




whitewlf
Members
-
Joined
-
Last visited
Everything posted by whitewlf
-
Is there any way to get the stable diffusion docker to save files as nobody:users instead of root:root? It's also not respecting UMASK, and saving as group un-writeable. Makes accessing images remotely a ronkin pain. UID 99 and GUID 100 and UMASK 002 variables are set, but do nothing at all.
-
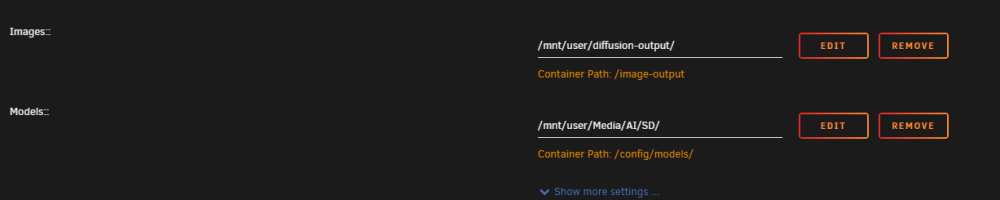
Not sure if this is what you are stumbling against, but, the script that this runs on does some voodoo when it starts. After you see it, you can understand it's usefulness and how to work with it. You just cannot work -against- it. Took a little snooping to figure it out on my own, but, it is probably on the git page as to how it works. (From my understanding) in order to keep a central point of storage between multiple installations/types of stable diffusion, it creates symlinks internal to the docker to point to each folder for common files, like models and output (and loras, vaes, embeddings, etc) I included a trimmed snippet below of the log output showing what gets associated to where in the 02 A111 installation which I am using: moving folder /config/02-sd-webui/webui/models/Stable-diffusion to /config/models/stable-diffusion removing folder /config/02-sd-webui/webui/models/Stable-diffusion and create symlink moving folder /config/02-sd-webui/webui/models/hypernetworks to /config/models/hypernetwork removing folder /config/02-sd-webui/webui/models/hypernetworks and create symlink moving folder /config/02-sd-webui/webui/models/Lora to /config/models/lora removing folder /config/02-sd-webui/webui/models/Lora and create symlink moving folder /config/02-sd-webui/webui/models/VAE to /config/models/vae removing folder /config/02-sd-webui/webui/models/VAE and create symlink moving folder /config/02-sd-webui/webui/embeddings to /config/models/embeddings removing folder /config/02-sd-webui/webui/embeddings and create symlink moving folder /config/02-sd-webui/webui/models/ESRGAN to /config/models/upscale removing folder /config/02-sd-webui/webui/models/ESRGAN and create symlink moving folder /config/02-sd-webui/webui/models/BLIP to /config/models/blip removing folder /config/02-sd-webui/webui/models/BLIP and create symlink moving folder /config/02-sd-webui/webui/models/Codeformer to /config/models/codeformer removing folder /config/02-sd-webui/webui/models/Codeformer and create symlink moving folder /config/02-sd-webui/webui/models/GFPGAN to /config/models/gfpgan removing folder /config/02-sd-webui/webui/models/GFPGAN and create symlink moving folder /config/02-sd-webui/webui/models/LDSR to /config/models/ldsr removing folder /config/02-sd-webui/webui/models/LDSR and create symlink moving folder /config/02-sd-webui/webui/models/ControlNet to /config/models/controlnet removing folder /config/02-sd-webui/webui/models/ControlNet and create symlink moving folder /config/02-sd-webui/webui/outputs to /config/outputs/02-sd-webui removing folder /config/02-sd-webui/webui/outputs and create symlink Run Stable-Diffusion-WebUI Also, I cannot remember if I added this, or, it is default, but, I docker forwarded the output to an array share, and the full models point to another array share point. Initially I thought it would be nice to keep checkpoints/etc on my cache-nvme but, I've been hoarding again and now have a full TB of models/loras/etc. Plus, I don't swap checkpoints often, I simply run dozens of prompts simultaneous like a lunatic. I do a lot of seed shopping, so the checkpoints just sit in the card, and loras are small, so there is no reason to burn the faster storage, for me. Plus, the share uses the array cache anyway.
