saves time and stress!
So to recap the unraid server boots up perfectly. The nvme drive is installed and working and mounted. I have a Windows VM that works fine with no errors and sees the external hard drive for Blue Iris use.
Just want to move all VMs onto the nvme disk and run them all from there. Then have my cache pool just for docker containers.
As ever, thank you!
-
2 hours ago, civic95man said:
I'm still on the 6.8 series but the 6.9 seems to have what you need.
Autostarting the VM is always a risky proposition as you could run into problems as you've seen. My personal preference is that unless it's running some kind of critical task (such as pfsense) then I don't see any reason to autostart. Again, that is just my personal preference.
Last I looked at your logs (and in the screenshot), it looked like the audio device is already split into it's own group.
I would probably make sure the VM is set to manually start. Then install the nvme (do not adjust the pcie stub yet). With the new hardware how you want it, then adjust the pcie stub on the iommu group and reboot for those to take effect. Then you can configure the VMs to passthrough those stubbed components.
Remember, to repeat the process with any new hardware you've added - in my case, I had forgotten what I had done so it took me by surprise.
No problem! Sounds like you have a good grasp on how this all works now.
Great advice! I have an update and success, well nearly success. I had a play around with changing the iommu groups and tried stubbing, using in the built ability in teh devices section and wrote the config file. I pass through an external usb drive to record video from Blue Iris and this is passed through to the VM. I got to the stage where I didn't need the sound card so didn't pass that through and could see the nvme and also the external drive and teh system did not crash due to the 'usb error'. My main vm refused to work, it kept crashing the system, but by not autostarting the VM (advice noted and will always be used!) it was easy to reboot and try something else. My other VM worked a treat and didn't crash, so I have moved to that, set up Blue Iris (I had already backed up the settings) and it now works. I will just delete the other VM which was causing problems (see screenshot below when it tried to start)
Final ask, if I can?? What is the best procedure to move the VM's which are held on my cache (2 x ssd in mirror 1) to the now working, and showing nvme? The nvme drive is formated and mounted and not attached to teh cache pool or array. It basically sat there waiting to be used. I want to ensure I have get this right! You have been so helpful and this is the final piece of the jigsaw.
Thanks ever so much for all your help, time and assistance!
-
10 hours ago, civic95man said:
Yes, the problem is that I had "stubbed" several components and when the new GPU was added, the PCIe assignments changed but the stubbed assignments didn't - meaning that several items (disk controllers, network adapters) disappeared. I just had to edit my vfio-pci file and I was good
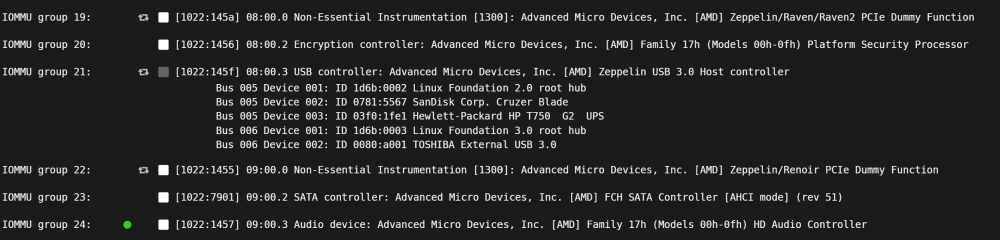
Thanks ever so much for your help! This is exactly the problem. Been doing some research based on your comments. unRaid 6.9 has the plugin you were talking about installed when you inspect the iomuu groups. The sound card is passed through to the VM and the VM is set to autostart. I could get rid of the sound card passthrough but first I will try and split it out in the iomuu groups. Also setting the VM to manual start just in case.
When looking at the groups there is a green dot next to devices passed through to the VM so I will attached them to the vfio.pci file and see what happens. All done via the iomuu page and much easier now that the plugin is incorporated. Screen shot below.
If that all works I will install the nvme and try again.
Will keep you updated with the progress!
If that works I may try the second GPU!!
Thanks again!
