




flokason
Members
-
Joined
-
Last visited
Everything posted by flokason
-
Thank you, It works now I do though only have docker.img, no docker-xfs.img I had the strange problem that I could only install 2 dockers and nothing else, got this error when installing other dockers: Error: error pulling image configuration: download failed after attempts=6: received unexpected HTTP status: 500 Internal Server Error Found out my mnt/user/system was set to array not cache. I changed that to cache and I could install all the dockers and everything seams to be working I appreciate your help and made a small donation to you
-
Thanks for your reply cat /etc/resolve.conf gave me this: root@Tower:~# cat /etc/resolv.conf # Generated by dhcpcd from br0.dhcp domain localdomain nameserver 10.10.100.1 In photos you can see which dockers work and which dont. And also the error message when I try to start the ones that dont work
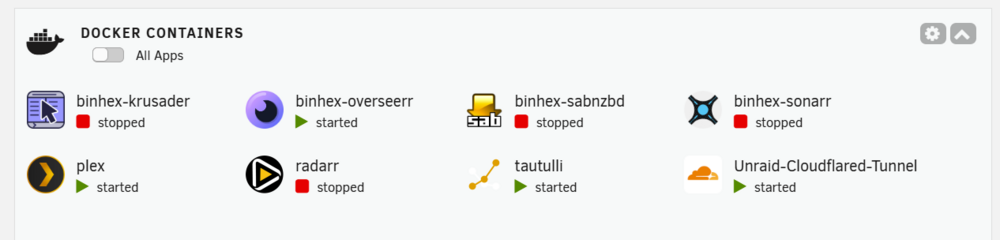
-
Docker is now working, but not fully some dockers work, some don't Everything is very strange new diagnostic here tower-diagnostics-20250205-2338.zip
-
Had a problem, plex stopped working Decided to reboot. So why not update to 7.0 At first I could not start they array due to some cachee configuration issue. I then got it started, but doker wont start Any help well appreciated tower-diagnostics-20250205-2304.zip
-
Thank you for the help Yes that activity is no more, it looks normal now I will look up that pool monitoring, thank you
-
Thank you JorgeB I would appreciate any advice so I can prevent this happening again, and perhaps knowing how to fix it if it happens again Best regards tower-diagnostics-20240330-1052.zip
-
I got kind of depressed, google something Though I should delete everything from both of my cache drives and then restore it with appdata backup Did those commands shown on screenshot Dockers started to work And hevy read/write on my cahce drive I have literally know idea what it happening
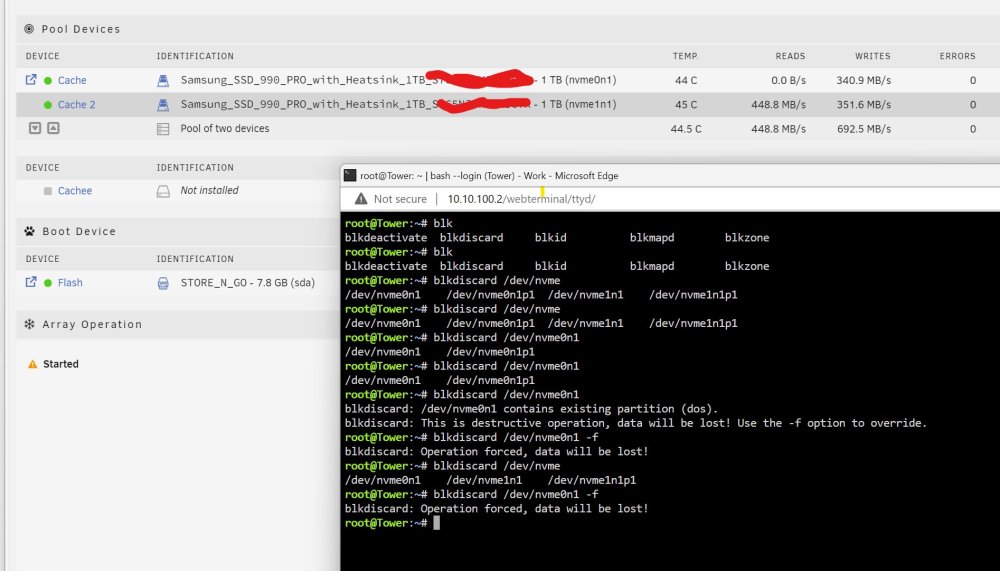
-
I think I have to format and start from scratch on my cahce drives root@Tower:~# btrfs dev stats /mnt/cache [/dev/nvme0n1p1].write_io_errs 296591154 [/dev/nvme0n1p1].read_io_errs 454910 [/dev/nvme0n1p1].flush_io_errs 1525783 [/dev/nvme0n1p1].corruption_errs 16434475 [/dev/nvme0n1p1].generation_errs 13247 [/dev/nvme1n1p1].write_io_errs 0 [/dev/nvme1n1p1].read_io_errs 0 [/dev/nvme1n1p1].flush_io_errs 0 [/dev/nvme1n1p1].corruption_errs 0 [/dev/nvme1n1p1].generation_errs 0