-
I've had the looping happen a couple times now, hard to say what happened to start it. The first time, I thought it was after an unraid docker update, but, just a bit ago it happened while I was making images and tried to change the checkpoint... it simply stopped and gave me odd errors. I lost the log, but, it was about being unable to access date-named files corresponding to a change in ckpt in this folder "..appdata2/stable-diffusion/02-sd-webui/webui/config_states/" I tired restarting, and it just looped... taking forever to do so. Previously I had added/uncommented this to the parameters.txt file: --reinstall-xformers --reinstall-torch I then re-commented them after, so, I can only assume this is why it started looping after I tried restarting the container after the errors. And this alone fixed the looping, no folders deleted, etc, and no configs/extensions lost. Not sure this helps all, but, it seems to have worked for me twice now. Hope it fixes the issue at least for some. I do have a question: How did you get Forge installed on this docker? I haven't tried it yet on my desktop, but, all the word is it is much better for speed, etc, for the smaller cards. I'm getting about 1-5it/s for 512-1024 ranged images on current RTX2000-12G Note: I run unraid in a 2U E5-20core Xeon supermicro chassis, I recently got an RTX 2000 12GB unit off ebay, and it has been fantastic. It only burns about 60watts while churning images, and works well for plex transcode at the same time. While running SD on my desktop, RTX2080 8G, it pretty much eats my whole machine, can't play games, etc while its running, and, cant 'pause' the queue to do so. 400$ for a server GPU that sips power while munching images is a good deal. The 12G vs. 8G alone is a huge thing. Sadly no 24GB low pro is likely to ever appear, but, a 4U chassis and new server may happen at some point.
-
Q: Could a 4port SFP+ PCI card be used to provide connections (eg. SMB (or iscsi?) Workstation <-> Unraid Array) effectively, or, would it be better on an external switch? I have been pricing out switches to add to my lab/lan and the pricing is of course a major issue. Partly due to one 'requirement'; I want to add, which is 10gb networking to PC workstations. This is just for home/homelab, so going to the best mix of efficiency and 'lab' use for NetAdmin experiments and such. I happen to have access to some decent/limited gear for free, so, looking at the viability. Server is a 2U xeon SuperMicro, 12bay. Came with a 4 port SFP NIC and nice SAS Raid controller (in HBM sata split mode). Storage/use case is both common media server on unraid, some gameservers, but, also content creation uploads from workstations (eg. video streams for interim/stock/edit storage) So, lite archive and general storage of 2k/4k video for youtube content creation. Moving a 1-4g file over 1gb LAN is about 110mb/sec currently (sustained... ram and nvme cache work really well on unraid usually.) 10G should allow editing directly over net, though that isn't the primary idea.. unless it's really that good. We originally wired up dual cat6a copper runs to each workstation, but now looking at adding a fiber to them (only 3 runs). Original intent was 10g copper, but, fiber seems doable/better... and, cheaper, since we have the 10g fiber SFPs already... and 10G copper SFPs are just very expensive/hot/etc. A big managed unit with 4xSFP+ is a hard ask, the price gets very high, especially if needing some poe and other gig ports. One alternative is a smaller switch like the 4xsfp+ Microtik CRS305, and then whatever 12-16port gig switch with 8 or more PoE ports. (Couple waps, some cameras, then various 1g copper devices. Bonded 1g for WAN also likely to reach 2g+ later). So, the question is, if we saved a bit of $$ on the 10G switch and just used the 4xSFP+ directly into the unraid server, would that be significantly different than a separate switch. Almost all traffic is workstation <-> Unraid... not between workstations. Internet WAN is 1.2gbps Xfinity... which could be 2g soon enough, package deal depending. So, having the internet via the 10G link would be a bit nicer, vs. inet via 1g copper alongside the unraid 10G direct. Bit unsure how to bridge up inet over the 10G if using the direct to card method as well. (4x1G on sever as well of course).


