

vw-kombi
-
Posts
436 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by vw-kombi
-
-
I just use tailscale to securely access stuff that are admin things just for me. Swag for me is for the others to access stuff. Play media etc.
-
I guess we just hope a future release/kernel fixes this.
-
I don't have that plugin myself......
I can cause these issues by running an rsync to an unassigned mounted nfs disk to another unraid server.
Any other time they dont happen.
Not a memtest issue.
-
Mine is also an rsync to an nfs share - an unassigned mounted drive on another unraid server.
-
Brand new mobo, cpu and ram today. Memtest done for a few hours before booted into it. Same issues in old one also.
-
I have a user script that backs up to a backup unraid server and when that runs :
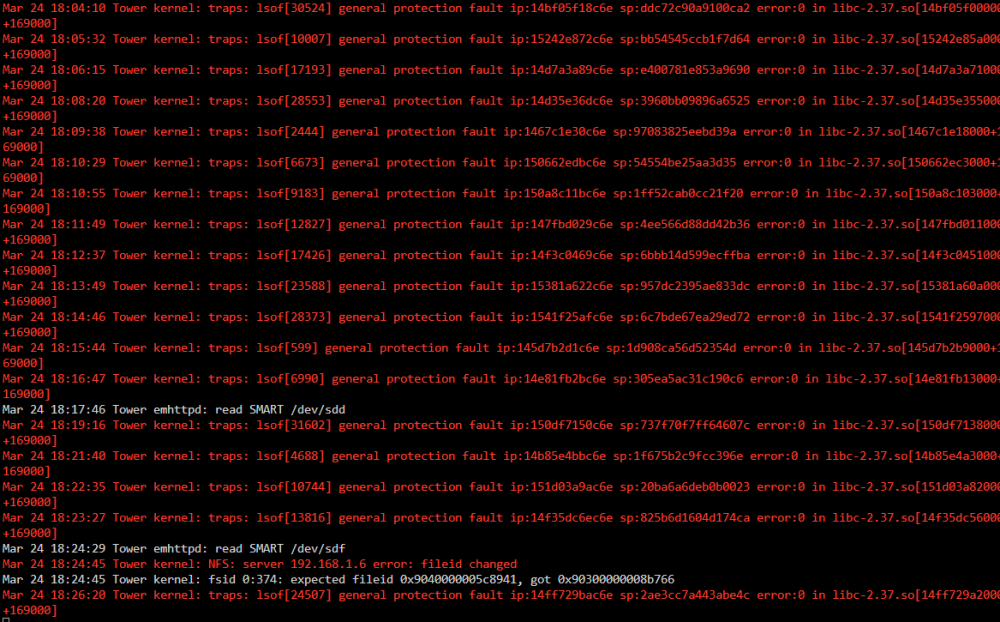
-
No lockup and/or reboots overnight.
I think this issue can be put to bed now.
-
Even the parity build is over 200 MB/sec instead of in the 180MB's range.
And the GPU conversions in tdarr are doing 650+ fps - before is was 20 ish on my one allocated cpu thread!!!!!
There is a load I have been missing since 2019 I guess.
-
8 minutes ago, SimonF said:
As ich777 said you need to install the gpu stats plugin + the corresponding driver package which you already have installed.

Oh - what a knob I am!!!!!!!
-
I have no idea how to do it any other way........

