




Cull2ArcaHeresy
Members
-
Joined
-
Last visited
-
same issue of size option missing (so a screenshot is provided), but mine might be a full/almost full cache/array problem. If adding new disk does not clear the problem, ill create a new thread about it (datacenter feburb drive so doing preclear...not sure if 1 or 2 or 3 passes yet tho).
-
i've had scatters going from multiple drives to multiple drives (and multiple to one) do the same thing saying that will not be transferred (idr if had space comment), so i reselected what was left and it just took multiple passes to finish. But mine was more than 1 working transfers per drive. I'll dig into history to be more specific if needed to help hunt down the bug or cause (assuming not intentional)
-
no but there was talk about multiple pools previously (1 or 2 years ago i think), but boiled down to it being hard to identify pools that aren't "cache"
-
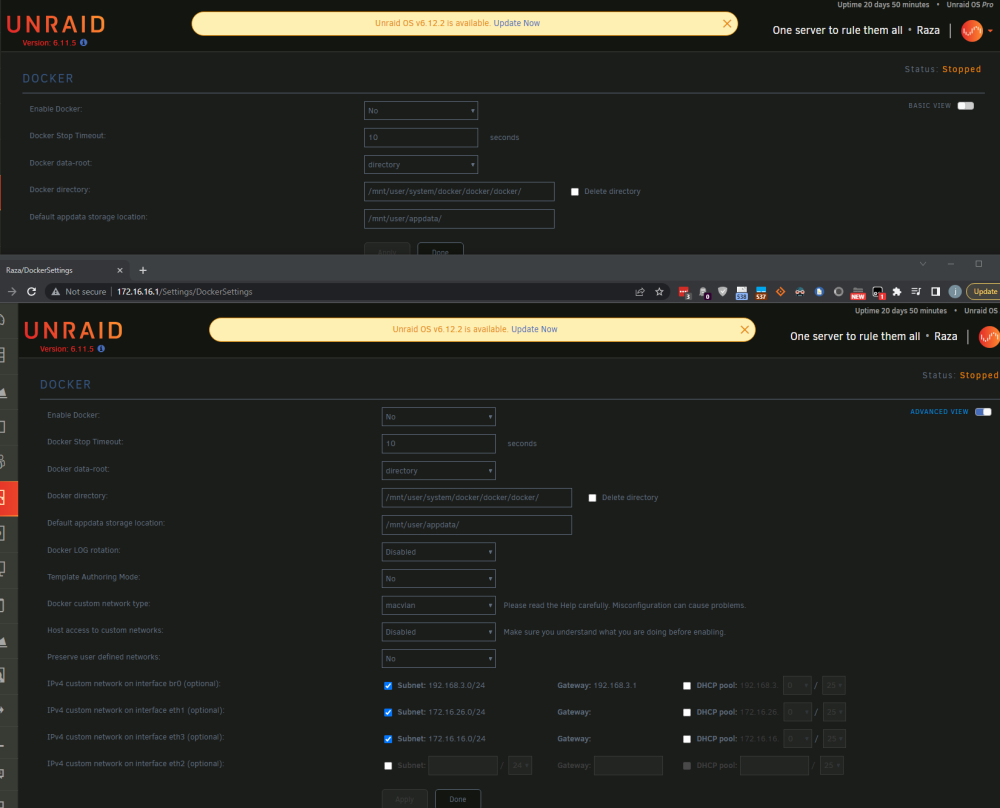
updated from 6.9.2 to 6.11.5 and now in a screen session i have to run "export TERM=linux" for many commands to be able run. Without the export command i get "Error opening terminal: vt100." that some commands throw (nload for example). Also screen -r partial_session_name tab complete completes a file name from current dir instead of session number or name. Is this an issue with version/config of screen in nerdtools or 6.11 bug to report? Nerdpack had screen 4.7.0 (according to my backup at least), and the version installed with nerdtools is running as 4.9.0
-
updating to 6.11.5 seems to have fixed this, but not marking as solved till server is up for a month without it happening again
-
updated from 6.9.2 to 6.11.5 and now in a screen session i have to run "export TERM=linux" for all commands to run instead of "Error opening terminal: vt100." that some commands throw (nload for example). Also screen -r partial_session_name tab complete completes a file name from current dir instead of session number or name.