-
36 minutes ago, civic95man said:
I'm assuming that you are passing some hardware to the VMs, such as a GPU. I don't see any mention of stubbing hardware via the vfio-pci.cfg file but I can only assume that you are (can't remember if that shows up in the diagnostics). You will most likely need to update that config file as well as your VMs once you install your nvme. Whenever you install new hardware that interfaces with the PCIe bus, it can shift the existing allocations around. This can cause issues with stubbed hardware, where something that shouldn't have been stubbed suddenly is (i.e. USB ports with the unraid flash drive on them, disk controllers, etc). This can also cause the VM to try to access hardware at the previous address, which now is occupied by something else.
Long story short - this happened to me when I installed a second GPU; all of the PCIe assignments changed and I had to recreate my vfio-pci.cfg file to stub the correct hardware.
Thanks for the reply. I am passing a sound card through to the VM I have plus an unassigned device hard drive for use on Blue Iris. No GPU. Interesting you said about when you installed a second GPU as I had the same error as now, with change of screen, no docker or VM Manager running. I wonder if this is indeed the problem? The unraid USB I have shows no errors as such and as soon as I take out the NVME then all is well. I did want to add a second GPU to pass through to the Windows VM but after all the hassle a year ago I decided against it. If this error can be corrected I would give it another go!
I have attached the latest diagnostics file which I created with teh problems and the nvme drive in.
So my next question, what do I need to write in the vfio-pci.cfg file?
Thanks for the help and reading the post.
-
Sorry my apologies.
I have installed the nvme drive and had another go. Same errors, however, I have captured as much data as I can. I downloaded a diagnostics file with the flash drive installed. It's attached below. Plus had a look at usb information. Screenshots below. It looks like a usb problem? Took the nvme drive out and system works fine.
