

AshranPewter
-
Posts
33 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by AshranPewter
-
-
Ok, I think last time I'll post about this but hopefully the following helps for someone that doesn't want to go down the Docker Volumes route. Docker Volumes fixed it and I'm fine using docker nfs volumes as it's probably the easier way in the end.
That being said and I haven't tested this because, it's working so I'm not gonna break it.
But the mounts I had that weren't working with plex:
QuoteFlags: rw,noatime,vers=4.2,rsize=524288,wsize=524288,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=192.168.x.x,local_lock=none,
addr=192.168.x.x
The Docker Mounts that are working with plex from docker:
QuoteFlags: rw,relatime,vers=4.2,rsize=524288,wsize=524288,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=192.168.x.x,local_lock=none
,addr=192.168.x.x
The only difference looks to be the noatime vs relatime in the nfs mount. So it's possible this could fix my mounts and how plex uses them. But also docker could be treating docker volumes in a different way to account for storage being over the network compared to bind mounts. So take the above as you will, haven't tested it but thought it might be useful for anyone running into this issue.
Cheers
-
Hi,
Not sure if this is the best place, but HDDB isn't showing any graphs or benchmarks.
I'm trying to compare my data to see if there's anything wrong with my new drives.
Lots of 404s in the network dev tools and such.
Cheers
-
 1
1
-
-
It's probably just a plex issue overall, due to how they lock files so I would investigate lock/nolock more, it doesn't affect my Emby or Jellyfin install or any of my other dockers using the same mount points. But I'm unsure how to fix it and right now docker volumes for me fixes the issue and is probably better overall in terms of reliability for docker based apps. It also happens on all three of the commonly used docker containers available (linuxserver, hotio, official plex)
Samba doesn't have the same issues but has illegal characters that cause problems in Plex.
Overall probably not an unRaid issue and Plex probably won't help because their support forums are just like shouting into the dark in terms of official support.
-
Back to this for anyone having issues. The nolock didn't work, still had issues if I wanted to use the cache drive and the mover ran. I have ideas that maybe the mover tuner was causing issues but it was not the issue.
I stopped having any issues related to stale file handles in ubuntu but Plex (running in docker) was having issues where it would happen inside the container.
The fix? Mount the nfs shares using docker volumes. I'm sure there is probably something else that could fix it, NFS is probably mounted by docker using some specific parameters to alleviate the problems I encountered and docker volumes are probably better, bind was just simpler (or so I thought) at the time.
-
For anyone running into this, plex specifically seems to cause this issue.
Adding 'nolock' into your fstab on the client side fixes this... so far.
-
if anyone has any idea of what I can change, would appreciate it! Not using a cache drive and it's... meh to say the least.
Thanks~!
-
I blew away my config for unraid and then redid everything. When the mover runs it causes the same issue.
Everything using nfs 4 as far as I know.
It does seem strange that it's just the top level of the directory has a stale file handle.
Also to confirm with screenshots nfs4
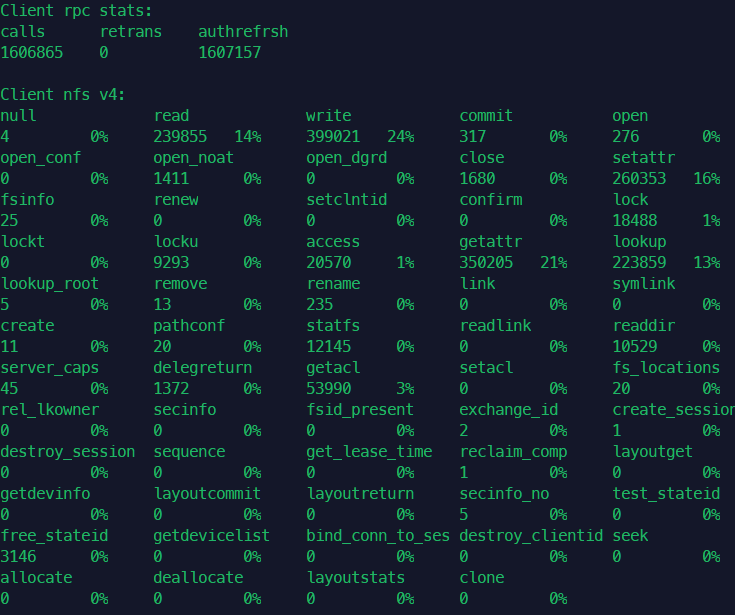
-
10 hours ago, dlandon said:
I doubt this will help because the issue is not showing up on Unraid. This solution was a "get around" for NFSv3 server issues on Unraid.
