
mkono87
-
Posts
197 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by mkono87
-
-
Trying this out for the first time. Im on 6.12.6. Only a few things are showing up but im also getting 503 errors. Could this be because of the version of Unraid, something changed?
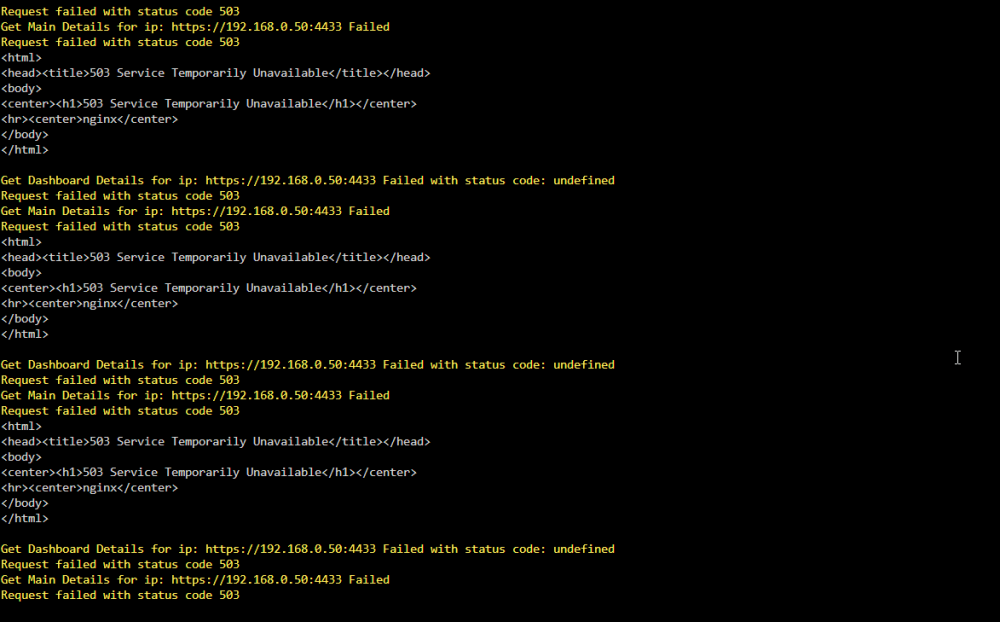
-
1 minute ago, trurl said:
Better to just do one at a time, if there are problems then doing both at once won't make things any better.
Correct but if I bought two that are 8tb when the largest I have now is 4tb how does that work?
-
5 hours ago, trurl said:
Replace disk1 but keep original disk1 with its contents in case of problems.
If I were to just go ahead and get two bigger drives one for parity and one for disk 1, whats the best method of attack? Replace Disk 1 and just the other drive as a 2nd parity then remove it the other parity when its completed rebuilding?
-
16 minutes ago, trurl said:
Click on each of your WD disks and add SMART attributes 1 and 200 for monitoring.
OKay done.
-
3 minutes ago, JorgeB said:
Both are logged as disk problems, I would try to replace disk1 first since that one looks worse, then if anymore read errors on parity replace it as well.
Unfortuantly I think this is a result of an unclean shutdown. If I replace disk 1 first, could I expect some lost files at this point?
-
Hoping for some advice on my next steps. Il be honest, Disk 1 has had a few read errors for a while and probably best to replace it at this point. Wondering about the Parity though. I have done a non-correcting check and then a correcting check. Also ran an extended smart check on both returning no errors.

Disk1_smart_test.txt nas-diagnostics-20231205-0846.zip parity_smart_test.txt
-
Does anyone use borg to backup their vms by just adding the folders in the Domains share while the vms are running? I know there is the vmbackup plugin but I dont believe that does any type of deduplication.
-
@sdubDo you shutdown your containers before backing up /mnt/user/appdata? If not, no issues have come from that? How is this the easier way to go vs the backup appdata plugin?
-
54 minutes ago, sdub said:
Looks like the root issue is in that '/root/.cache/borg' folder. If you open a shell into borg and browse to that folder, does everyhing appear normal? Could be that folder mapping is screwed up in your docker config.

It mapped in a subfolder of the repo folder. Is that fine? The cache folder on the host wasnt there so I created it but now when I try to init it says there is something already there.
-
Trying to initilize the local repo, I recieve a bunch of traceback errors, yet I still see files created in the folder.