-
forgot to come update this when tried moving 9202-16e to the 16x slot, in multiple reboots neither server hardware scanning thing that runs on boot nor unraid saw those drives so ended up just moving it back to the riser that has the 2 9207-8i cards that connect to the 14 server drive bays. Due to a different server issue (web ui problem a little while after booting up) i can't look up parity history, but iirc most checks have been just under 2 days this year. In the past the GPU that was in that slot was allocated to a VM, or at a different point a network card was in that slot allocated to a different VM, but that dealt with blocking off a PCIe device id (at least on the NIC) not the PCIe slot. One of those things on the "possibly investigate in the future" list...or when it is needed for some other reason. notification of your comment reminded me to reply above, but if there was an OS change, would be curious what since my speed has gone from ~120-140 down to ~80-100 (more like 80). Or if the subset of us with the issue are just having confirmation bias 😜
-
Rebooted and generated a copy of diagnostics from web ui. At some point between 1 and 2 days the issue happened again (does seem to have happened faster this time). Generated new copy of diagnostics via cli shortly before making this post. After reboot i saw there were updates to some plugins and dockers, but for consistency did not update them yet. When back home after holiday trip i can reboot, update plugins and dockers, reboot, and wait for issue to happen again. Also having the ui back (for a short bit) can look back into what prevented me from updating the os and after resolving that will update os (unless you say not to until this issue is resolved). Also a non-optimized version of my dupe finder is running on a selection of files to "quickly" free up some space to be able to redistribute space between the drives to make sure that isn't somehow causing a problem (will probably be done tomorrow and have 3 to 4 tb to free up). rightafterreboot_raza-diagnostics-20221221-0834.zip issuehappened_raza-diagnostics-20221223-1354.zip
-
on the plugins i have meant to look into that for a while (grab history stuff before removing), also i think i am a couple updates behind on base os. Total free space (if you include cache) is ~1.5tb, and it complains about different disks over time as stuff gets moved around. The tv_pool is full, but acts more as a level 3 cache (when there is room i change share setting to move from array to that cache and then after mover runs change it back to move from ssd cache to array). I'm hoping to add at least 16tb in the next month and then can rebalance to make it happy. I do have a script that am gonna finish writing in next week to check for duplicate files, but optimizing it to where it will have a thread hashing per drive/pool to speed it up (rough estimate of 1 to 5 tb to clear so can redistribute some and make it happy then too). This problem has been happening for a while now and a reboot fixes it for some time. Just to double check, 1) reboot, 2) grab diagnostics, 3) when issue happens again grab diagnostics and post both here? After that i can look into updating os.
-
i've had this issue for months now (think it started early 2022 but might have been at some point in 2021). When server boots everything is fine, and for a while after it is fine. But after a few days to a couple weeks it will start having this issue. The "frame" of the web ui loads, but the content does not. Sometimes stuff will load...a few times a day if i'm lucky. Behaves the same on dedicated 10g nic (172...) and local ip (192...), but used the 172 screenshot because dark reader messes with 192 differently. Also works the same on chrome, ff, ie, edge, browser in unraid gui, and i feel like i might have tried another browser too (plus mobile chrome and ff do same). The error below screenshot is what it gives after the page sits with the frame but not content loaded for a few minutes. Dec 17 08:40:30 Raza nginx: 2022/12/17 08:40:30 [error] 35647#35647: *7626036 upstream timed out (110: Connection timed out) while reading upstream, client: 172.16.16.2, server: , request: "GET /Dashboard HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock:", host: "172.16.16.1", referrer: "http://172.16.16.1/Dashboard" SSH and vms (via other vnc access) and dockers and file serving all work fine, just the content of page fails to load. All the other answers i've seen have to do with nothing loading, unless i missed this issue being answered. raza-diagnostics-20221217-0850.zip
-
with this last boot (well multiple when troubleshooting) pulseway stopped working and so then multiple reboots trying to fix/update it. Currently just saying screw it will fix pulseway later. I would assume no relation just coincidence in timing. I assume these errors would not be a "drive tray needs to be reseated into DAS" type of issue? How can i move the data off without repairing it first, or is it like it just reads from the "good" copy and ignores the errors if any (then deletes file from move) and so no prob to move? I see unraid 6.10 brings kernel up to 5.15, guessing 5.20 is a ways off then. i know server is a mess, the 3 non-cache pools are just 24tb overflows (for specific uses) to keep the main array cleaner (and over drive limit). I know i'm at the size where i need a second unraid or other server to handle all the categorical archive stuff, but that is not feasible right now so its a down the line thing (still looking at you 45 drives).
-
knew something was missing raza-diagnostics-20220804-0525.zip
-
Cache pool finished scrub correcting 2 errors, 2 other pools are still running with ~60 hours left and found no errors yet...but 1 pool just instantly aborts scrub. Tried it from web interface with reapir checked and nothing in log but seeing the command run, same thing when btrfs scrub status /mnt/archive_one is run from command. But if i run it from web interface with repair unchecked, i get the following in the log and it still goes right to aborted.
-
On Reddit like 5 years ago I was reading a post that was a few years old, but can't find it again. It had to do with rtorrent (or some other p2p client) and so are on unraid using some combination of soft links and hard links. Iirc it was something like both sides used a hard link that pointed to a softlink that pointed to the actual files. Is there something like this? I currently have a share for each of p2p, tv, and movie. A seedbox does most of the actual downloading and then imports it to my server. I do have binhex's rtorrentvpn docker, but I use the seedbox mainly for speed (and currently my VPN subscription expired). The automation is that seedbox downloads it and then seedbox sonarr imports and rsync grabbed the completed torrent to local to continue seeding. I know this makes linking more complicated too, I assume I would need to write a post import/sync linking script. If I need to create a share that has root folders for pep, tv, movie I can, but would really rather not. [Edit] plex runs on local server for media
-
Update, file integrity was running during parity check. Having fixed that setting, back to ~90 mb/s. When moving server this weekend will rearrange hba cards to test davids theory...but hit was from file integrity plugin.