Try adding 'noacl' to the mount paramaters. Also check your mount setup. I don't think you are mounting using NFSv4.
The experience we've had on Unraid is that just using the NFSv3 server on Unraid caused the stale file handle situation. Once we converted to NFSv4, the stale file handle issue went away. If the stale file handle issues you are seeing are not showing on Unraid, there probably isn't much more we can do to help you. You'll have to look on the client side to see what is happening.
It shows me using nfs v4 in my client, but I'm not sure how to check in Unraid. I assume it has to be reciprocated so it's the same on the other side.
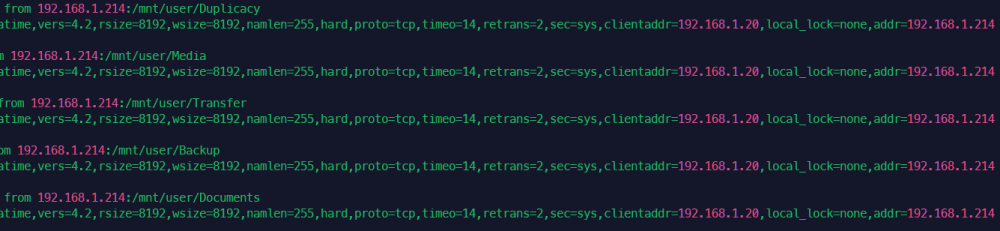
One thing to note is that my shares look like this
And I can cd into the Media folder and then into the folders under it if I know the name. But can't auto-complete or anything.
2 hours ago, scubanarc said:Try running the following on your client:
nfsstat -cDoes it say "nfs v4"?
Ya, it shows "Client nfs v4" just as my nfsstat -m shows it on each of my separate mounts as 4.2
-
Bump, maybe someone has some insights or something I can run to fix it!
edit: (without removing the mover), if I don't have cache while moving these large files it affects the entire system and if the transfer take too long, can't play any media with my media server. So if possible a solution without that would be awesome...
I'm using the mover plugin, not sure if plugin.old is causing this? it's showing up in my logs.
-
17 hours ago, scubanarc said:
Are you sure that your client is using NFSv4 and not v3?
These are the flags for all my mounts on my client system (ubuntu server) using nfsstat -m
Flags: rw,relatime,vers=4.2
17 hours ago, dlandon said:Where are you seeing stale file handles? There aren't any logged in the syslog.
It's actually really weird
I know about it because in my plex container I get the error:
Please check that the file exists and the necessary drive is mountedAnd within the plex files it shows as:
Dec 06, 2022 04:46:25.428 [0x7fba5a989b38] ERROR - [Req#47f3/Transcode/Req#4806] Couldn't check for the existence of file "/data/media/music/2CELLOS/Dedicated (2021)/2CELLOS - Dedicated - 07 - I Don't Care.mp3": boost::filesystem::status: Stale file handle: "/data/media/music/2CELLOS/Dedicated (2021)/2CELLOS - Dedicated - 07 - I Don't Care.mp3"I have these mounted on all my other containers just fine... so maybe something to do with.
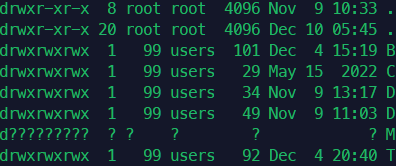
Also just now after I've written the above I had a stale file handle error, the docker containers were able to access the media just fine. But in a ssh session with my server it would consistently show stale file handle when I ls in the Media mount. And it would show ?? ?? ? for all the permissions instead of drwxrwxrwx, 99 users.
I just did a reboot and it seemed to fix it but still annoying. Don't see anything in the logs for unraid but I'll upload the latest.
tianding-diagnostics-20221208-1151.zip
Edit: The weirdest thing is that on my client system, I can access the media files just fine through my docker apps now. Plex even works fine, but through the commandline using 'ls -la' it shows as stale file handles and I can't view it at all.
I only run a single docker container on this and have minimal configuration so I'm ok with just resetting it all and start fresh with 6.11.5. But if there's a setting I can change that would fix it, it would definitely save some time.
-
Getting stale file handles through NFS, on 6.11.5
Attached are the diagnostics. If there's an old setting I need to mess with glad to change anything. Thought I was done with this...
tianding-diagnostics-20221207-0852.zip
Edit: Quick note, I did turn on hard links in global share settings recently to see if it would fix, the issue presented itself before and after the setting was changed.
-
Wanted to note in here that it can be easier to passthrough the serials in the VM. You modify conf file for the VM in proxmox.
