




alexhalbi
Members
-
Joined
-
Last visited
-
Thats sad, but Thank you anyways!
-
I have got a problem with this docker container. On one of my unraid servers I am unable for days now to reach the web UI with chrome (and any other browser) on my PC, but I can reach it with my phone without problems via wifi. It just redirects to /gui and asks for the password and then loads indefinately. I do not know if it would be very helpful if I upload my docker log, since it is spammed with all info messages from the resilio client. (It created multiple GB logfiles over two days, so I rotate it now to 10MB, this should be fixed too, since the unraid resilio container does not do this, I am using it on another server) Could someone please assist me in what information you would need to diagnose that problem. This is a part of my docker log file, from the time I tried to access the page. I do not know if it is relevant at all, since it writes multiple 100 lines with information about my folders per minute... I removed the Hex code in the brackets, I did not know if it is personal data or not. [20190215 21:25:50.106] PD[5BDB] [DDBA] (a:5): checking tunnel[0x1] connection to 192.168.1.20:27757/TCP [20190215 21:25:51.106] 21TunnelCheckConnection[0x2]: raised error SE_NET_TIMEOUT TunnelCheckConnection: timeout [20190215 21:25:51.106] PD[E773] [B249] (a:2): failed to open tunnel[0x2] to 172.17.0.3:55555/TCP - error: SE_NET_TIMEOUT TunnelCheckConnection: timeout enc: SRP, tunnels: 1 [20190215 21:25:51.106] 21TunnelCheckConnection[0x2][<NULL>] [B249]: destroyed [20190215 21:25:51.106] 21TunnelCheckConnection[0x3]: raised error SE_NET_TIMEOUT TunnelCheckConnection: timeout [20190215 21:25:51.106] PD[590B] [B249] (a:2): failed to open tunnel[0x3] to 172.17.0.3:55555/TCP - error: SE_NET_TIMEOUT TunnelCheckConnection: timeout enc: SRP, tunnels: 1 [20190215 21:25:51.106] 21TunnelCheckConnection[0x3][<NULL>] [B249]: destroyed [20190215 21:25:51.106] 21TunnelCheckConnection[0x4]: raised error SE_NET_TIMEOUT TunnelCheckConnection: timeout [20190215 21:25:51.106] PD[2481] [B249] (a:2): failed to open tunnel[0x4] to 172.17.0.3:55555/TCP - error: SE_NET_TIMEOUT TunnelCheckConnection: timeout enc: SRP, tunnels: 1 [20190215 21:25:51.106] 21TunnelCheckConnection[0x4][<NULL>] [B249]: destroyed [20190215 21:25:51.106] 21TunnelCheckConnection[0x5][<NULL>] [B249]: created outgoing [20190215 21:25:51.106] 21TunnelCheckConnection[0x5][<NULL>] [B249]: Connect to 172.17.0.3:55555 via TCP [20190215 21:25:51.106] PD[E773] [B249] (a:2): checking tunnel[0x5] connection to 172.17.0.3:55555/TCP [20190215 21:25:51.106] 21TunnelCheckConnection[0x6][<NULL>] [B249]: created outgoing [20190215 21:25:51.106] 21TunnelCheckConnection[0x6][<NULL>] [B249]: