




tucansam
Members
-
Joined
-
Last visited
-
I put the stick in a windows machine and it detected (and claimed to fix) errors. Then unraid booted, with a few errors along the way regarding the usb drive, but it made it. For now. Is it time to replace my (less than 6 months old) usb stick again?
-
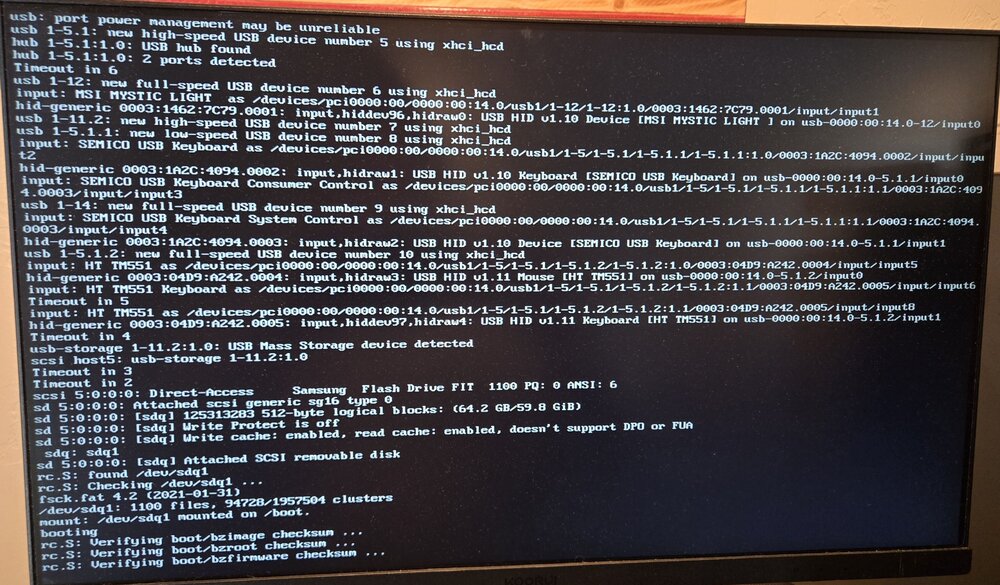
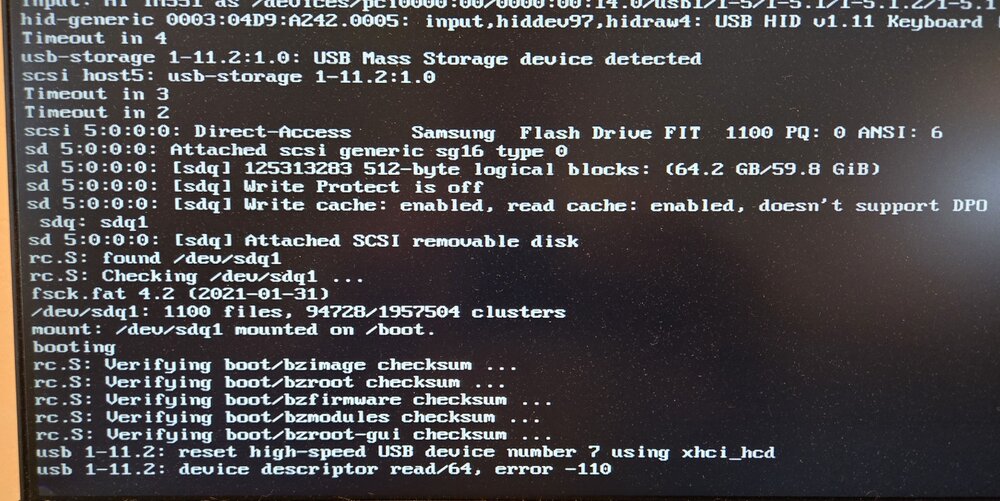
Been running unraid for over 15 years, have had ZERO usb issues until recently, now I've replaced the usb boot drive four times in two years (!) Always with reliable brands (Samsung currently) Not sure what's going on here, but it was just after the update to the most recent version, fresh off a reboot. Tried safe mode too, no luck. Options?
