




SLRist
Members
-
Joined
-
Last visited
Everything posted by SLRist
-
Just thought I should update the status of this issue - it seems that saved Windows credentials were causing the issue. I deleted these using Control Panel / Credential Manager / Windows Credentials (Windows 10) and at the top, where server credentials are listed, simply clicked on the UNRAID server concerned and selected 'Remove' Once I had done this, all the shares under that server were once more browsable under Windows Explorer. This works even with NetBIOS disabled under SMB settings.
-
Yes, I know I have a UPS issue - it's an ancient APC with a network card in the back, and I think it's just responding too slowly across multiple unraid servers. Not really sure how to diagnose it. Other than that - yes, it's just basic NAS sharing - no containers or VMs or plugins installed. I did a memtest when I installed the RAM. No errors detected.
-
I've been waiting all day for a single 60GB file to copy over to my otherwise empty 2TB cache drive on my unRAID 6.11.5 server (8GB RAM installed - nothing but file sharing enabled). It's going at about 1MB/s (and it is going to the cache drive and not the array, as I can see it writing to the cache drive). Dashboard says that RAM is only about 23% used. However, the log is full of memory errors. Any idea what might be going on? Diagnostics file attached. Jan 15 21:37:48 UNRAID-02 nginx: 2023/01/15 21:37:48 [crit] 1250#1250: ngx_slab_alloc() failed: no memory Jan 15 21:37:48 UNRAID-02 nginx: 2023/01/15 21:37:48 [error] 1250#1250: shpool alloc failed Jan 15 21:37:48 UNRAID-02 nginx: 2023/01/15 21:37:48 [error] 1250#1250: nchan: Out of shared memory while allocating message of size 7997. Increase nchan_max_reserved_memory. Jan 15 21:37:48 UNRAID-02 nginx: 2023/01/15 21:37:48 [error] 1250#1250: *1052152 nchan: error publishing message (HTTP status code 500), client: unix:, server: , request: "POST /pub/devices?buffer_length=1 HTTP/1.1", host: "localhost" Jan 15 21:37:48 UNRAID-02 nginx: 2023/01/15 21:37:48 [error] 1250#1250: MEMSTORE:00: can't create shared message for channel /devices Jan 15 21:37:49 UNRAID-02 nginx: 2023/01/15 21:37:49 [crit] 1250#1250: ngx_slab_alloc() failed: no memory Jan 15 21:37:49 UNRAID-02 nginx: 2023/01/15 21:37:49 [error] 1250#1250: shpool alloc failed Jan 15 21:37:49 UNRAID-02 nginx: 2023/01/15 21:37:49 [error] 1250#1250: nchan: Out of shared memory while allocating message of size 7997. Increase nchan_max_reserved_memory. Jan 15 21:37:49 UNRAID-02 nginx: 2023/01/15 21:37:49 [error] 1250#1250: *1052158 nchan: error publishing message (HTTP status code 500), client: unix:, server: , request: "POST /pub/devices?buffer_length=1 HTTP/1.1", host: "localhost" Jan 15 21:37:49 UNRAID-02 nginx: 2023/01/15 21:37:49 [error] 1250#1250: MEMSTORE:00: can't create shared message for channel /devices Jan 15 21:37:50 UNRAID-02 nginx: 2023/01/15 21:37:50 [crit] 1250#1250: ngx_slab_alloc() failed: no memory Jan 15 21:37:50 UNRAID-02 nginx: 2023/01/15 21:37:50 [error] 1250#1250: shpool alloc failed Jan 15 21:37:50 UNRAID-02 nginx: 2023/01/15 21:37:50 [error] 1250#1250: nchan: Out of shared memory while allocating message of size 7997. Increase nchan_max_reserved_memory. Jan 15 21:37:50 UNRAID-02 nginx: 2023/01/15 21:37:50 [error] 1250#1250: *1052169 nchan: error publishing message (HTTP status code 500), client: unix:, server: , request: "POST /pub/devices?buffer_length=1 HTTP/1.1", host: "localhost" Jan 15 21:37:50 UNRAID-02 nginx: 2023/01/15 21:37:50 [error] 1250#1250: MEMSTORE:00: can't create shared message for channel /devices unraid-02-diagnostics-20230116-0251.zip
-
Many thanks. Actually, I do have an old Dune media streamer that still needs SMBv1, but I will take a look through your suggested post and see what I can do. I might need to just ditch that media player and replace it with another Zappiti.
