




Debarka Banik
Members
-
Joined
-
Last visited
-
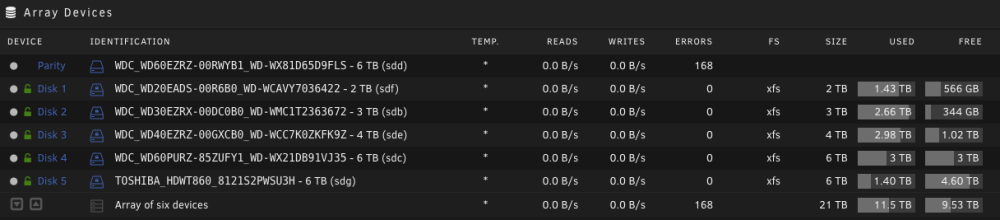
Hi, My parity drive started showing errors towards the end of a parity check. Here is what shows in the disk log shows. Sep 4 11:09:05 Tower kernel: ata3: SATA max UDMA/133 abar m2048@0xa1122000 port 0xa1122200 irq 124 Sep 4 11:09:05 Tower kernel: ata3: SATA link up 6.0 Gbps (SStatus 133 SControl 300) Sep 4 11:09:05 Tower kernel: ata3.00: ACPI cmd ef/10:06:00:00:00:00 (SET FEATURES) succeeded Sep 4 11:09:05 Tower kernel: ata3.00: ACPI cmd f5/00:00:00:00:00:00 (SECURITY FREEZE LOCK) filtered out Sep 4 11:09:05 Tower kernel: ata3.00: ACPI cmd b1/c1:00:00:00:00:00 (DEVICE CONFIGURATION OVERLAY) filtered out Sep 4 11:09:05 Tower kernel: ata3.00: ATA-10: WDC WD60EZRZ-00RWYB1, WD-WX81D65D9FLS, 80.00A80, max UDMA/133 Sep 4 11:09:05 Tower kernel: ata3.00: 11721045168 sectors, multi 16: LBA48 NCQ (depth 32), AA Sep 4 11:09:05 Tower kernel: ata3.00: ACPI cmd ef/10:06:00:00:00:00 (SET FEATURES) succeeded Sep 4 11:09:05 Tower kernel: ata3.00: ACPI cmd f5/00:00:00:00:00:00 (SECURITY FREEZE LOCK) filtered out Sep 4 11:09:05 Tower kernel: ata3.00: ACPI cmd b1/c1:00:00:00:00:00 (DEVICE CONFIGURATION OVERLAY) filtered out Sep 4 11:09:05 Tower kernel: ata3.00: configured for UDMA/133 Sep 4 11:09:05 Tower kernel: sd 3:0:0:0: [sdd] 11721045168 512-byte logical blocks: (6.00 TB/5.46 TiB) Sep 4 11:09:05 Tower kernel: sd 3:0:0:0: [sdd] 4096-byte physical blocks Sep 4 11:09:05 Tower kernel: sd 3:0:0:0: [sdd] Write Protect is off Sep 4 11:09:05 Tower kernel: sd 3:0:0:0: [sdd] Mode Sense: 00 3a 00 00 Sep 4 11:09:05 Tower kernel: sd 3:0:0:0: [sdd] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA Sep 4 11:09:05 Tower kernel: sdd: sdd1 Sep 4 11:09:05 Tower kernel: sd 3:0:0:0: [sdd] Attached SCSI disk Sep 4 11:09:36 Tower emhttpd: WDC_WD60EZRZ-00RWYB1_WD-WX81D65D9FLS (sdd) 512 11721045168 Sep 4 11:09:36 Tower kernel: mdcmd (1): import 0 sdd 64 5860522532 0 WDC_WD60EZRZ-00RWYB1_WD-WX81D65D9FLS Sep 4 11:09:36 Tower kernel: md: import disk0: (sdd) WDC_WD60EZRZ-00RWYB1_WD-WX81D65D9FLS size: 5860522532 Sep 4 11:09:36 Tower emhttpd: read SMART /dev/sdd Sep 4 11:09:39 Tower root: /usr/sbin/wsdd Sep 4 11:09:42 Tower emhttpd: shcmd (22): echo 128 > /sys/block/sdd/queue/nr_requests Sep 4 11:10:33 Tower emhttpd: shcmd (83): echo 128 > /sys/block/sdd/queue/nr_requests Sep 4 11:11:07 Tower root: /usr/sbin/wsdd Sep 5 04:04:52 Tower kernel: ata3.00: exception Emask 0x0 SAct 0x70000079 SErr 0x0 action 0x0 Sep 5 04:04:52 Tower kernel: ata3.00: irq_stat 0x40000008 Sep 5 04:04:52 Tower kernel: ata3.00: failed command: READ FPDMA QUEUED Sep 5 04:04:52 Tower kernel: ata3.00: cmd 60/40:e0:a0:d1:cb/05:00:95:02:00/40 tag 28 ncq dma 688128 in Sep 5 04:04:52 Tower kernel: ata3.00: status: { DRDY ERR } Sep 5 04:04:52 Tower kernel: ata3.00: error: { UNC } Sep 5 04:04:52 Tower kernel: ata3.00: configured for UDMA/133 Sep 5 04:04:52 Tower kernel: sd 3:0:0:0: [sdd] tag#28 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=0x08 cmd_age=3s Sep 5 04:04:52 Tower kernel: sd 3:0:0:0: [sdd] tag#28 Sense Key : 0x3 [current] Sep 5 04:04:52 Tower kernel: sd 3:0:0:0: [sdd] tag#28 ASC=0x11 ASCQ=0x4 Sep 5 04:04:52 Tower kernel: sd 3:0:0:0: [sdd] tag#28 CDB: opcode=0x88 88 00 00 00 00 02 95 cb d1 a0 00 00 05 40 00 00 Sep 5 04:04:52 Tower kernel: blk_update_request: I/O error, dev sdd, sector 11103097248 op 0x0:(READ) flags 0x0 phys_seg 168 prio class 0 Sep 5 04:04:52 Tower kernel: ata3: EH complete I ran an extended self-test and it passed it. Attaching the self-test and diagnostics below. Can I still continue using the disk? And if so, how do I reset the error count? Otherwise all the array health reports are coming as failed. tower-smart-20220906-1519.ziptower-diagnostics-20220906-1522.zip Thanks!