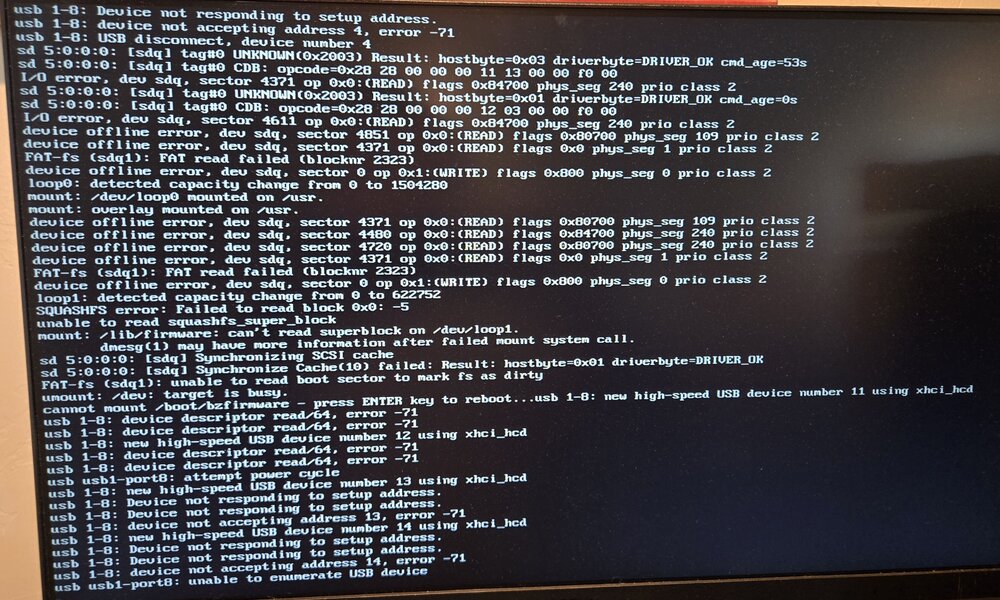
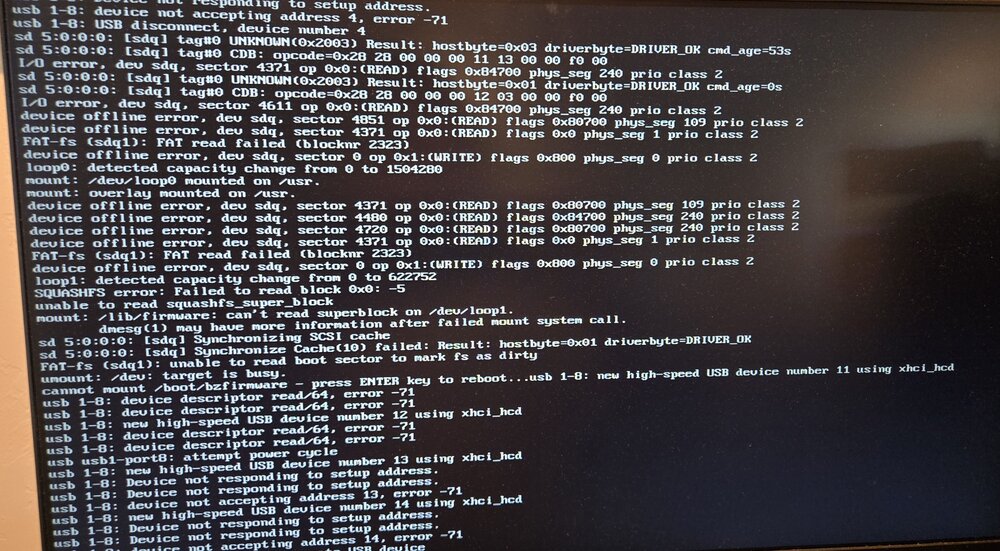
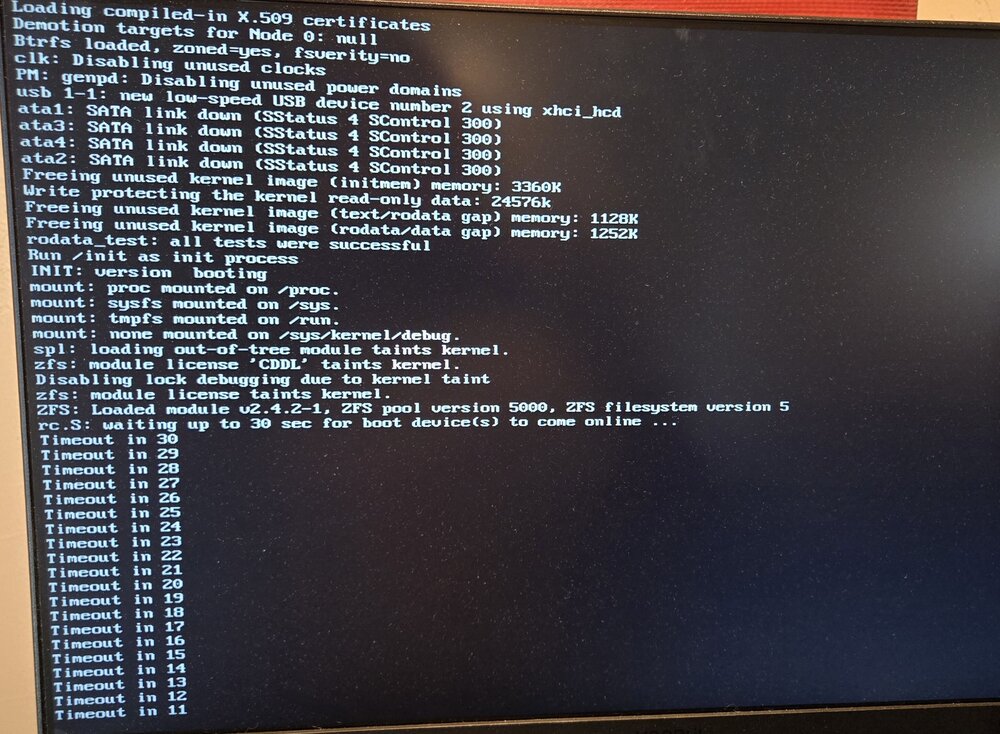
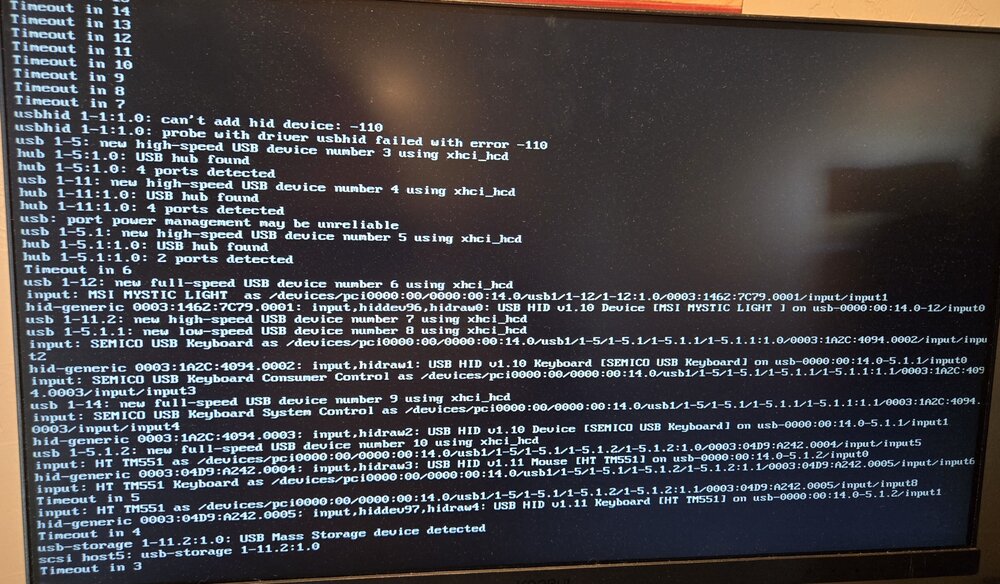
-
Sab quits randomly all the time, usually doesn't restart. -- 2026-06-02 17:08:57,692 INFO success: start-script entered RUNNING state, process has stayed up for > than 0 seconds (startsecs) 2026-06-02 17:08:57,692 INFO success: watchdog-script entered RUNNING state, process has stayed up for > than 0 seconds (startsecs) 2026-06-02 17:08:57,692 DEBG fd 9 closed, stopped monitoring <POutputDispatcher at 23442820355744 for <Subprocess at 23442821643440 with name start-script in state RUNNING> (stdout)> 2026-06-02 17:08:57,692 DEBG fd 11 closed, stopped monitoring <POutputDispatcher at 23442820258128 for <Subprocess at 23442821643440 with name start-script in state RUNNING> (stderr)> 2026-06-02 17:08:57,692 INFO exited: start-script (exit status 0; expected) 2026-06-02 17:08:57,692 DEBG received SIGCHLD indicating a child quit 2026-06-02 17:08:57,695 DEBG 'watchdog-script' stdout output: [info] SABnzbd not running 2026-06-02 17:08:57,695 DEBG 'watchdog-script' stdout output: [info] Attempting to start SABnzbd... 2026-06-02 17:08:58,265 DEBG 'watchdog-script' stdout output: [info] SABnzbd process started [info] Waiting for SABnzbd process to start listening on port 8080... 2026-06-02 17:08:58,267 DEBG 'watchdog-script' stdout output: [info] SABnzbd process is listening on port 8080 Press ANY KEY to close this window
-
After most recent upgrade, see this, never seen it before: -- Boot Device Device Identification Temp Reads Writes Errors FS Size Used Free Boot(Flash) Samsung_Flash_Drive_FIT_0353723110001137-0:0 - 64.2 GB (sdq) * 0.0 B/s 0.0 B/s 0 vfat 64.1 GB 2.81 GB 61.3 GB Internal Boot No internal boot setup detected. Launch Internal Boot to configure one. -- What is this and what do I do? There is another upgrade needed and now I am afraid to reboot.