-
I do have the appdata backup plugin and backed up last time 25th of Mars Should I restore that?
-
I can only do it on Cache, not Cache 2 (they are mirror) I get this: [1/7] checking root items [2/7] checking extents [3/7] checking free space tree [4/7] checking fs roots [5/7] checking only csums items (without verifying data) [6/7] checking root refs [7/7] checking quota groups skipped (not enabled on this FS) Opening filesystem to check... Checking filesystem on /dev/nvme0n1p1 UUID: 7928d4a8-c447-4027-8952-2e27c43e51a9 found 511549218816 bytes used, no error found total csum bytes: 401640012 total tree bytes: 1649328128 total fs tree bytes: 993787904 total extent tree bytes: 166559744 btree space waste bytes: 372308360 file data blocks allocated: 1470746066944 referenced 495950946304
-
Like topic says, I updated from 6.12.8 to 6.12.9 and now I get this message on my dockers: Docker Service failed to start. Attached is my diognostics I would appreciate all help tower-diagnostics-20240329-2118.zip
-
Thank you that worked, Now forexample Dockers don't work But I do have access to a weeks old backup of my old flash drive. Do I gain anything on recreating my usb flashdrive from that backup?
-
Thanks for your help Should I just click "delete pool". And then I can start the array up again
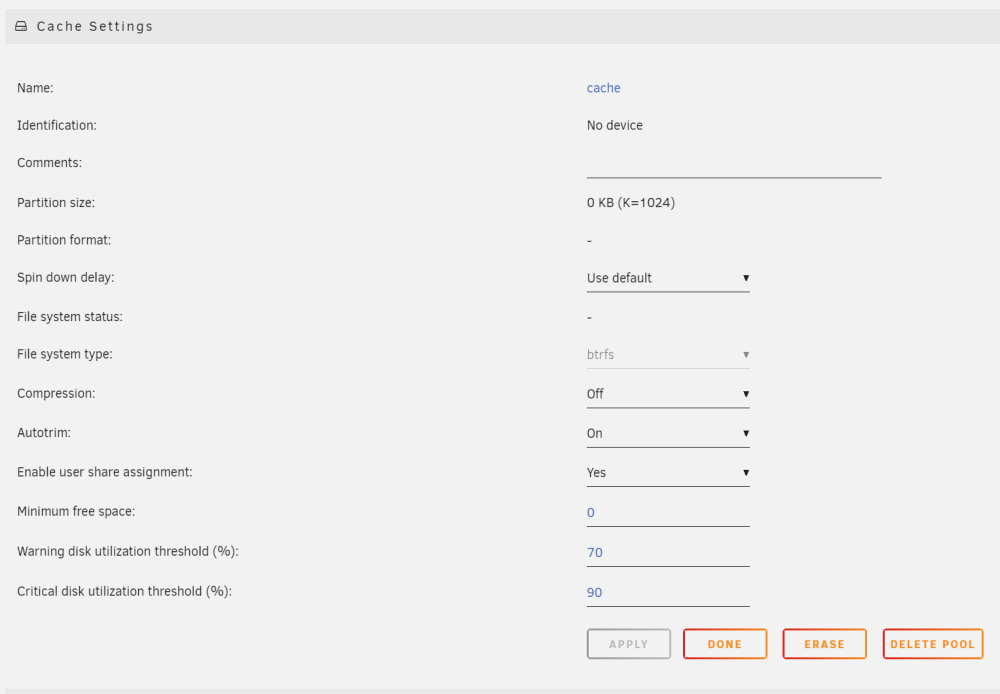
-
Well that does sound good, I can't imagine that something crucial was on it So what should I do now. That is, how do I start my array without it correctly Thank you
-
Thanks for your replys I checked BIOS, did not see the drive. Took the drive out, in again. Power on, did not see in the BIOS There has been for some time 1 error on it in SMART, don't remember which one. I kind of thought it was no big deal. So if this drive is dead, what are we talking about. Can I restore everything without it? I think I was using it as cache for every 24 hours
-
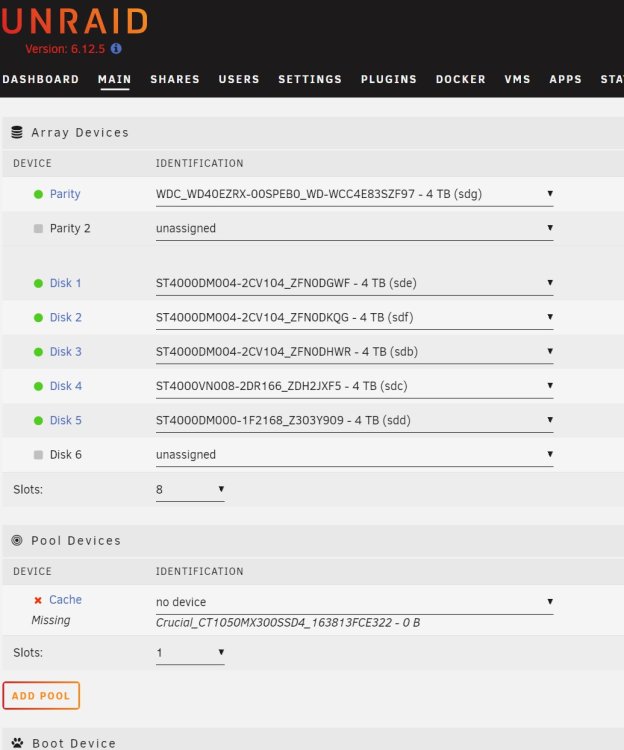
