





openam
Members
-
Joined
-
Last visited
Everything posted by openam
-
Thanks for the help. I copied the bz* files back over the ones in the root of the flash drive. It seemed to work, re-ran the parity check (it passed), and everything is back up and running! I'm making a backup of the flash drive now.
-
I took one when it came up with the upgrade to 7.2.3 from 7.2.0 (So it may be corrupt). I do have an old one from February 2025, but I'm not sure if that would be up to date enough. I had Backup/Restore Appdata running on it, but I believe those are on the array 😬. I copy the bz* files over and started up the machine. It's running, but I haven't started the array.
-
I download it from the link I found here. I have beyond compare are I take it these are the files you are talking about. The binary comparison says they are already the same. Should I just copy over it, and try it out again?
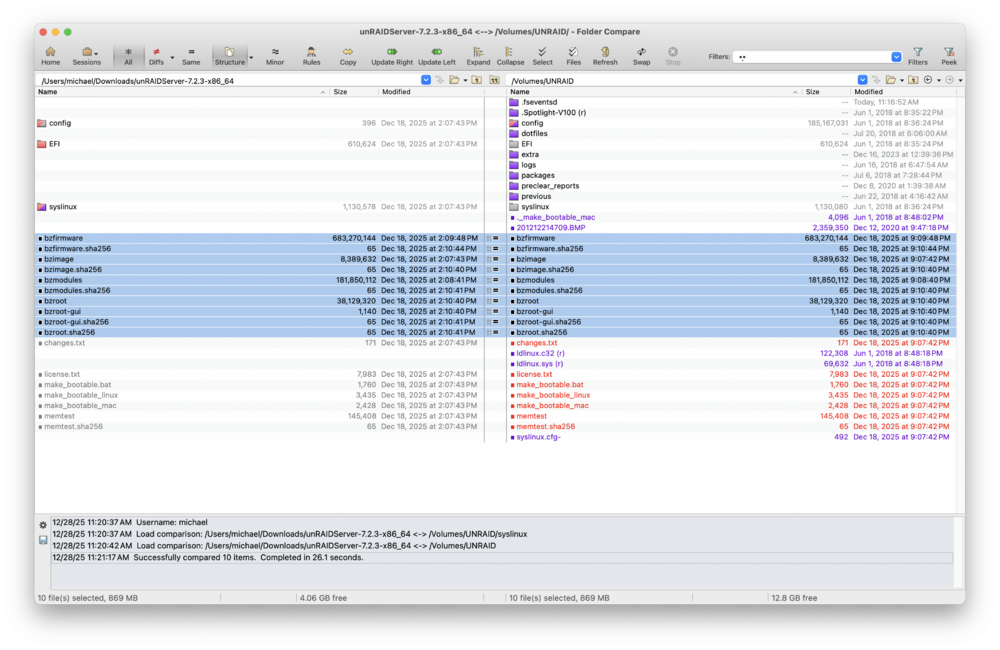
-
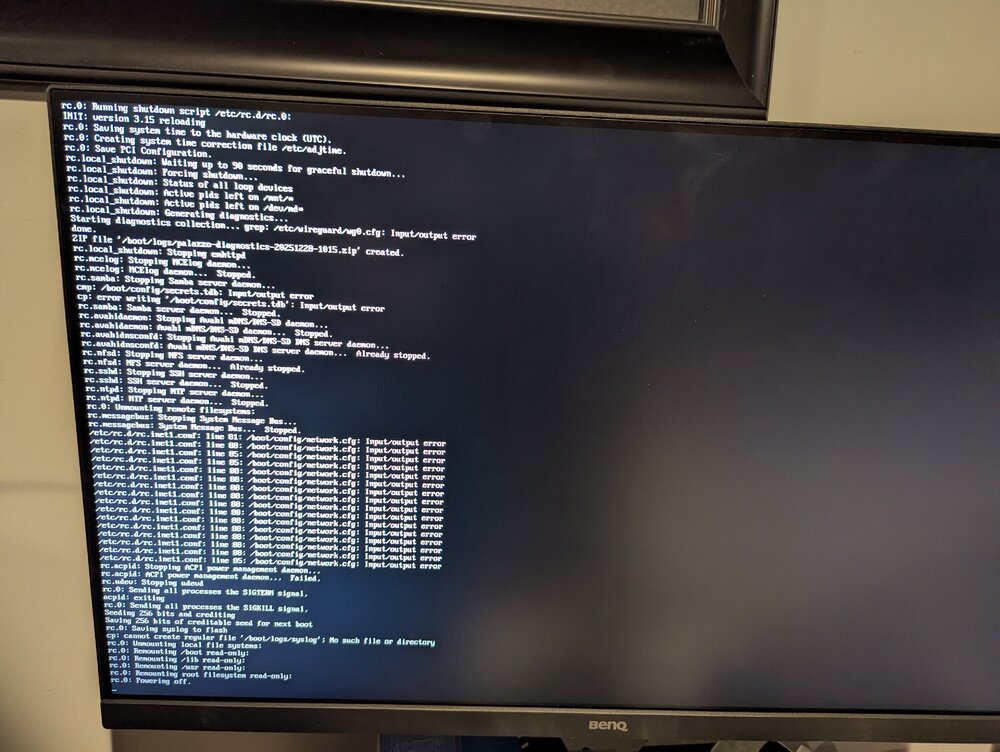
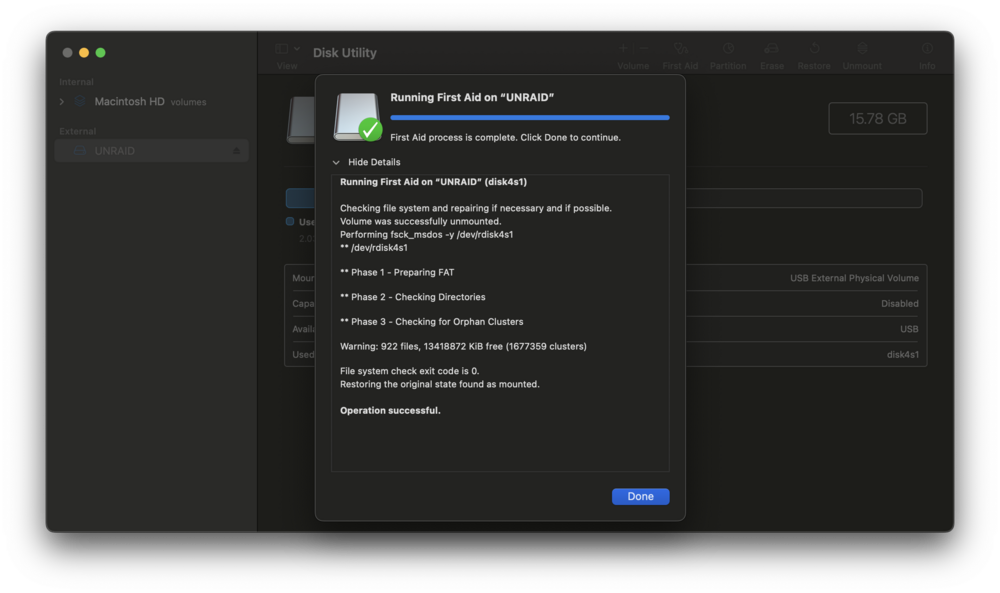
My unraid server locked up yesterday. I ended up re-seating the USB Flash drive, and got it to boot. I just left it up and running without starting the array all night. This morning I noticed the upgrade from 7.2.0 to 7.2.3, so I had it do the update and then started the reboot to finish update. It didn't seem to want to come up. That is when I went and saw this: I hit "enter" like it said to reboot the device. When it came back up it didn't find a boot drive, so I re-seated the USB flash drive again. It started up and I downloaded a backup of the flash drive. It then started to not respond again and I saw this: I couldn't reach it remotely so when I was logged in in locally I just shut it down Then looking at the info about replacing your flash drive I saw that I should try and run Mac Disk Utility to check for and repair errors. Here is what that showed. This is where I'm currently at. The machine is off. I have the USB here by my mac, I have ordered a new USB flash drive. Does it seem like the flash drive is really failing? Should I just wait for the new flash drive to show up, and migrate to that? Is there something else I should look at?
