




PrisonMike
Members
-
Joined
-
Last visited
-
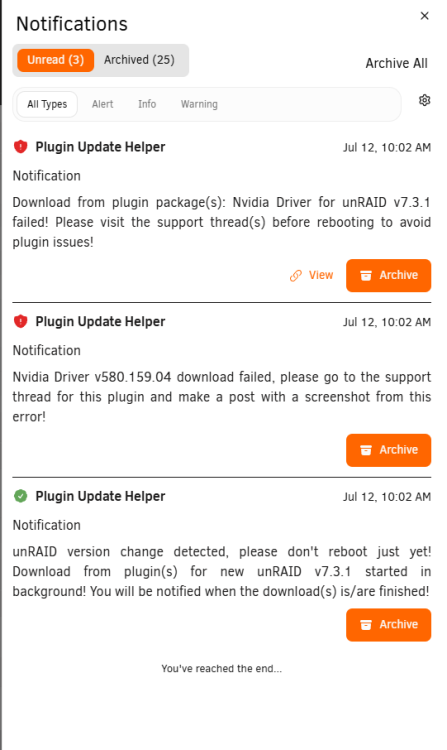
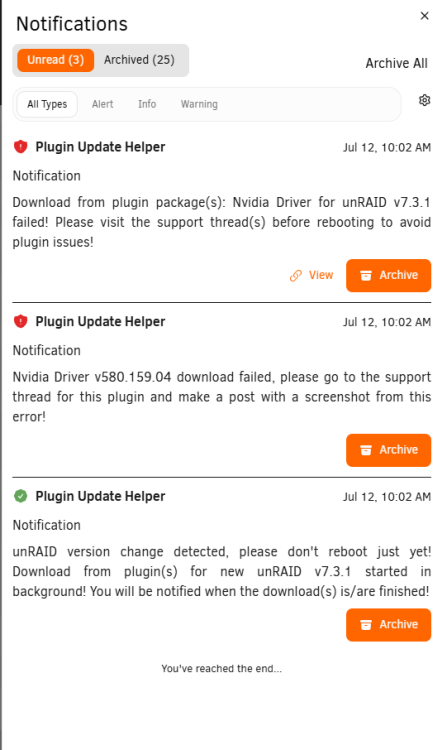
Hello, after trying to update Unraid, I am getting this notification from the alert saying to post my screenshot here. Not sure what else to do. Diagnostics attached. Thanks tower-diagnostics-20260712-1005.zip
-
Hello, plex has recently (a month or two ago) stopped playing any media. I just get the spinning wheel of death. I am using a gtx1070 to transcode. I cant watch any media locally or remotely. *Edit, attached diagnostics Also, got this error when updating unraid to see if that would fix it. Aso updated diagnostics. tower-diagnostics-20260712-1005.zip
-
Got it. It seems like this issue happens about every 12-18 months. Is there anything I can do to prevent it?
-
OK, looks like I got everything. Plex appdata was corrupt unfortunately. So were some other appdata folders. I changed my cache pool to ZFS raid1. So in the future, would I just be able to swap out a drive like the array and not lose data?
-
OK, I changed appdata to cache and then move to array. I want the appdata to only be on the cache, so should I set it to "mover takes no action"? docker appdata folder is set to /mnt/cache/appdata/
-
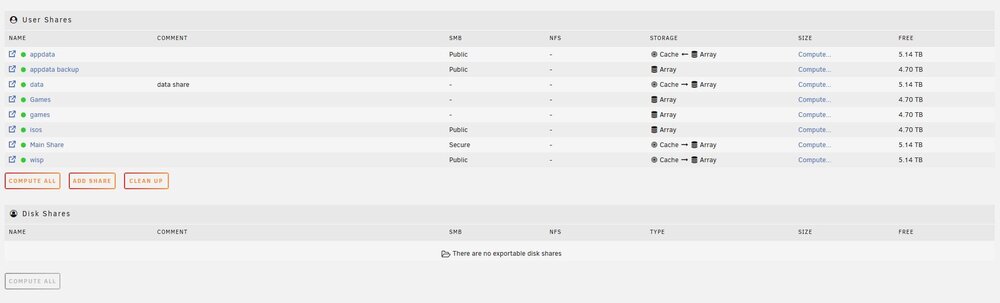
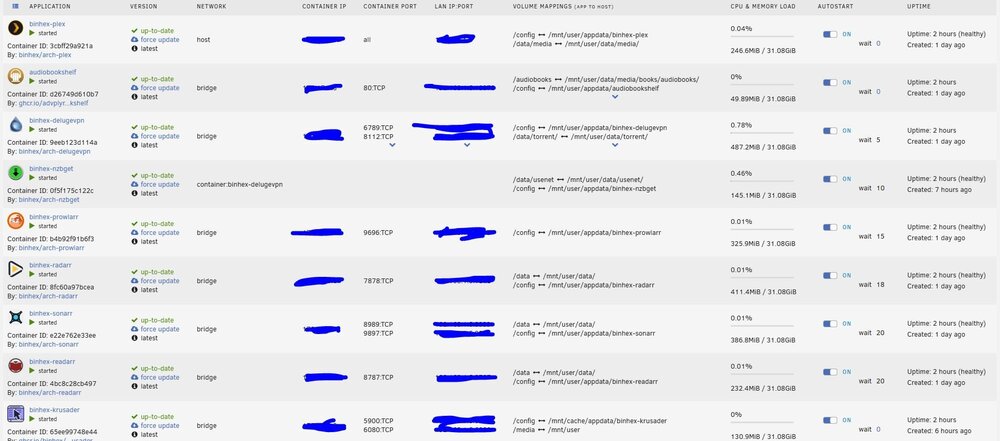
Hello, I just wanted to double check and see if my paths/shares are setup to be optimal. I want my downloads to be downloaded to the cache and then moved to the array. Right now, its looking like the files are downloading directly to their appropriate folders, but the torrents and usenet folders are located on the array and not the cache pool. I have my files setup with the suggested trash file folder structure. data -torrents --books --movies --series -usenet --incomplete --complete ---books ---movies ---series -media --books --movies --series please advise any improvements I could make. Thanks!