So my usb flash drive died. And all my backups of it are on on my array, and encrypted rclone gdrive I was able to DMDE to restore my config file, or hopefully all of it. So I made a new USB drive with unraid, and c/p my recovered config file to the new USB I have gotten my licence to work on the new USB drive But it says my cache drive is missing. It is a 1TB m2 SSD. So there are no cables to connect/reconnect Now I am a afraid to do something wrong so destroy my data. So I will appreciate all help tower-diagnostics-20231215-1737.zip
-
Just wanted to share my share experience I've been running Unraid for many years, and mostly SMB has worked without problems Tonight however, my work laptop was unable to access my smb share. However my unraid virtual win10 machine could, and also my gf laptop I went through most of the tips, and the one that worked was going to windows credentials. I saw \\tower there with my work laptop credentials for some reasons I deleted it, and then when I tried to access my smb drive I had to set in user and password (which I thing is a bit strange since I don't think you should need user&pass for that access, but anyway) I entered my unraid user and password, and then it finally worked So thanks to the one that talked about the windows credentials
-
I have been trying to get inter HW transcoding to work for the past months without success. I have the Intel 8700k Gigabyte HD3 Z370 motherboard Unraid 6.6.5 In Plex, extra parameters, I have this line: My go file: My syslinux file has this: when I list directories in the path /dev/dri I have these: I do have a lifetime plex pass I have it ticked "use hardware acceleration when available" in the Plex settings. But still no hardware transcoding. Here is the error from the Plex logs: If anyone could help me it would be greatly appreciated edit: I think I might not be using the linuxserver.io docker. I think I have the official unraid docker, this is what says in the repistory: plexinc/pms-docker So perhaps this question doesn't belong here, but I hope I get some answers, maybe I should post it somewhere else
-
I fixed the problem regarding: "Import failed, path does not exist or is not accessible by Radarr: /data/complete/movies/ xxxxxxxxxxxxxxx" It was previous downloads via sabnzdb somehow telling radarr to check on them (or something) What I did was delete/purge nzb files from SABnzdb and then this error log stopped The /movie/movie error seems to be gone, hopefully it doesn't start over again Thank you again for quick replies