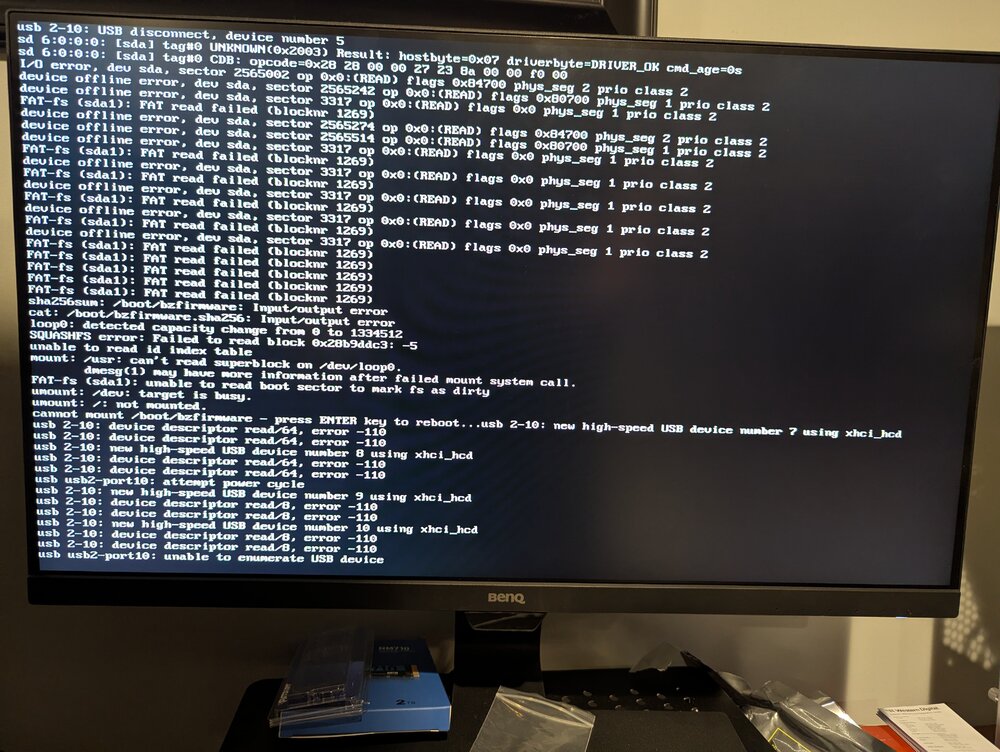
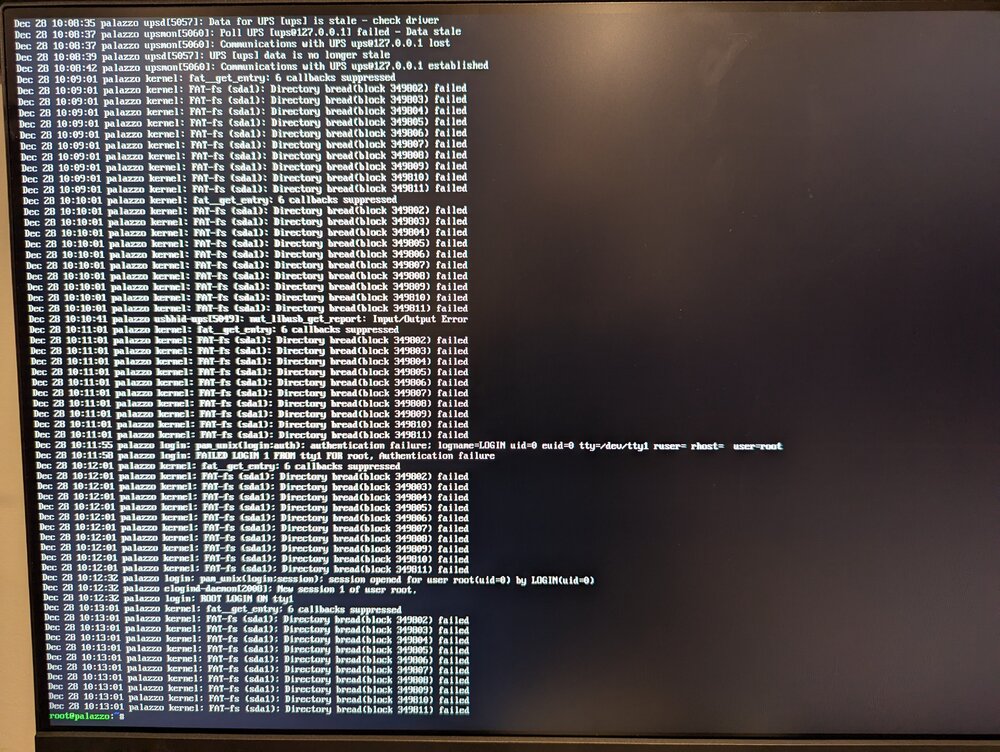
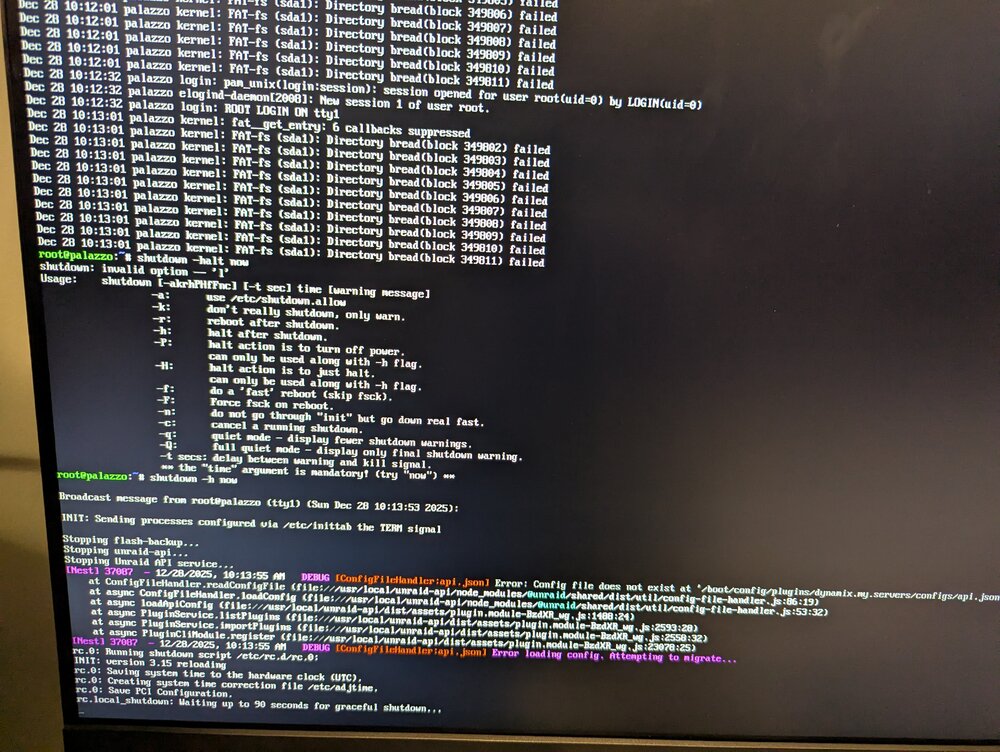
-
Thanks everyone. Everything is back up and running. Sync completed. Then I stopped the array, and restarted it not in maintenance mode.
-
I ended up hitting the Sync button because there was no progress showing that the rebuild was started. It appears to be running now.
-
I started in maintenance mode. How do I know if it's being re-built. It feels like I'm getting conflicting messages. This says it's being re-constructed But this says Sync to start Data-Rebuild Is there a difference between reconstructed and Data-Rebuild? Is this just a UI issue? Or do I need to hit the Sync button to actually get this to fix it?


-
Started the array, attaching diagnostics. Looking at disk5 it appears that there is stuff in there. palazzo-diagnostics-20251124-0853.zip
-
Well the SMART extended test is about 90% complete. What's the next steps assuming it finishes and says the disk is healthy, or bad? If it's bad I assume I pull it out and put a new one in and rebuild from parity. Do I also rebuild the same one from parity if it comes back as good?
