




Senson
Members
-
Joined
-
Last visited
-
The balance didn't sort things out properly. I ended up following jonp's instructions here: STARTING POSITION: Two disks or more in a btrfs cache pool; array is running. 1 - Stop Array 2 - Unassign the disk from cache 2 (but do not change the # of slots) 3 - Physically detach cache 2 from the system (remove power / SATA) 4 - Start the array 5 - Open the log, notice a "balance" occurring (you'll see a number of entries such as this: Quote Jun 2 08:49:55 Tower kernel: BTRFS info (device sdf1): relocating block group 36561747968 flags 17 6 - When the balance completes, the device you physically removed will be deleted from the cache pool. Looks better now: Data, RAID1: total=119.00GiB, used=105.29GiB System, RAID1: total=32.00MiB, used=48.00KiB Metadata, RAID1: total=1.00GiB, used=516.38MiB GlobalReserve, single: total=99.72MiB, used=0.00B TL;DR I removed the second cache disk, let things settle, then re-added it back in.
-
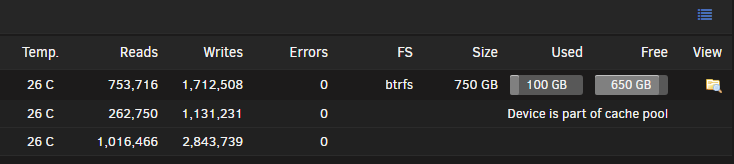
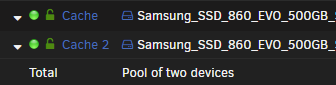
Hello, I have a cache pool that consists of two 500GB SSD's. Originally, the filesize showed as 500GB which is what I expected for a RAID1. I had an accident where one of the drives got disconnected and when I reconnected it, it appeared as though it stopped being RAID1. The filesize started showing 750GB. I tried rebalancing, stopping the array, rebooting, etc. but it still shows 750GB. Attached are photos of the config, and the cache status. I also noticed that in the balance status, it shows the following. Does this look correct for RAID1? Data, RAID1: total=118.00GiB, used=95.00GiB System, single: total=32.00MiB, used=48.00KiB Metadata, RAID1: total=1.00GiB, used=496.30MiB GlobalReserve, single: total=52.44MiB, used=0.00B
-
Yes, that fixed it. Thanks again
-
6.6.4... I will upgrade immediately. Thank you!
-
Hello, I *LOVE* this plugin! However, I am running into an issue. My cache drive failed so I had to reinstall all of my dockers. (I now have backups set up and a cache pool).. The problem I am running in to is that none of the scheduled jobs get executed. They work fine if I start them manually, but they will not run automatically on the schedule -- anyone have any ideas? Did I miss something? I had this set up and working fine before the cache drive went T.U. I've tried rebooting, and using the crond stop and start commands