-
One thing I noticed was my PCH temperature. Without boost it's at around 64-65C, which already looks high to me. With boost enabled, it was hovering between 69-73C. I never had a look at it when this hardware was running as my daily Windows PC. Some Googling seems to suggest that higher temperatures are normal for the PCH. Although I'm not able to find exact figures for my chipset (B360). A bit of trivia is this chipset came out before the Intel 9th generation (Coffee Lake refresh) CPU's and was initially not 100% compatible. Subsequent BIOS updates were meant to take care of that. Mine has those updates. But maybe some thermal or other design limitations remain that can't be updated.
-
Okay, got some updates. Changing the RAM and power supply did not help. I also posted this on the Facebook group and got a helpful tip from Juan Jose Chong there to try disabling turbo boost in the BIOS. And sure enough, I'm at over 12 hours now without crashes with all 3 VM's running. Now I could run like this, but I'd be giving up some of the performance potential of my CPU (on my i7-9700 that about 1.7GHz). Have you guys seen similar behavior before? What could be causing this? Motherboard? CPU?
-
Hare are the diagnostics from the last crash. Also attaching the complete persistent syslog from the syslog server. tower-diagnostics-20210706-0024.zip syslog-127.0.0.1.log The last pre-crash message seems to be my SSH login info from 22:26. Note that the syslog server version is missing the messages from boot-up till the time I started the array (it's passphrase encrypted) as the destination is on the cache drive. The local syslog which is included in the diagnostics zip has those messages.
-
Yes, 10 passes with no errors.
-
Still no luck but I thought I'll keep the thread updated anyway as my investigation progresses in case it helps anybody in the future. Most of the crashes are happening around the 4-5 hour mark but some have happened even after 7 hours and some in less than an hour. Here are my observations so far. Like I said in my last post, I did a Prime95 run on a Windows VM using all CPU cores and 16GB out of the 20GB of RAM available. I ran it for over 7 hours and didn't see any issues. Ran Memtest86+ for 10 passes - no issues found. My typical use has 3 VM's (1 Windows and 2 Linux) running 24x7. Most of the crashes seem to be happening when I have these VM's running. Just the Windows VM is running fine, but the Windows VM and even one of the Linux VM's are causing crashes. 2 of Linux VM's together are also crashing. I tried with just 1 of the Linux VM's and it ran the longest (over 7 hours) before crashing. Trying with the other Linux VM now - just crossed 7 hours. I have new RAM coming. I'm hoping that 2 sticks of homogenous RAM would be better than 2 heterogenous sticks like I mentioned in my last post. If that doesn't help, I guess I'll try a power supply swap. The successful Prime95 run makes me think it's not a power supply issue. Or cooling. CPU temp was under 55C even at 100% load. Beyond this I'm not sure what to do as it would involve blindly spending money on a new motherboard or worst case, a CPU. After the the same hardware was running fine as my Windows rig until a few days ago. A thought - how reliable are NVMe drives under Unraid? As most of my crashes are happening with the VM's running and they all run on the NVMe cache. I suppose most Unraid users don't actually use NVMe drives as cache and go for SATA SSD's instead. Please do chip in if you have any thoughts - anything at all. Thanks!