-
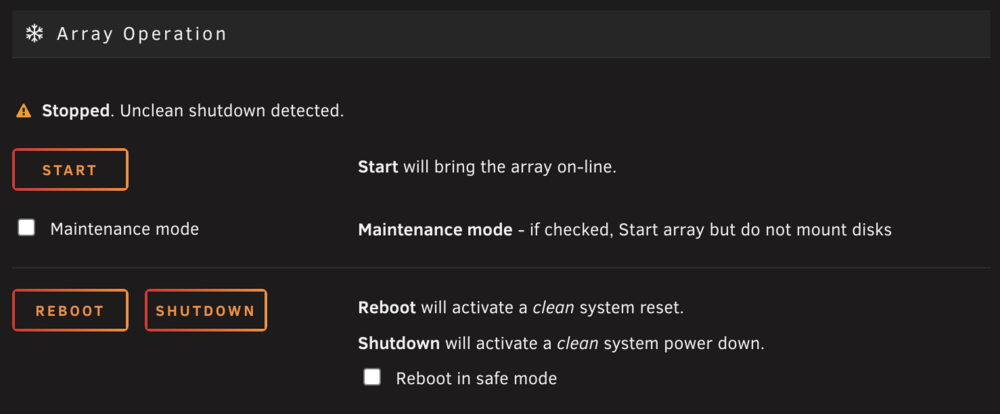
I just re-read your message. Sounds like 2 different ways to start parity check. 1 - Start array after unclean shutdown 2 - Explicitly start parity check (I assume this is after array is started) Is that what you mean? If so I originally just did the 1st option.
-
Now it doesn't say "Write corrections to parity" now. I don't remember what it said. But if it defaults to being checked like you said then I guess that's what I clicked. I guess the question is would it have been writing corrections still when it lost 3 drives with the HBA/SAS lost connection? I'm still waiting on the extended SMART test on that drive it currently says 50%. What should my next steps be?
-
Turned off the machine re-seated the card (only one pci slot). When I brought everything back up it show disk 5 is disabled? Ran SMART short self-test said completed without error. Took diagnostics, figured I should run the SMART extended self-test. Probably a bad idea. I guess that might take a day or two to complete. When it started yesterday it started to run parity check. Would that mess up the parity drive with the SAS device going offline like it did? Wondering what the best plan of action is here. Attached are the diagnostics from before the extended test being started. palazzo-diagnostics-20251123-1006.zip
-
The syslog just stops growing at 128M. I don't see any syslog.1, syslog.2, etc getting created.
-
UnRAID 7.2.0 The system locked up. I couldn't SSH into it, or get to it through the ui. I pushed the power button, and it looked like it got the sigterm, and sat there for a while. I looked like it hung on Stopping the UNRAID API. I just sat there for several minutes. I forced shutdown with holding the power button. After I tried to start it it said it was missing the USB drive. I ended up pull out the drive and reseating it. Then it found the drive. I have had that happen before. The difference this time is that when I started the array back up, (needed to do parity sync obviously). But when it tried to start I started getting a ton of errors in the logs about drive read errors. Nov 22 23:52:42 palazzo kernel: md: disk5 read error, sector=7897400 Nov 22 23:52:42 palazzo kernel: md: disk6 read error, sector=7897400 Nov 22 23:52:42 palazzo kernel: md: disk3 read error, sector=7897408 I have stopped docker process, and tried to stop the vm process. The UI is now unresponsive. I did have it generate a diagnostics while this was going on. I couldn't find an earlier diagnostics in /boot/logs from the last day or two. Am I good to just power off the computer, and try to re-seat the drives again? Or what should my next steps be here? ls -alh /var/log/syslog* && uptime -rw-r--r-- 1 root root 128M Nov 23 00:18 /var/log/syslog 00:18:09 up 29 min, 1 user, load average: 67.74, 67.20, 54.19 palazzo-diagnostics-20251122-2358.zip
-
So I just had something weird happen with this machine. A bunch of the dockers were stopped, and they wouldn't start. I disabled docker, and restarted it, and they seemed to all startup fine. I took some more diagnostics (attached). I just realized the last couple times I've tried to do this the UI won't serve them up as a download. I end up sshing in and copying them to a different network share to pull them down. palazzo-diagnostics-20240422-2013.zip
-
Here are the diagnostics, but it also just ran a check and says everything is good. edit: just noticed that was before my last post. Not sure why I didn't notice that before. palazzo-diagnostics-20240422-1416.zip

-
Thank you very much. It said it restored, but I see these warnings. Is this anything to worry about?
