

esaru
-
Posts
23 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by esaru
-
-
30 minutes ago, ghost82 said:
Just remove
Just delete, script changes are resetted at boot
Yes
Thank you!
Some people mentioned that this guide breaks their dockers. Could this be the reason that my jackett docker randomly stopped working? It boots up alright, log seems fine but I can't access the webui.
-
39 minutes ago, ich777 said:
You have to undo basically everything you've done, change the BIOS type to OVMF-TPM in the VM template and then reactivate Windows again.
But I really can't tell if it is working properly after you did this since I've not tested this and that is just a guess.
That's why I don't recommend installing through this method and wait for the official way.
Ok so this is what I need to do?
1. Remove the swTPM binaries from /boot/extra. Do I need to uninstall them somehow? If so, how?
2. Delete the script (or at least change it so that it doesn't run at startup). Do I need to undo any changes made by the script manually or is this solved by just rebooting?
3. Undo the changes in the VM xml.
I'm not really worried about any effects on the VM itself. I can easily just do a clean install if needed. I just want my unraid install to be pristine
")
-
Hey,
I followed the swTPM guide (link below) and installed Windows 11. Could someone explain what parts I need to undo (and how) when the new unraid version hits and we have this functionality built in? I don't have Bitlocker activated.
Really don't want to break anything or leave some problematic stuff behind.
https://www.linkedin.com/pulse/swtpm-unraid-zoltan-repasi/
-
11 hours ago, Kodey said:
I just had this occur on my server. Did you ever figure this out?
Nope, sorry. I had to create a new VM to get rid of this, unfortunately.. I still have no idea what caused the log spam. Please post here if you find a solution!
-
5 hours ago, ljm42 said:
I don't really have a lot more to add. What we know is that that IP address is making repeated unauthenticated connections to the Unraid webgui. The request is "PROPFIND /login HTTP/2.0", when I look up PROPFIND that is related to Webdav.
This is not a standard thing that Windows does
I see. Is there any duct tape solution available? Perhaps changing the nginx conf to just refuse this type of connection or something?
Should I reboot the server when log hits 100%? Are there any risks involved with leaving it at 100%? I can live with not being able to get fresh log messages, but if there are harsher potential consequences I'd be more motivated to adress the issue by reinstalling windows or something.
-
 1
1
-
-
On 5/2/2021 at 11:06 PM, ljm42 said:
*something* on 192.168.3.222 is contacting the server on a regular basis and is being redirected to /login . It is sending a PROPFIND command, looks like that might be related to WebDAV. Does that give you any clues?
I deleted a whole bunch of apps, including Cryptomator which is the only one that I know uses WebDAV. It's still happening. Am I correct to assume that it must be an app/program on my VM that is contacting my servers webui? Could it be some aspect of Windows itself doing this stuff?
Some more instructions for troubleshooting would be very appreciated. -
Your CPU does indeed have the AES-NI instruction set. I'd just go ahead and encrypt!
Intel® AES New Instructions - Yes
-
Tried putting my VM to sleep, just to try something. When the VM is sleeping, this error shows instead:
QuoteMay 5 12:09:16 Tower nginx: 2021/05/05 12:09:16 [alert] 5228#5228: worker process 2208 exited on signal 6
Does this possibly lead to some conclusion?
-
Rebooted tower again, it's still ongoing. Not sure what to do next, I've been shutting down pretty much every app/service I could find in task manager. Let's see if that has an impact, otherwise I'm just clueless.
Edit: it's still happening. Seems like nuking my VM and leaving windows forever is like the only viable option at this point..
-
Could it be the infamous Plex health check? AFAIK that issue is resolved in later versions of Unraid. May I ask why you are not upgrading? It seems like an easy thing to apply if you're having issues.
-
8 minutes ago, ChatNoir said:
Looks like it is still the same local IP trying authenticate 20 time a second. That's out of my wheelhouse.

Hopefully, someone can help you on this.
Thank you for trying! 🙂
-
 1
1
-
-
2 minutes ago, ChatNoir said:
Did you reboot after that ?
There is not way to clear the log, so whether your actions improve things or not, the logs would stay at 100%.
If you did reboot, new diags could have information about what is happening now.
I did reboot the tower around 10 yesterday, however only the VM was rebooted after exiting Cryptomator etc in the afternoon. When I took those measures the log was not full at all, it filled during the late evening/night.
-
On 5/2/2021 at 11:06 PM, ljm42 said:
*something* on 192.168.3.222 is contacting the server on a regular basis and is being redirected to /login . It is sending a PROPFIND command, looks like that might be related to WebDAV. Does that give you any clues?
