bwv1058
Members
-
Joined
-
Last visited
Everything posted by bwv1058
-
I see. I will of course look into that as soon as I can. Should I shut down the server in the meantime?
-
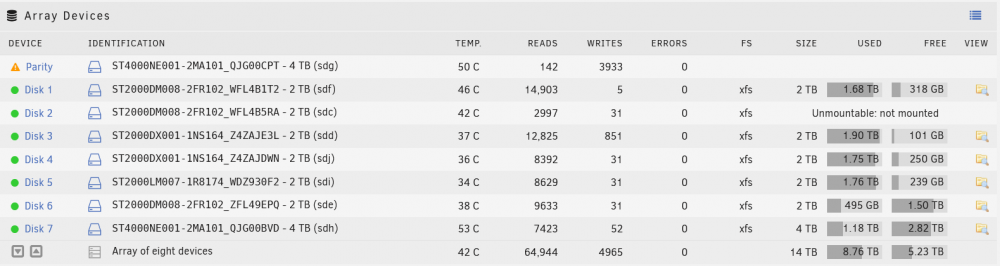
Disk7 is now unmountable, meanwhile disk2 is still disabled... I'm starting to be quite worried. tower-diagnostics-20230125-1037.zip
-
Alright, seems like I don't need to rerun the test with the -L flag after all... However, seems like many "inodes" habe been moved to the lost+found folder. What exactly does that mean? XFS_REPAIR Summary Wed Jan 25 10:17:39 2023 Phase Start End Duration Phase 1: 01/25 10:13:32 01/25 10:13:32 Phase 2: 01/25 10:13:32 01/25 10:13:33 1 second Phase 3: 01/25 10:13:33 01/25 10:16:14 2 minutes, 41 seconds Phase 4: 01/25 10:16:14 01/25 10:16:15 1 second Phase 5: 01/25 10:16:15 01/25 10:16:29 14 seconds Phase 6: 01/25 10:16:29 01/25 10:17:01 32 seconds Phase 7: 01/25 10:17:01 01/25 10:17:01 Total run time: 3 minutes, 29 seconds done Should I now just restart the array normally or does the server need a reboot?
-
Thank you again! Sorry if I'm being excessively cautious, but I just want to make sure I'm not causing any unnecessary damage. I'm now repeating the test just with verbose output and we'll see what comes next. From the documentation I get the following: Shouldn't it be concerning that the "filesystem will likely appear to be corrupt" etc.?
-
Dear JorgeB, Thank you for your quick reply. The xfs filesystem test with the -nv flag gave me a long output with various problems (not sure if posting it here might actually be of any help). The final paragraph reads: No modify flag set, skipping phase 5 Inode allocation btrees are too corrupted, skipping phases 6 and 7 No modify flag set, skipping filesystem flush and exiting. XFS_REPAIR Summary Tue Jan 24 20:41:37 2023 Phase Start End Duration Phase 1: 01/24 20:40:39 01/24 20:40:39 Phase 2: 01/24 20:40:39 01/24 20:40:40 1 second Phase 3: 01/24 20:40:40 01/24 20:41:37 57 seconds Phase 4: 01/24 20:41:37 01/24 20:41:37 Phase 5: Skipped Phase 6: Skipped Phase 7: Skipped Total run time: 58 seconds The link you posted mentions that I would be given instructions as to how to proceed, but that doesn't seem to be the case here. What is the next step going to be? Many thanks
-
Dear community members, My server just reported that disk 2 of my array is being emulated. I am at a loss as to what caused it to fail since the smart report seems (mostly) fine. At the same time I keep getting various error messages about disk 7. From what I know CRC errors are typically related to bad cables, but I remember checking that particular cable/sockets in the past and could not find anything obvious. Also, I don't know what "metadata I/O error" refers to. I would like to ask you for advice: I won't be able to directly access my server for at least two weeks but I have remote access through a vpn server (separate machine). Is there anything I could or indeed should do? Many thanks in advance! tower-diagnostics-20230124-1849.zip
-
Thanks again for your replies! No, fortunately there is no "lost+found" share, so I'm assuming that everything is alright! I've noticed that lately my drives have been running very hot (40-50 Celsius). Could that explain the problems I was having?