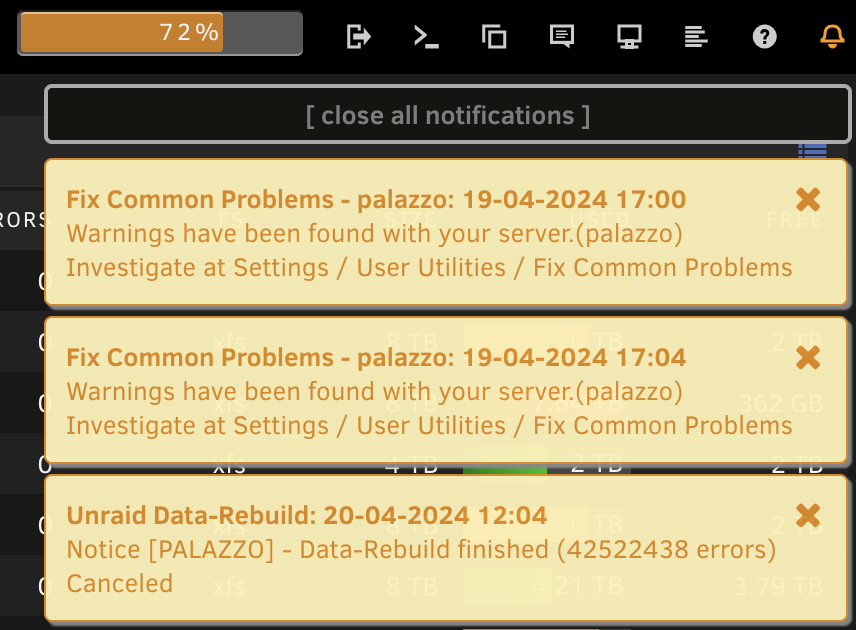
-
Well it's back up. Still says disk 5 is disabled. palazzo-diagnostics-20240418-1325.zip
-
I went to connect interact with a docker web application, and noticed it wasn't running. Logged into unRAID to find the array wasn't started. I had rebooting it a day or two ago. I ended up starting the array, and it started a parity check. I ended up looking at the uptime and it said 1 day 13 hours, which seems weird because that would have been like 6am Monday. I definitely don't remember rebooting it at that time. It seemed like the parity check started fine, and then all of a sudden it said disk 5 had issues. I see in the notifications it say 3 disk with read errors. Before I started the array all the disks were showing green on the status. Now disk 5 is showing as disabled. It wouldn't let me download diagnostics via the ui, I had to generate them via CLI, and transfer them to another NAS device, but they are attached here. The parity check paused. I assume I need to cancel it. Not sure what I need to do at that point. I tried looking through the diagnostics, and noticed several of the disks are missing smart reports. palazzo-diagnostics-20240417-2000.zip

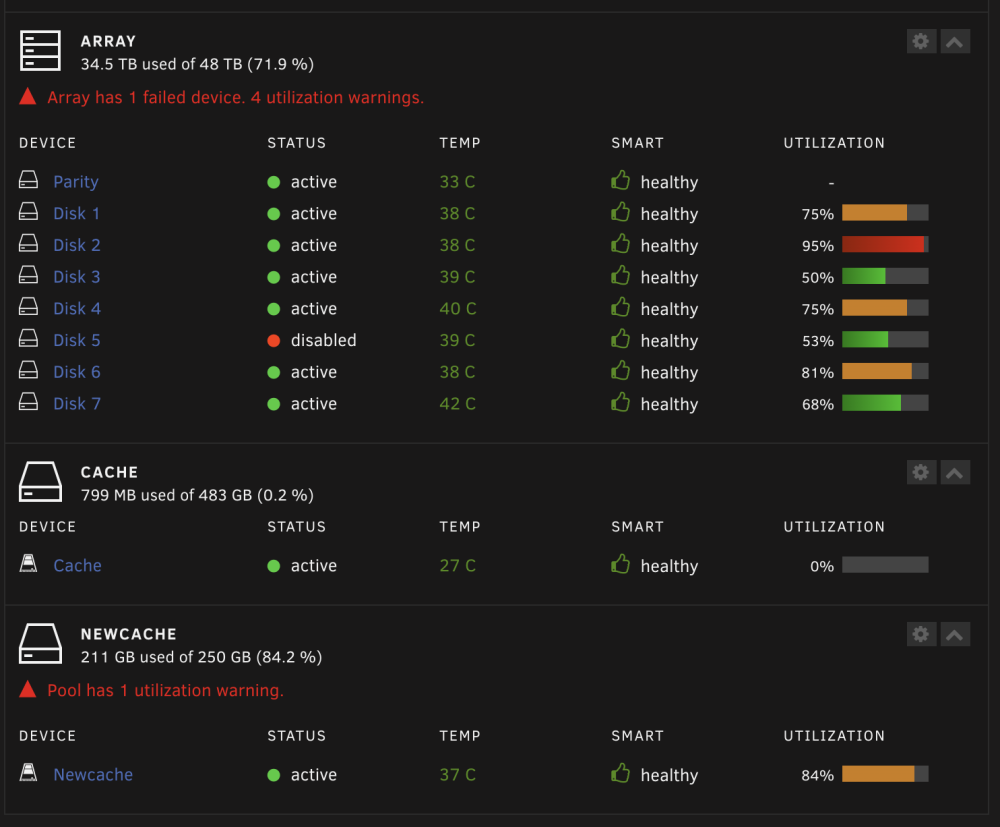
-
I do have deluge setup 😬. I have thought about swapping out for qbittorrent with vueTorrent, so maybe I'll try doing that over the holidays.