The only usb2 ports are on the front of the case so I can give that a try, unless you think there is anything else I should do based on the latest diagnostic report and screen shot.
Thanks ever so much for your time and help.
-
A quick update. I have powered down the server and checked the USB stick and it had no errors. I have rebooted the server and removed any previous nvidia build and installed 6.9 rc2 and got everything working. All the nvidia drivers, vm's and containers work perfectly.
I am going to install the nvme drive and see what happens. Will keep you updated.
I have kept the USB stick in the same port as you suggested.
-
I have a backup of the usb so that's not a problem. I will run the usb drive through checkdisk. i wonder if its worth getting a new usb and moving the system to a new usb stick?
I was also going to update to 6.9. its rc2 but looks pretty stable. It also has built in nvidia drivers so that would be better than the version I am using, as you say its been discontinued. I wonder if I upgrade and try the nvme again it may work?
Thanks again for your time.
-
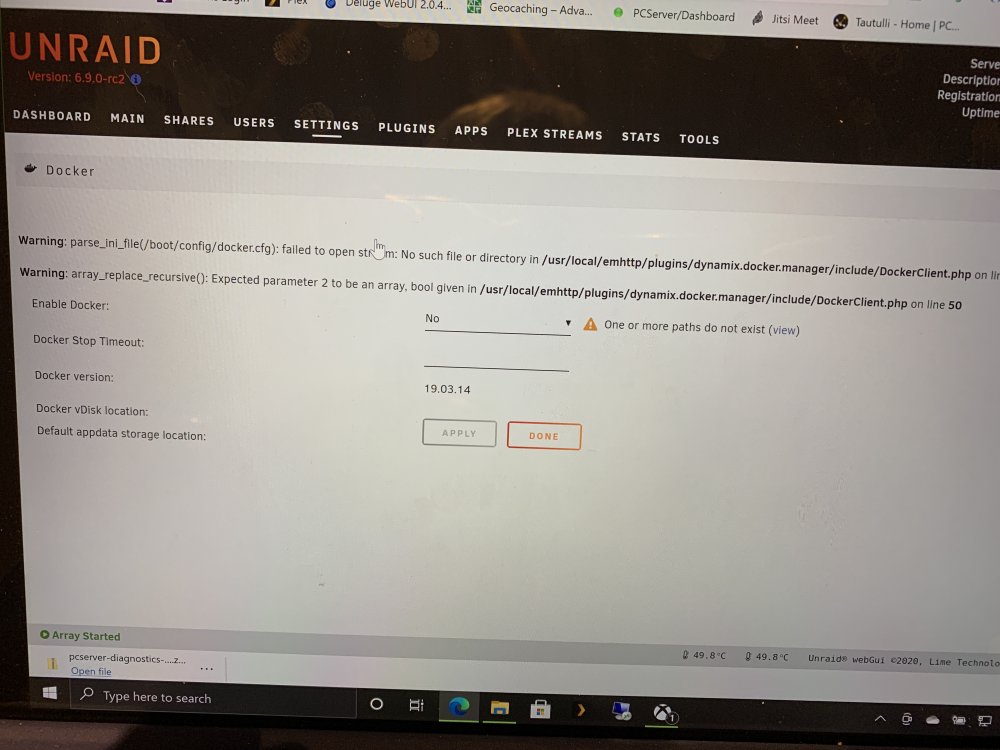
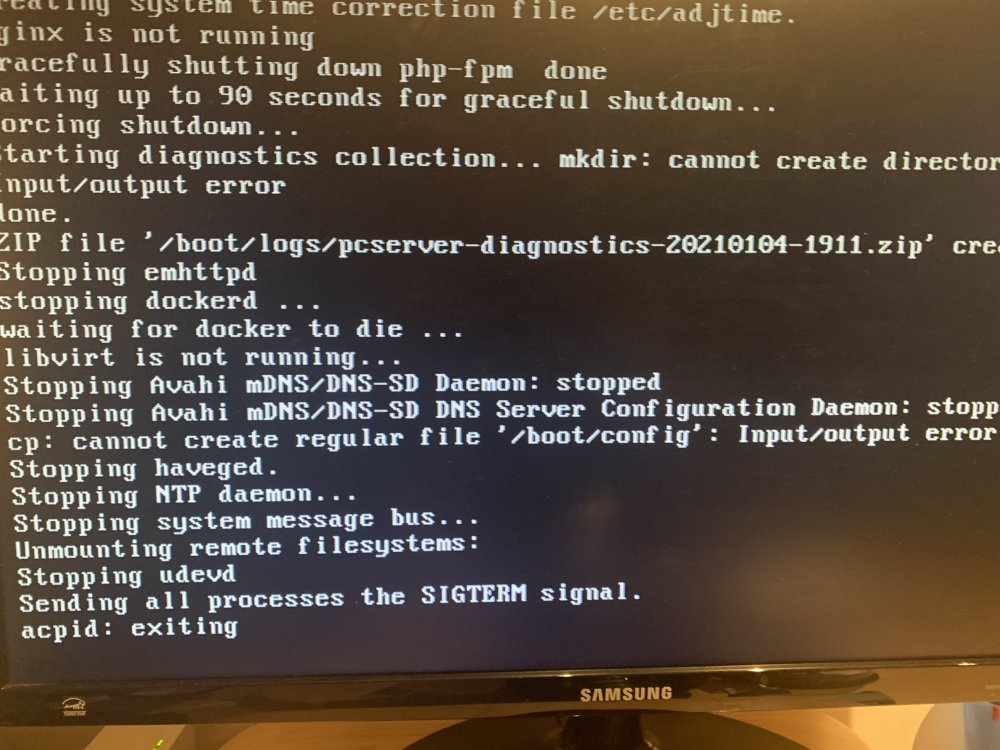
That’s the last log file I have. I thought there may be something in there. I took a screenshot of the computer shutting down when I had the nvme drive in. Looking at it says .zip file is not created? The photo is attached to this post.
The whole server behaved so strangely. It was almost like it could not find some settings or access a part of the system. It was exactly the same when I installed a second graphics card.
Could it be a power supply issue? I am just on the cusp of power demand from the psu and it behaves like this? I am clutching at straws.
Thanks for for taking the time.









unRaid Error : kernel: Buffer I/O error on dev sdb1, logical block 9959896, async page read
in General Support
Posted
Have done that already. Will try again though