It will look like the following:
0QEMU_QEMU_HARDDISK_WCT45QE6
Link to the guide:
https://dannyda.com/2020/08/26/how-to-passthrough-hdd-ssd-physical-disks-to-vm-on-proxmox-vepve/
Makes it easier when migrating to a vm or to using a hba passthrough.
Edit: Going to add in a short tidbit about what the guide says about serials here because I don't want the info to be lost if the site goes down for some reason. But if it helps and you want to support them please go click on some ads or donate to them cause it really did help me!
edit the file here (making sure to change '100' to your qemu vm id): /etc/pve/qemu-server/100.conf
on the line with your passthrough HDD /dev/disk/by-id/ata-WDC_xxxxxxx-xxxxxxxxxxxxxx,size=xxxxxxK,serial=xxxxxx-xxxxxxx add in the serial. It can't be longer than 18 bytes.
-
For anyone curious, shutdowns now work from a hypervisor (proxmox) from my testing of 6.10.3
Which is pretty nice.
Broadcast message from root@hostname (Sat Jul 2 17:08:23 2022): hypervisor initiated shutdown The system is going down for system halt NOW! Session was closed Linux 5.15.46-Unraid.
-
 1
1
-
-
I tried fixing the permissions across a lot of my docker containers but I seem to be having issues across a number of them and I'm not sure what to do. Tried to use the script above, the tool in the OS (the non-docker safe one because obviously it wouldn't hit appdata where the issue is). All had logs in their respective dockers about permission issues. If i used the tools, then things like traefik wouldn't serve the correct ssl cert.
Authelia
Sonarr
Radarr
Emby
Traefik
etc.
I reverted back to 6.9.2 because I had no clue what else could be going wrong with my system.
The majority of those are linuxserver.io containers with 99/100 permissions and 002 umask but authelia and traefik both aren't.
Anyone have a surefire fix for this?
-
Ya maybe my bios version is different (mine is SAG5AR21 which you can find with the command 'dmidecode -s bios-version') or the hardware is a different revision?
I went through a lot of troubleshooting haha.
I even started conversation with QNAP to get a newer bios, though that is still ongoing.
J3455 apparently has signal degradation issues over time and fixed with newer bios, down the rabbit hole...
-
I figured it out.
I had used pci=noacpi to get all drives to be recognized but pcie_port_pm=off is a better option per the the bug report here https://bugzilla.kernel.org/show_bug.cgi?id=196805
-
 1
1
-
-
@Xutho and anyone else that reads this thread later one with questions.
pci=noacpi has huge implications on speed in my testing. I was getting a lot of call traces in my logs and was concerned about long term safety of my data.
Using pcie_port_pm=off instead is far better per the kernel bug report link from earlier, temps are far better as well for all of my stuff. My processor isn't at 100% on one core consistently and instead of 40MB/s parity checks, I get 190MB/s parity checks.
Cheers,
Ash
-
1
-
-
Thanks for the reply @jonp!
I installed 6.9 rc1 and no change. When doing a parity rebuild I still get the problems before. Max 40MB/s, faster when downloading large files from a program in Docker and the Traces are still there.
I did try a few added things to see if I could fix it but neither of them fixed anything.
- Tried Booting into Safe Mode
- Tried Booting with Bios instead of UEFI
Additionally I have issues with where the WebGUI is unresponsive when I start the Parity Check
-
Found this thread:
that suggests reducing md_sync_thresh is there somewhere I can change this in the interface? or a place I can see the current value?
Thanks!
Ash
-
this is great, docker wasn't restarting when I ran this though. Got caught in an unmountable docker.img file. Hopefully that doesn't happen when array starts, it should create the file pretty quick before docker becomes active I'm guessing.
-
It's a QNAP machine, getting new CPU/Mainboard will be next to impossible. I'll just deal with slow parity rebuilds if there's no other solution.
-
I've run a memtest and no issues 100%, i tried a different set of ram.
Trace doesn't go away.
Not sure what to do.
-
Nevermind.... the traces you mentioned are back and the speeds are back down to 30-40MB/s...
-
I think that did it, getting more consistent around 70-80 after reseating. Probably faster when Dockers are down but not fussed about it.
Also seeing my processor cores consistently at more utilization whereas before was stuck around 42% overall with one core at 100%. Probably causing issues there. Appreciate the help.
Cheers,
Ash






DiskSpeed, hdd/ssd benchmarking (unRAID 6+), version 2.10.8
in Docker Containers
Posted
just for anyone wondering about this, I tried running this on a ZFS pool i was testing. I think it can't get access, and no charts were showing up. Destroying the pool and then formatting with gpt etc allows me to test with this.
I'm not sure if it's actually possible to test it with ZFS or alternatives to do so, but I was running on ubuntu to just test.