Connect to 172.17.0.3:55555 via TCP [20190215 21:25:51.106] PD[590B] [B249] (a:2): checking tunnel[0x6] connection to 172.17.0.3:55555/TCP [20190215 21:25:51.106] 21TunnelCheckConnection[0x7][<NULL>] [B249]: created outgoing [20190215 21:25:51.106] 21TunnelCheckConnection[0x7][<NULL>] [B249]: Connect to 172.17.0.3:55555 via TCP [20190215 21:25:51.106] PD[2481] [B249] (a:2): checking tunnel[0x7] connection to 172.17.0.3:55555/TCP [20190215 21:25:54.613] 16TunnelConnection[0x8]: received ping [20190215 21:25:54.614] 16TunnelConnection[0x9]: received ping This is my config:
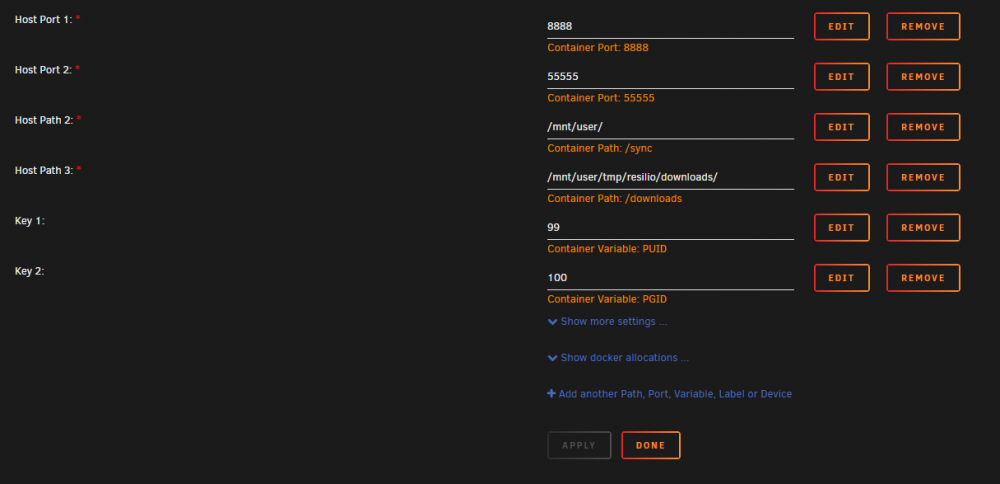
-
Sure, With not working I mean I am unable to start my VM with the Soundcard attached to it. I get following error (with and without the syslinux configuration): Execution error internal error: process exited while connecting to monitor: 2019-02-14T08:18:27.585203Z qemu-system-x86_64: -device vfio-pci,host=00:1f.3,id=hostdev0,bus=pci.0,addr=0x6: vfio error: 0000:00:1f.3: group 13 is not viable Please ensure all devices within the iommu_group are bound to their vfio bus driver. But I cannot add all devices in that IOMMU Group to the VM afaik. Right now I have a workaround running with an USB Sound Card on an USB Controller [1b21:2142] bound to my VM, but I would really like to use the onboard Audio since it is surely better. I also added this to the syslinux file and it works fine. BTW: Is it normal, that the PCI Device to add to the VM does not show up (in the selection thing in the vm options in the screenshot above) after adding the vfio-pci.ids statement to the syslinux file and rebooting? Or is that an unraid bug? After I added it manually in the xml file it is now showing up... syslinux file.txt vm_config.xml
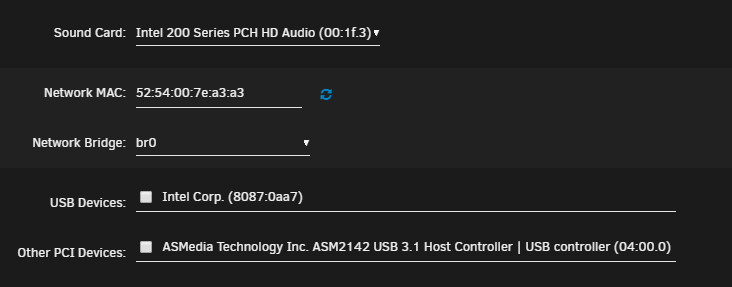
-
I am currently also trying to remap my onboard audio to a Windows VM, but the way you described does not seem to work in my case. I have got an "ASRock - Z370 Professional Gaming i7" with Creative onboard Audio with an i7-8700K. I tried PCIe ACS Override "Downsteam" and "Both" My append line is: append pcie_acs_override=downstream,multifunction vfio-pci.ids=8086:a2f0 modprobe.blacklist=i2c_i801,i2c_smbus initrd=/bzroot And the corresponding IOMMU Group is: IOMMU group 13: [8086:a2c9] 00:1f.0 ISA bridge: Intel Corporation Z370 Chipset LPC/eSPI Controller [8086:a2a1] 00:1f.2 Memory controller: Intel Corporation 200 Series/Z370 Chipset Family Power Management Controller [8086:a2f0] 00:1f.3 Audio device: Intel Corporation 200 Series PCH HD Audio [8086:a2a3] 00:1f.4 SMBus: Intel Corporation 200 Series/Z370 Chipset Family SMBus Controller I hope anyone is able to help me with this, if it is even possible. Thanks to everyone who can help me. IOMMU.txt