-
I should say at the outset that I've already tried this fix, but it didn't fix my issue: All of my 5 unRAID servers are set up the same - just sharing video ISO files - no VMs or Dockers. All are running v6.11.5. All running on HP Proliant Microservers (N36L, N40L etc.) with 8GB RAM installed. I can see all servers listed in Windows (10) Explorer. Windows 10 has SMBv1 enabled. For three of them (UNRAID-02, UNRAID-03, UNRAID-04), I can click on that server and see and access all the shares - e.g: \\UNRAID-02 On the two problematic servers (UNRAID-01, UNRAID-05) - when I click on the server name in Windows Explorer, after some delay I get the following error message, and clicking [Diagnose] reveals no identification of the problem. These are some relevant settings I have on one of the problematic servers. As far as I can see, these settings are all the same as on the other machines whose shares work as expected. All shares have SMB security set to 'Public'. Any suggestions what might be wrong? Example share:
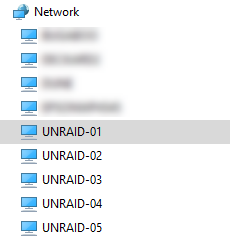

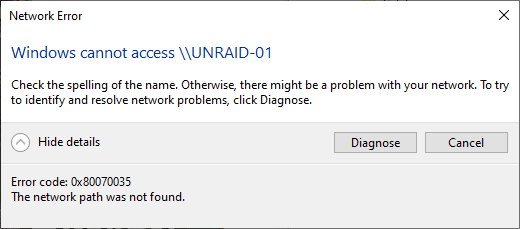
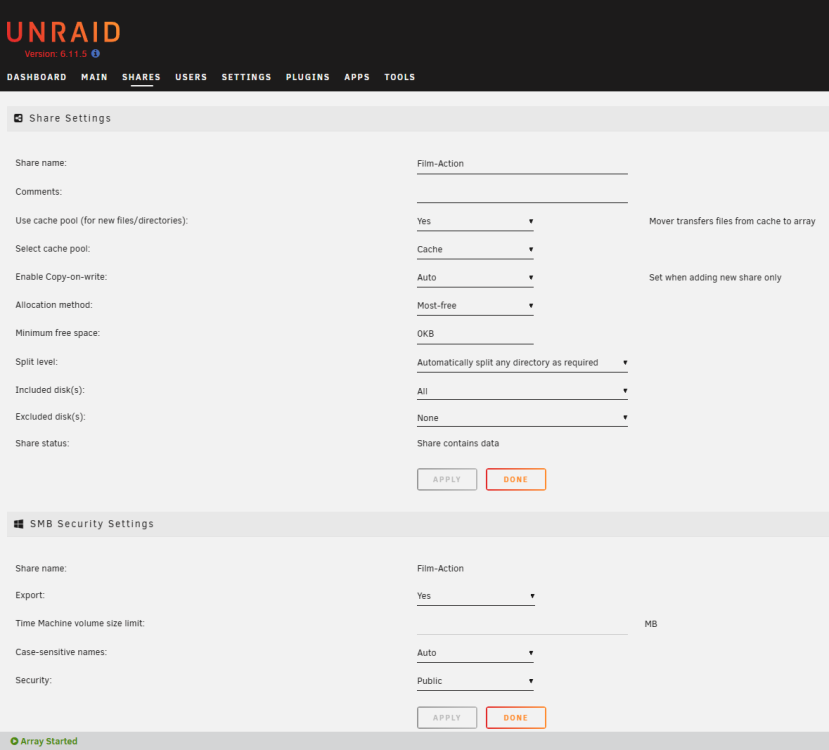
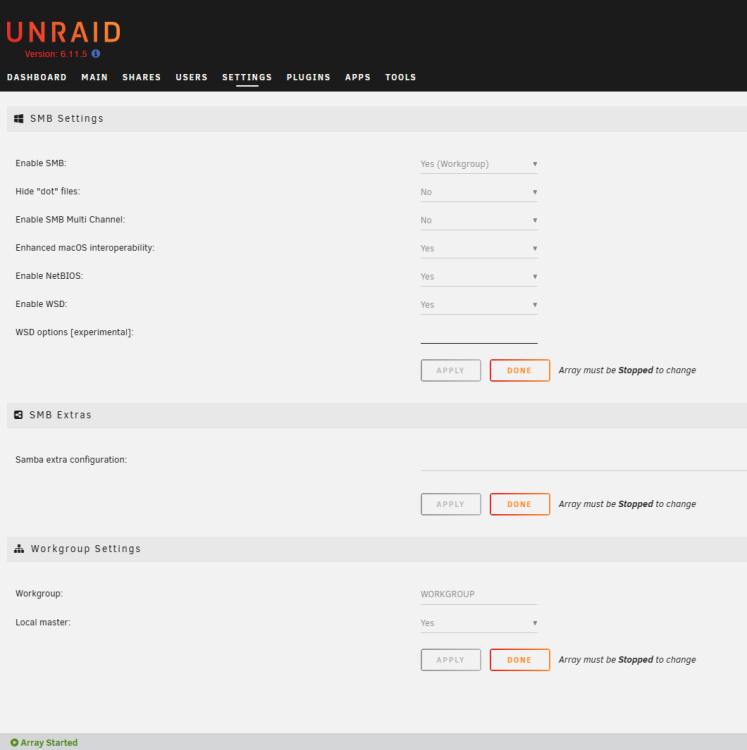
-
Many thanks - made a backup of the USB drive before copying over the bz* files (including the .SHA256 files - which it actually requires) as recommended, and re-booted. As simple as that. Worked like a charm.