-
1 minute ago, ich777 said:
Did you configure the plugin in your Settings tab within Unraid?
I cant see anything in there for this :
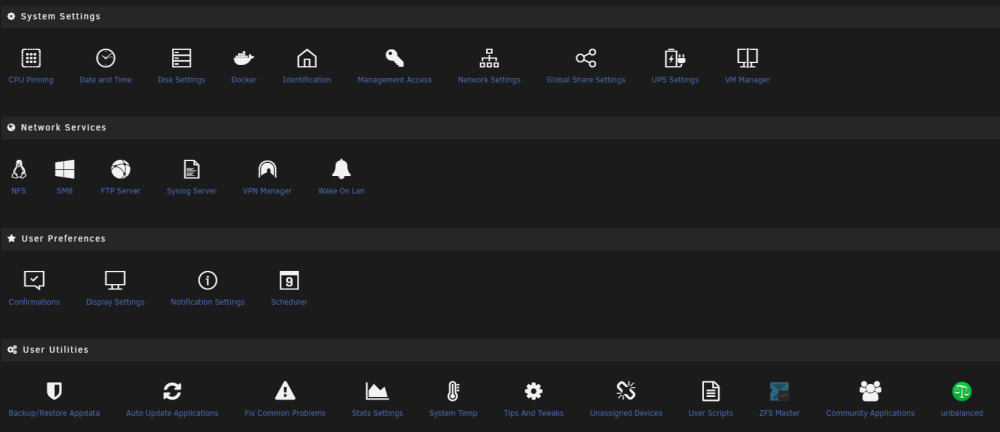
-
Hardware in.
Seems quite a bit snappier.
Enabled GPU transcoding in emby which is something I have not had before.
Started up everything, nothing strange as yet - fingers crossed!!!!!!
-
I only just installed this for the first time, as now I have a CPU that can do this (quicksync), but nothing on my dashboard like the pictures here.
-
Dead again on wakeup too - hardware install today - fingers crossed.
-
Well, I know I can break it by pushing more and more tdarr conversion threads at it - which finally caused the lockup/crash.....
Guess I was being greedy - So - new hardware will be installed tomorrow........
-
Well - it may be early days, but after the reboot without that realtek plugin. I had clean logs after a few hours, so in attempt to 'break' the system, I started a parity check. 6 hours later, still cleans logs, so I started up all my containers, and even the cpu killing tdarr with an extra CPU thread configured in tdarr to try and stress out the CPU's to breaking point. They have never seen this amount of activity before - and so far - clean logs, no lockups, no reboots :
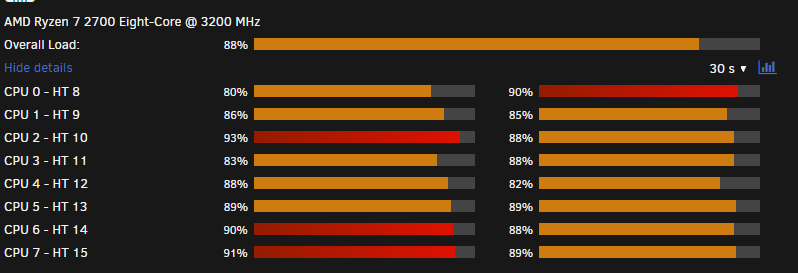
If I wake up to a healthy system, with a good parity check and no crashes/reboots, and a clean log, then I will be really pissed as there were no 'hardware issues' at all - with me having close to $500 of equipment sitting here that will be not needed. And all seemingly related to this realtek driver!
-
I am back to normal now - and took the time to remove all previous apps never going to be used again, and pinning the ones I want so its tidy.
I did another scan on the syslog file (attached most recent), and I found in the logs a load - r8168.
Now this is also something I did in Jan about the time I went to 6.12.x as it said to do it in fix common problems - even thought I have never had a network issue.
I have removed that plugin now and rebooted.
-
Just restored that folder, and ran common problems - none reported.
Working through pinned containers now.
-
Crashed again - took out dockers again - showing corrupted.
Deleted docker, this time changed to directory as I am willing to try anything.
Now app store is not remembering important ones as abole to be re-installed. want it as new.
Days like this you hate unraid.
-
seems to be all containers by lscr.io/linuxserver......
-
Im battling it now and it is worse - about two restarts / lockups a day.
I have new cpu, mobo and ram arriving today.
Last nights lockup also took out a docker (dead), so i did the thing to stop, delete, recreate and reinstall pins apps.
A reasonable selection have an issue stating :
Unable to find image 'lscr.io/linuxserver/radarr:latest' locally
docker: Error response from daemon: received unexpected HTTP status: 503 Service Temporarily Unavailable.
See 'docker run --help'. -
4 hours ago, Rollingsound514 said:
Thanks for the information,
So to move you just go into cache drive and select all your folders like appdata and then just choose a disk destination like "Disk 3", and then when you replace the cache drive do the opposite? Will Unraid keeps track of the files in the share being moved without actually using "Mover"? Everyone seems to say just use Mover but it's insanely slow, but this method you used just "feels" kinda of risky.Edit: Also, did the MOVE function delete the files from the destination automatically? Thanks
maybe disable mover while doing this - mover does not actually 'keep track' of files - just when it runs is moves stuff configured in shared flagged with cache to array. I have often moved this myself in between the mover times if re-aligning disks etc.
-
 1
1
-
-
I can report a successful parity sync - with all my usual stuff running.
Maybe the UPS connection really helps here.
Monitoring the log files and only these things to report :
Mar 15 10:09:49 Tower kernel: traps: lsof[5765] general protection fault ip:14c84ce0ec6e sp:9b917bd0db55c780 error:0 in libc-2.37.so[14c84cdf6000+169000]
Mar 15 12:40:09 Tower kernel: traps: lsof[25961] general protection fault ip:147649689c6e sp:ef64b13a79b916f4 error:0 in libc-2.37.so[147649671000+169000]
-
Was there a consensus on the cause of these from all these people here ?
I get two half way through parity check :
Mar 15 10:09:49 Tower kernel: traps: lsof[5765] general protection fault ip:14c84ce0ec6e sp:9b917bd0db55c780 error:0 in libc-2.37.so[14c84cdf6000+169000]
Mar 15 12:40:09 Tower kernel: traps: lsof[25961] general protection fault ip:147649689c6e sp:ef64b13a79b916f4 error:0 in libc-2.37.so[147649671000+169000]
Memtest was clear.
No lockups at this stage.






My first kernel panic ever - now on 6.12.4!
in General Support
Posted
Every rsync I can cause these. But the panic and crashes were hardware. I have a new cpu, Mobo and ram and no more crashes. The errors in ranch I have sort of living with now.