-
Interesting. Will adjust and see. Thanks.
-
Both are intel two-port 10gb nics. RJ45. 192.168.0.x for the main network. 11.11.11.x for the nic-to-nic network, 11.11.11.1 for unraid and 11.11.11.2 for the PC.
-
eth0 (integrated) is on my primary network and all is good. I have a desktop PC also on this network a few feet away from the unraid server. I don't have a 10gb switch, but the PC and unraid server each have 10GB NICs. I have configured a new network on both machines (different from the primary and not routed) and have both machines directly connected via a 10gb cable between their 10gb NICs. Both interfaces show as up not neither can ping the other. Is there anything special as far as unraid networking goes that I am missing? Thanks.
-
Diags attached. Made at network change that prevented the docker from starting. Un-did the network change and the docker still continued to have random issues. Would run but couldn't update. Would run and then crash. Then wouldn't start. Then would run again. Then wouldn't. Moved everything off cache and onto the array with the intent of starting over. Ran fine for a few days, even updated. Now won't start at all. I have three SSDs in the system (all separate, no pools) and I'd like to: Get the docker and all containers running on the array disks without issue Format and nuke all three SSDs Put all the SSDs in a pool or protect them in some way and make all three part of cache Move the docker back to this new pool Profit Any help or insight would be appreciated. Thank you. ffs2-diagnostics-20260406-1036.zip
-
v7.2.3 Eth0 (onboard) was used for the life of the server. Installed a 10gig NIC and now Eth2 is in use. cat /boot/config/network.cfg and it looks like this: # Generated settings: IFNAME[0]="eth2" DHCP_KEEPRESOLV="yes" DHCP6_KEEPRESOLV="no" DESCRIPTION[0]="Gig-Eth2" PROTOCOL[0]="ipv4" USE_DHCP[0]="no" IPADDR[0]="192.168.0.5" NETMASK[0]="255.255.255.0" GATEWAY[0]="192.168.0.1" METRIC[0]="9" VLANS[0]="1" SYSNICS="1" I tried adding dns manually to the file and it won't stick. There is nowhere in the GUI to add dns to eth2, just eth0, and I've tried various configs and dns will simply not work. How can I tell unraid that eth2 is the new (and only) NIC, and where can I configure dns? This change has broken all sorts of things, including the function of all docker web guis.
-
I know this is no longer maintained. That makes me sad. When I go to the metube web interface, "Connecting to server...." takes upwards of 5-10 minutes sometimes. Confused as to why.
-
Thanks. My last two were Samsung 64GBs (smallest they had at the time) from amazon
-
I've been using unraid since the 4.xxx days, maybe before. Somewhere around 2010, 2011 maybe? Maybe longer, actually. My very first USB thumb boot drive lasted for over a decade, maybe 13-14 years. I have now replaced the USB drive three times in the last 12 months, and the most recent one just died again yesterday. Is there something going on with USB disks these days? Do they just not make them like they used to? is anyone else plagued with continuously failing USB boot drives and the headache that comes with? Thanks.
-
I have stumped the hive, I see.
-
BTW the console is frozen so htop wasn't updating in realtime so I have no idea what the system looked like in that instant.
-
All memory in use and a pegged CPU and a sysload I've never seen all for a disk rebuild.