-
Nevermind, I cleared my cookies and it worked.
-
Hello, I recently lost my cache drive and plex db. I deleted the appdata folder and re-downloaded plex. I am now getting this error when I try to start plex server. '--serverUuid' should follow immediately after the equal sign
-
OK, can you give me some guidance on how to move/ copy the data to the array? Thanks!
-
I also tried to use CA backup/ restore, but it is telling me that there are no docker containers to backup.
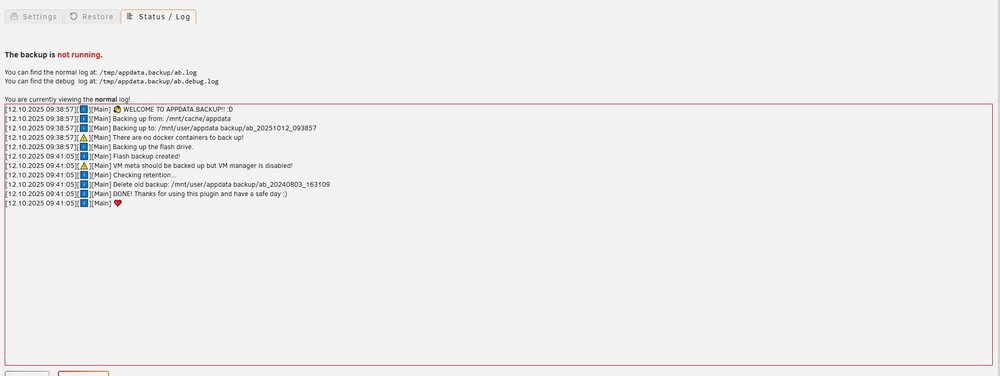
-
Using the built in tool in unraid shares. This is the error that I get.
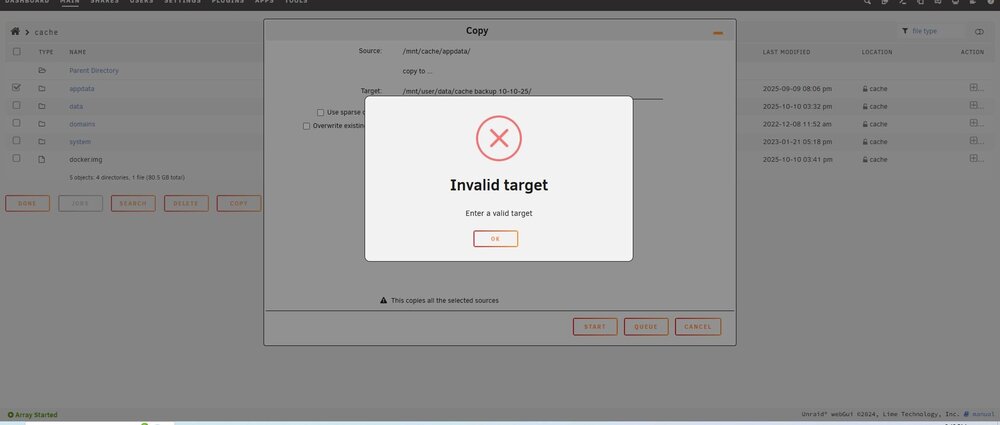
-
OK, I am trying to move it from the cache pool to the array and it says that there is an invalid target. Im not sure what I am doing wrong. Thanks
-
OK thanks. I have attached the diagnostics. tower-diagnostics-20251010-1434.zip
-
I ran the command in the terminal and got another error. Not sure if I am doing something wrong or not "root@Tower:~# btrfs balance start -f -dconvert=single,soft -mconvert=single,soft /mnt/cache ERROR: error during balancing '/mnt/cache': Structure needs cleaning There may be more info in syslog - try dmesg | tail"
-
I opened a terminal and ran the command. I got an error "root@Tower:~# btrfs balance start -dconvert=single,soft -mconvert=single,soft /mnt/cache ERROR: error during balancing '/mnt/cache': Invalid argument There may be more info in syslog - try dmesg | tail" tower-diagnostics-20251010-1159.zip