-
I have 4 machines which need upgrading - two are on 6.3.2 and two are on 6.3.5 None are running anything but the basic unRAID drive array - no dockers or VMs. No plugins other than the Dynamix webGui 2017.02.16 (6.3.2) and 2017.05.26 (6.3.5). Tried following these instructions for v 6.3.x upgrade: https://wiki.unraid.net/Manual/Upgrade_Instructions Under Plugins, when I [Check for Updates] it finds an update to 6.3.5 Unfortunately, when I try to [update] it tells me: plugin: updating: unRAIDServer.plg plugin: downloading: https://s3.amazonaws.com/dnld.lime-technology.com/stable/unRAIDServer-6.5.3-x86_64.zip ... failed (Invalid URL / Server error response) plugin: wget: https://s3.amazonaws.com/dnld.lime-technology.com/stable/unRAIDServer-6.5.3-x86_64.zip download failure (Invalid URL / Server error response) That update file is no longer on S3 🤨 So I figure I need to upgrade manually - probably to a later version? Then I see this guidance: https://unraid.net/blog/6-11-1 So I decide I should run the Update Assistant - and I go to Tools to find it - except there is no update assistant! 🤔 So then it says I need to install the Fix Common Problems plugin. And I read this article: Which tells me to go to the Apps tab and search for Fix Common Problems Except that I don't have an Apps tab! 😟 I have: Dashboard / Main / Shares / Users / Settings / Plugins / Tools And at this point I am forced to admit defeat. Any idea what I need to do to get to the point where I can actually upgrade unRAID OS?
-
Perfect - thanks. Maybe I should enable it on all my 4 other unRAID servers too
-
OK - I temporarily borrowed 8GB of RAM from one of my other servers and enabled write caching in BIOS - now parity sync speed has gone from about 4MB/s to 100MB/s! Estimated completion of sync is 22 hours rather than closer to 22 days! Thanks for the help. Problem (apparently) solved! Is it a good idea to leave write cache enabled permanently - or is it better to disable it? All my servers are connected to a UPS.
-
Many thanks. To be honest, I think I'll just let it start from the beginning. Hopefully it will run a lost faster after the RAM is upgraded and maybe write cache is BIOS enabled (if it isn't).
-
Thanks for your suggestions. Is it OK for me to pause the parity sync, shut down the server and upgrade the RAM before re-starting and continuing the parity sync, or would I be better to scrub the array and start from scratch?
-
Hi - just built a brand new unRAID server in a HP Proliant N40L 2GB server chassis (I already have 4 other unRAID servers in similar hardware - except they have 6TB drives or smaller) 4 data drives + 1 parity. These are shucked 8TB Seagate desktop 5400rpm drives which have been extensively tested for errors (over several days) before installing. I also ran a memory test of the 2GB single memory card on the motherboard before starting. Running initial parity sync on the empty array. It's running *very* slowly (1MB - 6MB per second) - sync is only at 6.2% after 34 hours. Estimate at this rate is another 20 days to complete! I have attached a Diagnostics export. I see lots of repeated mention of: Dec 7 02:17:20 UNRAID-05 nginx: 2022/12/07 02:17:20 [error] 1353#1353: *390296 nchan: error publishing message (HTTP status code 500), client: unix:, server: , request: "POST /pub/devices?buffer_length=1 HTTP/1.1", host: "localhost" Dec 7 02:17:20 UNRAID-05 nginx: 2022/12/07 02:17:20 [error] 1353#1353: MEMSTORE:00: can't create shared message for channel /devices Dec 7 02:17:21 UNRAID-05 nginx: 2022/12/07 02:17:21 [crit] 1353#1353: ngx_slab_alloc() failed: no memory Dec 7 02:17:21 UNRAID-05 nginx: 2022/12/07 02:17:21 [error] 1353#1353: shpool alloc failed Dec 7 02:17:21 UNRAID-05 nginx: 2022/12/07 02:17:21 [error] 1353#1353: nchan: Out of shared memory while allocating message of size 7993. Increase nchan_max_reserved_memory. Any suggestions please? unraid-05-diagnostics-20221208-0759.zip






