eruk2007
Members
-
Joined
-
Last visited
-
Aah right...seems like I misinterpreted a bit there, my bad. In that case the old Disk3 might not even be bad...gonna have to investigate that further and maybe return it to the Array at some point, thanks for clarifying that. Still not a bad thing that I bought the new HDD seeing that it was on Sale for about $80 for the 4TB and I needed to expand for a project in a few months anyway. So, new Disk3 now has a mountable FS after an actual xfs_repair run (I thought you were only supposed to execute an actual repair if the check came up with some sort of error message). Thanks for your help!
-
Here's the output of the xfs-check utility in unraid Maintenance Mode...doesn't seem to detect a whole lot, right? Phase 1 - find and verify superblock... Phase 2 - using internal log - zero log... ALERT: The filesystem has valuable metadata changes in a log which is being ignored because the -n option was used. Expect spurious inconsistencies which may be resolved by first mounting the filesystem to replay the log. - scan filesystem freespace and inode maps... sb_fdblocks 79808839, counted 71851136 - found root inode chunk Phase 3 - for each AG... - scan (but don't clear) agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 1 - agno = 2 - agno = 3 No modify flag set, skipping phase 5 Phase 6 - check inode connectivity... - traversing filesystem ... - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify link counts... No modify flag set, skipping filesystem flush and exiting.
-
Hey thanks for the reply. Makes total sense that it would just rebuild a corrupt filesystem...never thought of that...anyway: I attached a SMART-Report of old Disk3 that I downloaded before removing it from the system (possibly this was also pre-OS-Upgrade, not sure though). That's what you wanted from the drive being connected as an unassigned device, right? I determined the drive to be faulty because I saw the high number of reported read-errors and seek-errors along with the write-errors in syslog (sadly I didn't export that prior to reboot). None of my current drives show any SMART-Errors in the Dashboard and even old Disk3 didn't show anything in the Dashboard..."raw_read_error_rate" doesn't seem to be monitored by unraid. I also tried the xfs-repair on the emulated drive prior to drive-swap and it didn't find any problem (after all, the emmulated drive *was* mounted) and so I thought the filesystem not to be a problem...apparently that was wrong. Gonna try the xfs-check on the restored drive in a few moments... ST2000VN004-2E4164_Z521V7MX-20210920-1235.txt
-
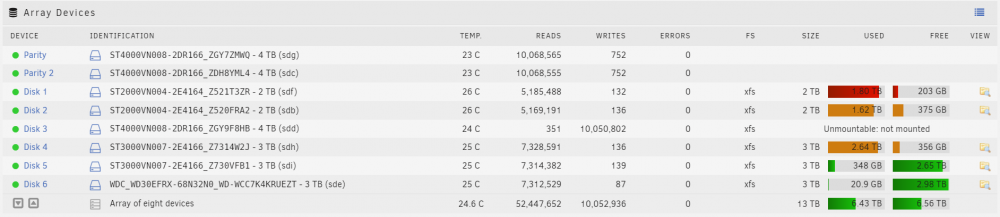
Hi guys, just stumbled upon something strange in unRAID, thought you might be able to help me out: A few days ago I logged into the WebGui for the first time after a while and found a drive disabled with write-errors. After some research I determined the drive to be faulty and ordered a new one to replace it (the drive sadly was out of waranty by a few months). This morning I then installed the new drive in the server and removed the old one. I then started the server, stopped the array and put the newly identified replacement drive in place of the failed drive using the dropdown. I then started the array and it began rebuilding the drive, so I left for work. Now that I returned, I see the rebuild has finished but Disk3 still shows "unmountable: not mounted" with the "Format unmountable drives" option lower down on the page. But on the "# of writes"-counter, you can clearly see that the drive had been written to a lot... (see attachment-image). I am pretty sure that following through with that format would make me basically lose any data that was on old Disk3, right? What went wrong here? Was it user error? If so, what did I do wrong? Can I fix it now? (old Disk3 still exists, and I think I should be able to pull the data from it if necessary, so not a huge loss...but still...what went wrong here?) A few details: - old Disk3 was 2TB in size, new Disk3 is 4TB. Shouldn't be a problem imo because that's a supported feature of unraid and it's the same size as the Parity drives now... - During the "Disk3 disabled" condition, I upgraded from unraid 6.8.3 to 6.9.2...maybe that wasn't the best thing to do but why would that have an impact like this? Is this even a possible side effect or am I just correlating things that don't have anything to do with each other at this point? gamingnas-diagnostics-20210923-0236.zip