-
Thanks for a quick reply I checked your advice, but not sure if it helps me, see below: Here is when I try to add "any movie" Here is when I go to "Bulk Import Movies": Nowhere is /movies/movies to be found Should I be looking in some other settings? I only have sabnzdb, so I don't have deluge My settings are (Sickrage included, these are the 3 dockers that do every downloading for me) My root folder in Sickrage is /media/TV Shows My root folder in Radarr is just /media as it is mapped to /media/movies If you have further advices then it would be greatly appreciated ps. I just added manually a movie, and everything worked, but this problem with /movies/movies, seems to come at a random time, perhaps when the program itself adds a new movie Here is my catagories in sabnzdb: When downloaded, sabnzdb unrars the movie from /data/incomplete to /data/complete/movies From there radarr moves the file to /media Like I said earlier, when manually added, there is no problem

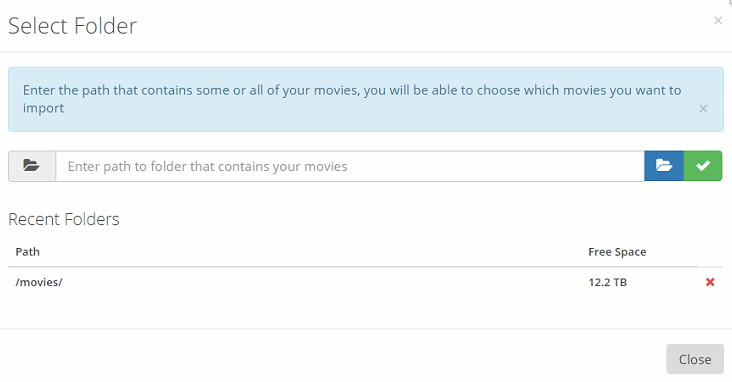

-
I've got a problem, I recently changed my download paths, as my original setup was flawed ( It just kind of worked so I didn't bother to fix it) So I was trying to have a proper folder structure, and here is my hosts paths: Rootpath in Radarr was also set as /data/download/complete/movies. So I deleted my whole library, went to "bulk import movies" and deleted the old root path. I set the root path as /movies. Then I have bulk imported all my movies back, and they do go to /movies as they should. But when ever something is added, it goes to /movies/movies and I get this error message: I can't find anywhere in the settings that I am pointing to the directory /Movies/movies. So then I go to "movie editor", and change those few to /movies, then a day later, I will have about 5 new movies with the root directory /movies/movies. Then another thing, aperently it somehow remembers the old root directory and I get endless of this error in the logs: Not strange since this folder does not exist, but it should not be checking there, it should just check /movies. So I have these two root/paths problems Any help would be greatly appreciated