-
No ideas anyone? It seems to be happening around 4-5 hours from boot time. I'm currently running a Prime95 test on a Windows VM with maxed out CPU cores and near max RAM. I was suspecting power supply or cooling but both seem to be coping really well so far. Will keep this running for 5-6 hours and then maybe try a memtest86 for a similar duration. I already had a short 1 pass of memtest86 and didn't see any issues. To give you a background on the hardware changes, I had my Unraid running on an MSI H97 PC-Mate with an i5-4460 for well over a year. It ran 24x7 with several VM's and dockers and zero crashes during this period. However I had filled all my SATA ports and was running spinning HDD as my cache for the VM's, etc. Old specs: MSI H97 PC-Mate i5-4460 (4 cores) 3 x 8GB DDR3 (I had 4 sticks to begin with but one of them went bad long ago and was never replaced) 6 SATA drives of different sizes for the array including 1 for cache. Corsair VS450 450W power supply Recently, my main PC with better hardware got redundant, so I thought of putting its parts to use on the Unraid box. This is aa Asrock B360-HDV with an i7-9700 (not K) and could run a NVMe in addition to the SATA drives. As my PC too this setup has run reliably for over a year. Though it didn't run 24x7, it has done a lot of heavy loads. New Specs: Asrock B360-M with updated UEFI i7-9700 (8 cores) 8GB + 16GB DDR4 Crucial P1 1TB NVMe SSD for cache 6 SATA drives of different sizes for the array (the cache HDD from earlier was added into the array) Corsair VS450 450W power supply (same as before) I really thought I could benefit from the extra CPU cores and the SSD for the VM's. But if I'm not able to resolve this, I may have to go back to my earlier setup. Would really hate to be unable to use the better hardware.
-
It happened again. grep mce /var/log/syslog Jul 2 17:10:20 Tower kernel: mce: CPU0: Thermal monitoring enabled (TM1) Jul 2 17:10:20 Tower kernel: mce: [Hardware Error]: Machine check events logged Jul 2 17:10:20 Tower kernel: mce: [Hardware Error]: CPU 5: Machine Check: 0 Bank 0: b200000000030005 Jul 2 17:10:20 Tower kernel: mce: [Hardware Error]: TSC 0 Jul 2 17:10:20 Tower kernel: mce: [Hardware Error]: PROCESSOR 0:906ed TIME 1625225999 SOCKET 0 APIC a microcode de Jul 2 17:10:33 Tower nerdpack: Installing mcelog-161 package... Jul 2 17:10:33 Tower root: Installing mcelog-161 package... tower-diagnostics-20210702-1720.zip
-
Hi everyone, I was in the process of moving stuff from the array to the cache after some hardware changes - replaced motherboard, CPU and cache drive, when UNRAID crashed. Soon after rebooting, got the warning about machine check events from Fix Common Problems. I installed mcelog after that, so it probably wasn't used when the crash happened. Anyway, here is what I see in syslog. grep mce /var/log/syslog Jul 2 12:53:59 Tower kernel: mce: CPU0: Thermal monitoring enabled (TM1) Jul 2 12:53:59 Tower kernel: mce: [Hardware Error]: Machine check events logged Jul 2 12:53:59 Tower kernel: mce: [Hardware Error]: CPU 1: Machine Check: 0 Bank 0: b200000000030005 Jul 2 12:53:59 Tower kernel: mce: [Hardware Error]: TSC 0 Jul 2 12:53:59 Tower kernel: mce: [Hardware Error]: PROCESSOR 0:906ed TIME 1625210618 SOCKET 0 APIC 2 microcode de Jul 2 13:06:34 Tower root: mcelog not installed Jul 2 13:10:04 Tower nerdpack: Downloading mcelog-161-x86_64-1.txz package... Jul 2 13:10:05 Tower nerdpack: mcelog-161-x86_64-1.txz package download sucessful! Jul 2 13:10:05 Tower nerdpack: Installing mcelog-161 package... I'm also attaching my diagnostics zip here. Could you please help me figure out what went wrong? Hopefully nothing major. tower-diagnostics-20210702-1317.zip
-
Thank you for this. A couple of questions. What happens if I set "Delete Swap file upon Stop" to No? Is there any undesirable effect from this? I'm thinking from the perspective of avoiding unnecessary writes to an SSD. After setup, my status says swap file exists but not in use. I hope this means that the swap is ready to be used when needed and I don't have to do anything else?