Yesterday i exited Cryptomator and a bunch of other services for good measure (Veeam, google drive sync). I also uninstalled a bunch of unused apps and updated Windows. No dice, the log is 100% again this morning.
Any other advice/pointers? Is there some additional information I could provide for further troubleshooting? Thanks.
-
51 minutes ago, ljm42 said:
*something* on 192.168.3.222 is contacting the server on a regular basis and is being redirected to /login . It is sending a PROPFIND command, looks like that might be related to WebDAV. Does that give you any clues?
I run Cryptomator, I think it utilizes WebDAV. I’ll check it out!
-
On 4/20/2021 at 7:52 PM, ljm42 said:
In order to keep the Unraid webgui current, the webgui polls the server on a regular basis. If an open page becomes unauthenticated then the individual poll requests will redirect to the login page, which is what we are seeing in the log. Later versions of Unraid will redirect the whole tab to the log script (and thus stop polling) if they detect this situation, but it is possible that there are scenarios that are not detected.
That is the most likely explanation for the log entries you are seeing. The quick fix is to close any open tabs that are pointing to the webgui. If you can't find them, reboot the system at 192.168.3.16
If you want to actually troubleshoot the problem, first confirm that you are running Unraid 6.9.2 and that all plugins are current (there isn't much value in troubleshooting older versions as work has been done in this area.) Then find the tab that is pointed at the webgui, open the browser's developer tools and switch to the network tab. Do not refresh the tab. You should see a new entry being added to the network tab on a regular basis, let me know what it is. Also let me know the url the tab is showing (the part after the hostname at least). Diagnostics would be good too.
It's still recurring after several restarts of both my VM and the tower itself.
The log gets to 100% in like 24 hours and as soon as it's full I get this nagging feeling that I have to restart. What are the actual implications of having a 100% full log, in what way (if any) does it "harm" my servers wellbeing?
-
On 4/20/2021 at 7:52 PM, ljm42 said:
In order to keep the Unraid webgui current, the webgui polls the server on a regular basis. If an open page becomes unauthenticated then the individual poll requests will redirect to the login page, which is what we are seeing in the log. Later versions of Unraid will redirect the whole tab to the log script (and thus stop polling) if they detect this situation, but it is possible that there are scenarios that are not detected.
That is the most likely explanation for the log entries you are seeing. The quick fix is to close any open tabs that are pointing to the webgui. If you can't find them, reboot the system at 192.168.3.16
If you want to actually troubleshoot the problem, first confirm that you are running Unraid 6.9.2 and that all plugins are current (there isn't much value in troubleshooting older versions as work has been done in this area.) Then find the tab that is pointed at the webgui, open the browser's developer tools and switch to the network tab. Do not refresh the tab. You should see a new entry being added to the network tab on a regular basis, let me know what it is. Also let me know the url the tab is showing (the part after the hostname at least). Diagnostics would be good too.
I am running 6.9.2, all plugins updated. The issue started after upgrading to 6.9.2 from the preceding beta version.
Surprisingly the error seems to return even when the browser is closed. I also tried switching from Chrome to Firefox to no avail. I've rebooted many times, both the VM and the tower.
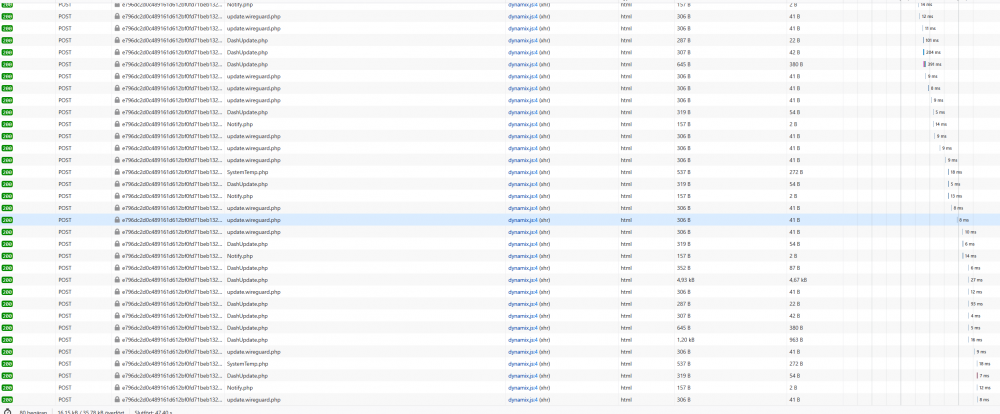
The url is https://e796dc2d0c489161d612bf0fd71beb13294217db.unraid.net/Dashboard
Full error message: (changed to a static ip. 222 instead of 16).