9b90dcb83a73:/# borg init --encryption=none /mnt/borg-repository/ Local Exception Traceback (most recent call last): File "/usr/local/lib/python3.11/site-packages/borg/archiver.py", line 5324, in main exit_code = archiver.run(args) ^^^^^^^^^^^^^^^^^^ File "/usr/local/lib/python3.11/site-packages/borg/archiver.py", line 5255, in run return set_ec(func(args)) ^^^^^^^^^^ File "/usr/local/lib/python3.11/site-packages/borg/archiver.py", line 183, in wrapper return method(self, args, repository=repository, **kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/usr/local/lib/python3.11/site-packages/borg/archiver.py", line 290, in do_init with Cache(repository, key, manifest, warn_if_unencrypted=False): ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/usr/local/lib/python3.11/site-packages/borg/cache.py", line 387, in __new__ return local() ^^^^^^^ File "/usr/local/lib/python3.11/site-packages/borg/cache.py", line 378, in local return LocalCache(repository=repository, key=key, manifest=manifest, path=path, sync=sync, ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/usr/local/lib/python3.11/site-packages/borg/cache.py", line 478, in __init__ self.path = cache_dir(repository, path) ^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/usr/local/lib/python3.11/site-packages/borg/cache.py", line 229, in cache_dir return path or os.path.join(get_cache_dir(), repository.id_str) ^^^^^^^^^^^^^^^ File "/usr/local/lib/python3.11/site-packages/borg/helpers/fs.py", line 100, in get_cache_dir with SaveFile(cache_tag_fn, binary=True) as fd: File "/usr/local/lib/python3.11/site-packages/borg/platform/base.py", line 230, in __enter__ self.tmp_fd, self.tmp_fname = mkstemp_mode(prefix=self.tmp_prefix, suffix='.tmp', dir=self.dir, mode=0o666) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/usr/local/lib/python3.11/site-packages/borg/helpers/fs.py", line 408, in mkstemp_mode return _mkstemp_inner(dir, prefix, suffix, flags, output_type, mode) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/usr/local/lib/python3.11/site-packages/borg/helpers/fs.py", line 364, in _mkstemp_inner fd = _os.open(file, flags, mode) ^^^^^^^^^^^^^^^^^^^^^^^^^^^ FileNotFoundError: [Errno 2] No such file or directory: '/root/.cache/borg/CACHEDIR.TAG-uryrraek.tmp' Platform: Linux 9b90dcb83a73 6.1.49-Unraid #1 SMP PREEMPT_DYNAMIC Wed Aug 30 09:42:35 PDT 2023 x86_64 Linux: Unknown Linux Borg: 1.2.6 Python: CPython 3.11.5 msgpack: 1.0.5 fuse: llfuse 1.5.0 [pyfuse3,llfuse] PID: 65 CWD: / sys.argv: ['/usr/local/bin/borg', 'init', '--encryption=none', '/mnt/borg-repository/'] SSH_ORIGINAL_COMMAND: None -
11 hours ago, PeteL said:
I tested URL and it works correctly. Try to schedule new recording using different show name & time.
Do short test recording for 1-2 minutes using continuous method.
If you can please post container log including info when job is registered, arguments and post processing.
Also, please check recording log. You will find it on Jobs page. Each individual job name has it's own log. Click on the note icon left to the clock icon.
It should have a start date & time, end date & time and ffmpeg exit code
There could be different reasons for this issue.
What options are you trying to use for scheduled job?
Please ensure that both config & media folders are set correctly in the container template.
Also, check the appdata/rradio/temp folder and see are there any incomplete recorded files.
It is possible that ffnpeg stops recording because of incorrect folder permissions.
It seems to be working now. I have removed the schedules instead of editing them. Looked like worked after doing a min test.
-
10 hours ago, PeteL said:
If you could please share the URL you are trying to record from.
I need little more details what happens when you trying to record.
When we schedule repeating recording, by default each job can be triggered only once during a day. This is to prevent creating duplicates.
In this particular example job 0-4 was already triggered and executed. Hence, any subsequent attempt is aborted. I do not recommend triggering jobs directly from a dashboard, unless you want to test if recording will work. Then, you will have to create new scheduled job and go directly to dashboard and trigger job. Go to container log and see if the job was registered, ffmpeg command line arguments and post processing.
To get to dashboard
http://IPADDRESS:PORT/dashboard
Recordings are performed in temp folder
/appdata/rradio/temp
Please check this folder. It is possible that ffmpeg stopped recording at some point
I have seen the the ffmpeg line arguments before but nothing seem to record regardless. Il remove the scheduled recordings and try again. This is was only radio I have tried. https://bayshore-ais.leanstream.co/CISOFM-MP3?args=tunein_01
-
2023-07-01 08:51:13 [INFO] (Executing job 0-4)
2023-07-01 08:51:13 [INFO] (Job registered: True.)