-
Wow, seems that the filesystem repair (using -L) did do the trick and my drive is now mountable again. Thanks to each and every one for your help. You're awesome! Two questions: 1. How likely is it that I might have lost some data in the process (I'm not seeing anything obvious...) 2. What caused this mess in the first place?
-
Now it's giving me the following warning: Phase 1 - find and verify superblock... - reporting progress in intervals of 15 minutes Phase 2 - using internal log - zero log... ERROR: The filesystem has valuable metadata changes in a log which needs to be replayed. Mount the filesystem to replay the log, and unmount it before re-running xfs_repair. If you are unable to mount the filesystem, then use the -L option to destroy the log and attempt a repair. Note that destroying the log may cause corruption -- please attempt a mount of the filesystem before doing this.
-
Unfortunately, it still won't mount...
-
Thank you for your reply! I've already done the filesystem check, but I don't know what my next steps would be: Phase 1 - find and verify superblock... - reporting progress in intervals of 15 minutes Phase 2 - using internal log - zero log... ALERT: The filesystem has valuable metadata changes in a log which is being ignored because the -n option was used. Expect spurious inconsistencies which may be resolved by first mounting the filesystem to replay the log. - 10:24:41: zeroing log - 29809 of 29809 blocks done - scan filesystem freespace and inode maps... sb_ifree 6816, counted 6810 sb_fdblocks 61151334, counted 61638135 - 10:24:44: scanning filesystem freespace - 32 of 32 allocation groups done - found root inode chunk Phase 3 - for each AG... - scan (but don't clear) agi unlinked lists... - 10:24:44: scanning agi unlinked lists - 32 of 32 allocation groups done - process known inodes and perform inode discovery... - agno = 0 - agno = 30 - agno = 15 - agno = 16 - agno = 31 - agno = 1 - agno = 2 - agno = 17 - agno = 3 - agno = 4 - agno = 18 - agno = 5 - agno = 6 - agno = 19 - agno = 7 - agno = 20 - agno = 21 - agno = 8 - agno = 22 data fork in ino 2952917491 claims free block 369115387 - agno = 23 - agno = 24 - agno = 9 - agno = 25 - agno = 10 - agno = 26 - agno = 27 - agno = 11 - agno = 28 - agno = 29 - agno = 12 - agno = 13 data fork in ino 3898087901 claims free block 487260754 - agno = 14 - 10:25:25: process known inodes and inode discovery - 230144 of 230144 inodes done - process newly discovered inodes... - 10:25:25: process newly discovered inodes - 32 of 32 allocation groups done Phase 4 - check for duplicate blocks... - setting up duplicate extent list... free space (29,721487-721489) only seen by one free space btree - 10:25:25: setting up duplicate extent list - 32 of 32 allocation groups done - check for inodes claiming duplicate blocks... - agno = 0 - agno = 1 - agno = 4 - agno = 3 - agno = 7 - agno = 5 - agno = 6 - agno = 2 - agno = 8 - agno = 9 - agno = 10 - agno = 11 - agno = 12 - agno = 13 - agno = 14 - agno = 15 - agno = 16 - agno = 17 - agno = 18 - agno = 19 - agno = 20 - agno = 21 entry "Bounced Files" in shortform directory 2818603873 references free inode 2975656813 would have junked entry "Bounced Files" in directory inode 2818603873 - agno = 22 - agno = 23 - agno = 24 - agno = 25 - agno = 26 - agno = 27 - agno = 28 - agno = 29 - agno = 30 - agno = 31 - 10:25:25: check for inodes claiming duplicate blocks - 230144 of 230144 inodes done No modify flag set, skipping phase 5 Phase 6 - check inode connectivity... - traversing filesystem ... entry "Bounced Files" in shortform directory inode 2818603873 points to free inode 2975656813 would junk entry - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify link counts... would have reset inode 2818603873 nlinks from 3 to 2 - 10:25:46: verify and correct link counts - 32 of 32 allocation groups done Maximum metadata LSN (111:54898) is ahead of log (111:51422). Would format log to cycle 114. No modify flag set, skipping filesystem flush and exiting.
-
Dear community, I have recently replaced my old parity drive, since the old one had failed (red cross). However, after installing the new drive and starting parity sync, my disk2 shows up as "unmountable". Now I'm really concerned about data loss, since parity had not finished rebuilding and I'm not sure how to fix the mount problem (I've tried different cables and controllers with no change). Any help would be appreciated! tower-diagnostics-20220720-1007.zip