QuoteApr 27 14:46:42 Tower nginx: 2021/04/27 14:46:42 [error] 6002#6002: *106834 limiting requests, excess: 20.041 by zone "authlimit", client: 192.168.3.222, server: , request: "PROPFIND /login HTTP/2.0", host: "e796dc2d0c489161d612bf0fd71beb13294217db.unraid.net"
The more recent errors occured with no webgui tab open.
Thank you!
-
1
-
-
12 hours ago, ljm42 said:
The computer with IP 192.168.3.16 is repeatedly trying to connect to your server. Possibly a stale version of the webgui open, find that computer and close the browser.
Right, I forgot to mention this IP belongs to my workstation which is a VM on the server. I made sure to close all tabs related to unraid, but it seems the errors continue anyway. I use the VM pretty much all day and I like to keep my browser open. I guess closing the browser completely or powering down the VM could be a step for troubleshooting but it won't really fix the issue, no? I am positive that the error occurs regardless of webgui tab being closed or open and logged in to.
Further assistance would be very appreciated.
-
1
-
-
The last week my log keeps filling to 100% with these errors:
Apr 18 04:30:10 Tower nginx: 2021/04/18 04:30:10 [error] 6058#6058: *800608 limiting requests, excess: 20.366 by zone "authlimit", client: 192.168.3.16, server: , request: "PROPFIND /login HTTP/2.0",
I have no idea how to troubleshoot the issue and would love some guidance. I tried searching the forums and found a few others mentioning the same issue but no solution has been posted.
-
1
-
-
22 minutes ago, johnnie.black said:
Then 3200Mhz is fine and supported, assuming no failing DIMMs.
Okay. I'd suppose a memtest is in order?
-
42 minutes ago, johnnie.black said:
It's still overclock, except for 3rd gen Ryzen with only 2 DIMMs.
If the corruption is happening on reads it will be fixed once the hardware problem is resolved, but note that there could still be undetected corruption that happened at write time, since the checksum will match the corrupted data.
Not sure what that means for me. I do have 3rd gen Ryzen, 2 sticks of ram. I didn't really understand all the information in the link you provided before, the table with ranks etc. It says 3200mhz is officially supported for both single and dual rank, 2 of 2 and 2 of 4(??). All I know is that I have a x570 aourus elite mobo with 4 ram slots where I put 2x8gb 3200 mhz ram.
About scrub, I ran it through the unraid GUI and got the following result:Error summary: csum=1 Corrected: 0 Uncorrectable: 1 Unverified: 0How do I run scrub to find out which specific files are corrupted?Checked the log after scrubbing, it's just a random movie that is corrupted. I'm gonna go ahead and delete it.
Once again, thanks for helping.
-
27 minutes ago, johnnie.black said:
Checksum failures are usually a sign of data corruption, start by looking a this to see if your RAM is overclocked, which is a known source of data corruption with Ryzen.
Well it's set in BIOS to xmp profile one which is 3200mhz, the "stock" rating of my ram sticks (Vengeance 2x8gb 3200mhz cl16). I did however have some memory stability issues in the past which I thought I ironed out, ran a one pass memory test and no problems. I noticed there was a recent bios update that adresses ram compatibility, I just flashed it.
So, I'm going to make sure that my ram runs well. What about the corruption, is there anything I should do about that? What are the implications of this corruption?
Thanks!
-
Hey,
Been getting these warnings in my log recently.
QuoteMar 22 08:43:03 Tower kernel: BTRFS warning (device dm-3): csum failed root 5 ino 5608093 off 347480064 csum 0x42dde7c7 expected csum 0x69d41968 mirror 1
I think that dm-3 is my cache drive (whole array is BTRFS though) which is a 1tb Samsung 970 evo plus.
I have no idea what this means. Few days ago I had a scary event. Without thinking removed the usb keyboard that was assigned to my Windows 10 vm while it was running. This crashed the VM, the whole VM page was unresponsive. After a reboot I could start the VM again, however my docker.img was gone (no containers in the Docker tab). I recreated my dockers + ran a parity check (0 errors) and after that I have not encountered any further problems, except for these csum errors in the log. I am not 100% that they started after the mentioned event, but it seems very likely.
Any ideas?



Syslog errors after moving VM to Unassigned Devices SSD
in General Support
Posted
Only thing that worked for me was nuking my VM and doing a clean windows installation. Quite unsatisfying as far as solutions go..