2023-07-01 08:51:13 [INFO] (Aborting)I have a heck of a time trying to record shows. I cant see to find anymore errors. The radio station plays just fine in this app.
-
This is what I have come up with now.
i5-13500 14 Core
Gigabyte Z690 Aorus Elite AX DDR4 LGA1700
Kingston KC3000 1TB NVMe M.2
TeamGroup T-Force Vulcan 16GB(2x8) X2
Deepcool AK400 CPU cooler
Fractal Design Meshify 2 Case
I originally though of a Rosewill 4U case, but I know I want to update my desktop pc in the near future as well. I have considered taking a crack at virtualiziing it and passing through my gpu.
I also noticed my local shop has these KINGSTON NV2 1TB Gen 4x4 NVMe M.2 on sale, and curious if I should pick up 2 for a pool for something.
-
 1
1
-
-
19 hours ago, Lolight said:
Not quite sure of what kind of performance you have in mind.
Generally speaking, Intel is considered to be a more stable and efficient platform (C-states implementation).
Included in the chip Intel's iGPUs offer great transcoding performance while consuming very little electricity.
I can not see a compelling reason for AMD hardware in a Plex setup.
Any reason to use an i7 over an i5 besides more cores? Was looking at an i5-13500.
-
For the longest time when creating containers it used to show the live progress like it does when upgrading containers or plug-ins. Doesn't matter what browser I use it seems, it just freezes till it's done then shows the complete status. Is this an unraid change? Been like this for months just finally decided to ask about it.
-
7 hours ago, Lolight said:
What are your reasons for a need to switch to AMD and a stand-alone GPU?
Instead of upgrading to a more current Intel CPU with iGPU (Quicksync)?
Honestly, no real reason. I figured its a much better price/performace ratio. Is there anything you would suggest?
-
Finally, time to upgrade my little beast. Currently running an i3-6100 with a mini itx asrock server board as it was originally a freenas system. Im wanting to upgrade it with an am4 socket but I dont think I want to shell the money for a server board. Not sure its really necessary.
Here is what I am thinking and would love some advice.
*Edited to Intel system*
i5-13500 14 Core
Gigabyte Z690 Aorus Elite AX DDR4 LGA1700
Kingston KC3000 1TB NVMe M.2
TeamGroup T-Force Vulcan 16GB(2x8) X2
Deepcool AK400 CPU cooler
Fractal Design Meshify 2 Case
I was using quicksync for Plex transcoding. Not sure if I need to buy a cheap GPU for this build. I may be upgrading my desktop pc too which has a gtx 1070 in it so might be an option. Any ideas on a cheap gpu for transcoding would be nice
Im using the current power supply, 4x Red Drives, Cache SSD. The Samsung will become the cache.
-
For a few weeks now I have completely lost the gui and not sure why. I have been very busy so havent been able to attend to it till now. The container continues to run but when I try to access the gui the log seems to gives me api or php errors.
-
6 hours ago, JorgeB said:
They are again logged as disk errors, and since SMART is showing some issues I would replace that disk.
Oh weird, I thought there wasnt any issues as the test completed fine. I had a feeling it was time to replace this disk. I think it was the most used out of the entire array.
-
-
On 2/4/2023 at 7:11 AM, JorgeB said:
It's logged as a disk problem, run an extended SMART test on disk1.
Ran the extended and it completed without any issue. Last week parity check completed with 3 errors and yesterday with 0. But disk1 slowly creeps with errors, sitting at 293 so far.
-
On 1/29/2023 at 3:56 PM, trurl said:
Check connections on disk1, power and SATA, both ends, including splitters. Run another non-correcting parity check.
So I changed sata cables made sure everything was seated properly, I even went to the extent of rebuilding it. Still showing read errors and parity errors after non correcting check.
-
Received a notification this morning that there were read errors on Disk 1 (612). It looks as if it happened during a parity check. I'm not quite sure what the best steps to take are. Attached is my diagnostics, maybe you can spot and advise what I should do. Other than these notifications, the system is running normally without anything odd happening.
Thanks.






[Support] Djoss - Nginx Proxy Manager
in Docker Containers
Posted
I also get the 'Communication with the API failed, is NPM running correctly?' when trying to add a new ssl cert manually. If I try to generate it while adding the proxy host, I get internal error.