



mkono87
Members
-
Joined
-
Last visited
-
I recently changed my google password which wiped all my app passwords in which 2FA was using my email to send the code. I am now unable to long into any new devices including the web. Is there a way to obtain the recovery key or turn off 2FA temporarily?
-
I also get the 'Communication with the API failed, is NPM running correctly?' when trying to add a new ssl cert manually. If I try to generate it while adding the proxy host, I get internal error.
-
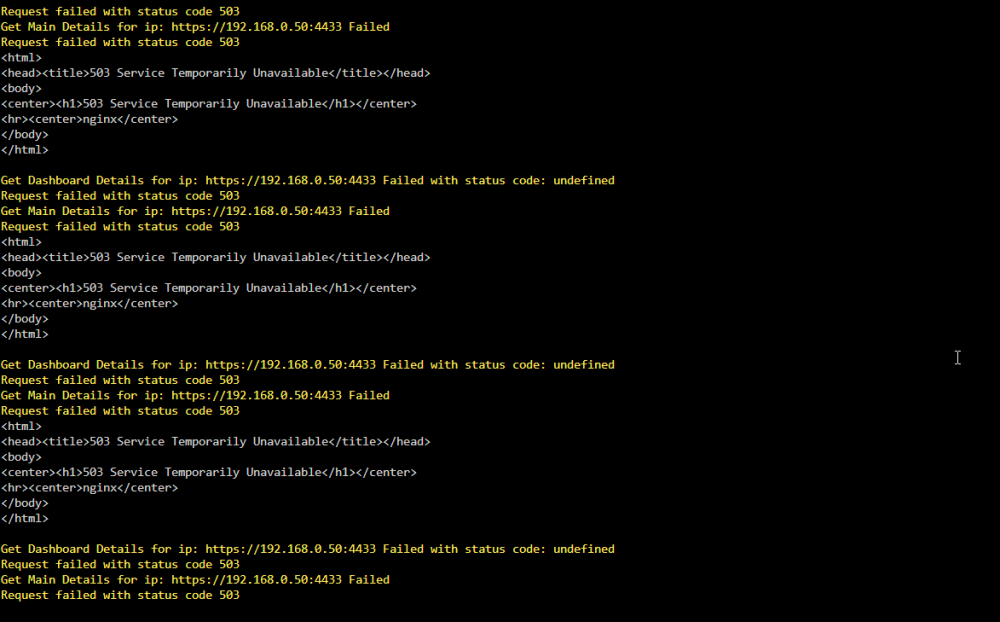
Trying this out for the first time. Im on 6.12.6. Only a few things are showing up but im also getting 503 errors. Could this be because of the version of Unraid, something changed?
-
Correct but if I bought two that are 8tb when the largest I have now is 4tb how does that work?
-
If I were to just go ahead and get two bigger drives one for parity and one for disk 1, whats the best method of attack? Replace Disk 1 and just the other drive as a 2nd parity then remove it the other parity when its completed rebuilding?
-
OKay done.
-
Unfortuantly I think this is a result of an unclean shutdown. If I replace disk 1 first, could I expect some lost files at this point?
-
Hoping for some advice on my next steps. Il be honest, Disk 1 has had a few read errors for a while and probably best to replace it at this point. Wondering about the Parity though. I have done a non-correcting check and then a correcting check. Also ran an extended smart check on both returning no errors. Disk1_smart_test.txt nas-diagnostics-20231205-0846.zip parity_smart_test.txt

-
Does anyone use borg to backup their vms by just adding the folders in the Domains share while the vms are running? I know there is the vmbackup plugin but I dont believe that does any type of deduplication.
-
@sdubDo you shutdown your containers before backing up /mnt/user/appdata? If not, no issues have come from that? How is this the easier way to go vs the backup appdata plugin?
-
It mapped in a subfolder of the repo folder. Is that fine? The cache folder on the host wasnt there so I created it but now when I try to init it says there is something already there.

-
Trying to initilize the local repo, I recieve a bunch of traceback errors, yet I still see files created in the folder. 9b90dcb83a73:/# borg init --encryption=none /mnt/borg-repository/ Local Exception Traceback (most recent call last): File "/usr/local/lib/python3.11/site-packages/borg/archiver.py", line 5324, in main exit_code = archiver.run(args) ^^^^^^^^^^^^^^^^^^ File "/usr/local/lib/python3.11/site-packages/borg/archiver.py", line 5255, in run return set_ec(func(args)) ^^^^^^^^^^ File "/usr/local/lib/python3.11/site-packages/borg/archiver.py", line 183, in wrapper return method(self, args, repository=repository, **kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/usr/local/lib/python3.11/site-packages/borg/archiver.py", line 290, in do_init with Cache(repository, key, manifest, warn_if_unencrypted=False): ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/usr/local/lib/python3.11/site-packages/borg/cache.py", line 387, in __new__ return local() ^^^^^^^ File "/usr/local/lib/python3.11/site-packages/borg/cache.py", line 378, in local return LocalCache(repository=repository, key=key, manifest=manifest, path=path, sync=sync, ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/usr/local/lib/python3.11/site-packages/borg/cache.py", line 478, in __init__ self.path = cache_dir(repository, path) ^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/usr/local/lib/python3.11/site-packages/borg/cache.py", line 229, in cache_dir return path or os.path.join(get_cache_dir(), repository.id_str) ^^^^^^^^^^^^^^^ File "/usr/local/lib/python3.11/site-packages/borg/helpers/fs.py", line 100, in get_cache_dir with SaveFile(cache_tag_fn, binary=True) as fd: File "/usr/local/lib/python3.11/site-packages/borg/platform/base.py", line 230, in __enter__ self.tmp_fd, self.tmp_fname = mkstemp_mode(prefix=self.tmp_prefix, suffix='.tmp', dir=self.dir, mode=0o666) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/usr/local/lib/python3.11/site-packages/borg/helpers/fs.py", line 408, in mkstemp_mode return _mkstemp_inner(dir, prefix, suffix, flags, output_type, mode) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/usr/local/lib/python3.11/site-packages/borg/helpers/fs.py", line 364, in _mkstemp_inner fd = _os.open(file, flags, mode) ^^^^^^^^^^^^^^^^^^^^^^^^^^^ FileNotFoundError: [Errno 2] No such file or directory: '/root/.cache/borg/CACHEDIR.TAG-uryrraek.tmp' Platform: Linux 9b90dcb83a73 6.1.49-Unraid #1 SMP PREEMPT_DYNAMIC Wed Aug 30 09:42:35 PDT 2023 x86_64 Linux: Unknown Linux Borg: 1.2.6 Python: CPython 3.11.5 msgpack: 1.0.5 fuse: llfuse 1.5.0 [pyfuse3,llfuse] PID: 65 CWD: / sys.argv: ['/usr/local/bin/borg', 'init', '--encryption=none', '/mnt/borg-repository/'] SSH_ORIGINAL_COMMAND: None
-
It seems to be working now. I have removed the schedules instead of editing them. Looked like worked after doing a min test.
-
I have seen the the ffmpeg line arguments before but nothing seem to record regardless. Il remove the scheduled recordings and try again. This is was only radio I have tried. https://bayshore-ais.leanstream.co/CISOFM-MP3?args=tunein_01
-
2023-07-01 08:51:13 [INFO] (Executing job 0-4) 2023-07-01 08:51:13 [INFO] (Job registered: True.) 2023-07-01 08:51:13 [INFO] (Aborting) I have a heck of a time trying to record shows. I cant see to find anymore errors. The radio station plays just fine in this app.