-
So I ended up creating a 2nd cache array, copying everything over to that I could. Most of my containers worked fine. I ended up having to restore the gitlab data from a backup, which I had running weekly. Then the original cache array that was btrfs was re-formatted into zfs. Things seem to be working fine so far.
-
So after I copy everything to a new cache do I just update the shares reference to use the new cache? Also I got these warnings, but that kind of makes sense since I'm coping from one to the other.

-
What's the best way to copy from the current pool, just targeting `/mnt/cache` and rysnc to a new drive?
-
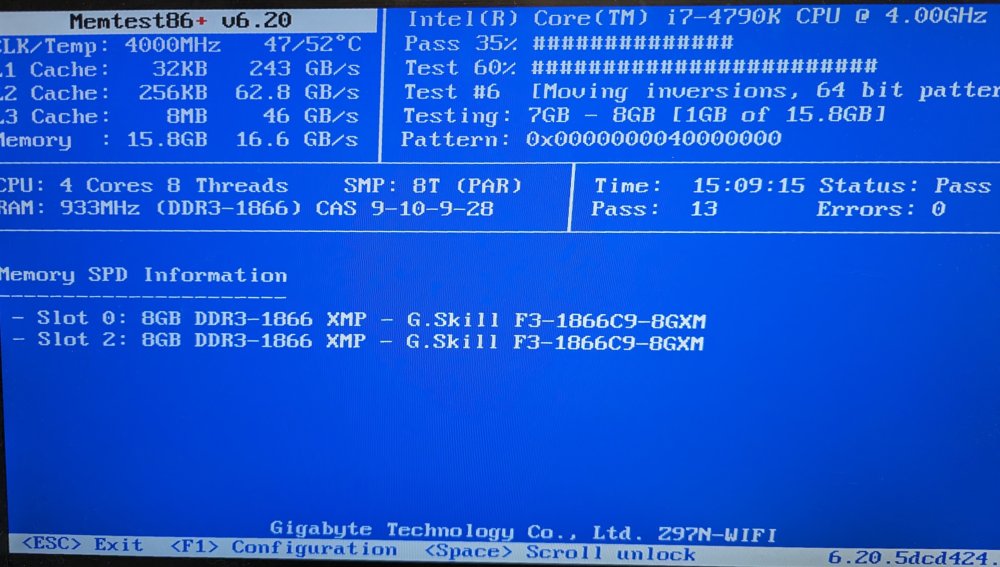
I ended up letting it run all night, and still shows no errors. I did order some cheap replacement memory sticks that should be here later tonight though. Would it be possible to just switch out my entire cache drive for another SSD? I have a smaller one sitting around that I could format and throw in. Then try to copy over important things from the old device if it'll let me using unassigned devices? Where is the configuration for the dockers all stored, by that I mean the setup of template configurations, not the appdata, or volume mappings.
-
I do not remember having memory problems in the past (which may mean I personally have them 😁). Another thing I did recently (about 1 week ago) was upgrade from 6.9.x to 6.12.x. Which makes me wonder if it's something like this guy was seeing, I have heard of people running memtest for many more hours than I did. Should I let in run all night?


















