

Civrock
-
Posts
20 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by Civrock
-
-
39 minutes ago, Rourke said:
Sure! I'm using the PUID and PGID environment variables so that all files created from this qBittorrent are from my user (user and group ID 1000). This way I can easily browse, move or even edit files through my server (host) without going into the container itself. However I've mounted the volume ~/downloads:/downloads which was still a folder owned by root on my host.
So basically I did a id command on my host, saw user and group id 1000, did sudo chown -R 1000:1000 ~/downloads, restarted the container and it could read and write to my /downloads folder.
So my individual user account shows as id 1000, tried that and I am still getting the same issue you had above. I reset the permissions to 99:100 which is the default for most containers and that still did not work. The logs are still showing permission denied error for me.
Edit: I found the problem. It wasn't permissions for me, but rather one of the paths in the container was modified so it was trying to save to an invalid path. Same looking error, but different solutions.
Thanks for your elaboration and help @Rourke-
 1
1
-
-
On 6/21/2020 at 2:00 PM, Rourke said:
A simple sudo chown -R user:user ~/downloads fixed it.
Can you elaborate a bit on this part?
I know how to navigate to what folder I need. I know what chown -R does. But I cannot figure out how to find which user I need to change permissions to. -
3 hours ago, BrambleGB said:
You probably haven't rebuild the container from scratch, and it was pulling it from cache. You can try using docker build with --no-cache --pull
I believe the NODE_LOCALE fix would also require a rebuild? Since the environment variables are captured by webpack at build time, which then isn't updated if the user changes it.
1. Create the folder where you want to put the config file. I will use "/mnt/user/configs/openeats" Open the unraid console and type "mkdir -p FOLDER_NAME"
2. Create the "default.conf" file inside that folder. In the unraid console, type "touch FOLDER_NAME/default.conf"
3. Copy my current configuration file from https://pastebin.com/CaPikhGr to a text editor and set the client_max_body_size (im using 40MB for no reason)
4. Copy the content to the default.conf file you created. You can use vi, or echo, or cat. Quick way with echo is running the command "echo "PASTE THE CONTENT HERE, DON'T FORGET QUOTATION MARKS" > FOLDER_NAME/default.conf"
5. Edit the openeats container, select "Add another Path, Port, Variable, Label or Device", choose path. Name doesn't matter, container path is "/etc/nginx/conf.d/", and host path is "FOLDER_NAME"
6. Restart the container and the new configuration should work.
You may also have to edit the LetsEncrypt configuration, but there are other tutorials for that.
Thank you so much for this!
-
On 5/28/2020 at 7:48 AM, BrambleGB said:
I bashed in, copied the default.conf, and create my own default.conf (with the added client_max_body_size inside the http {} braces).
Then I mounted that folder (e.g. /mnt/user/configs/openeats/) to /etc/nginx/conf.d/ and restarted the container.
Ideally nginx can be removed, as people already run it separately.
You also have to remember to change it if you're running an extra nginx container (e.g. the LetsEncrypt one)On 5/28/2020 at 8:08 AM, bobokun said:Thank you! I did exactly as you recommended and it worked perfectly. Now I don't have a limit on the image size anymore.
")
Can either of you, or anyone for that matter, provide a step by step guide on how to bash in and made these modifications? I am pretty new to using linux so the commands are kinda foreign to me. I found the relvant "client_max_body_size" within my letsencrypt docker but I cannot figure out how to make it happen in this container.
-
Okay, so I ran xfs_repiar -v on both disks and they both had issues with the primary crc, said that there were pending changes to the log and I should mount first before re-running the repair tool. When I mounted them, both showed up normally and rebuild started.
The wording of the repair report made it seem like (at least to me as a layperson in this area) I needed to mount and then immediately run the repair again. Since both disks showed up normally, should I just let the rebuild run, or do I need to stop and run the repair again? I feel like the right answer here is to let the rebuild run now, but I just want to be sure.
Thanks again for your time.
-
Thanks for your time guys, I will just go ahead and stop it now and attempt to repair the filesystems. Will update if I have more issues or make it through that.
-
Something caused my server to restart this morning and I woke up to find two drives with the Unmountable: No file system statuses. Here is where I messed up big time. I stopped the array to restart in maintenance mode to run a smart check of the drives and go from there but accidentally started in regular mode which initiated a parity rebuild...
I have a found a few threads with this same issue and they all point towards the filesystem needing to be repaired. Assuming I already have not jacked everything up, will letting the parity rebuild finish overwite data on those drives or corrupt the parity data? Should I stop it? It also seems to have an unusually long estimated time at approximately 6 days vs. the normal 1 day. I attached logs and a screenshot.
Both drives are on the same power / sata hotswap bay so I think the original issue may be related to that because it seems weird for two drives to fail at the same time without something common between them.
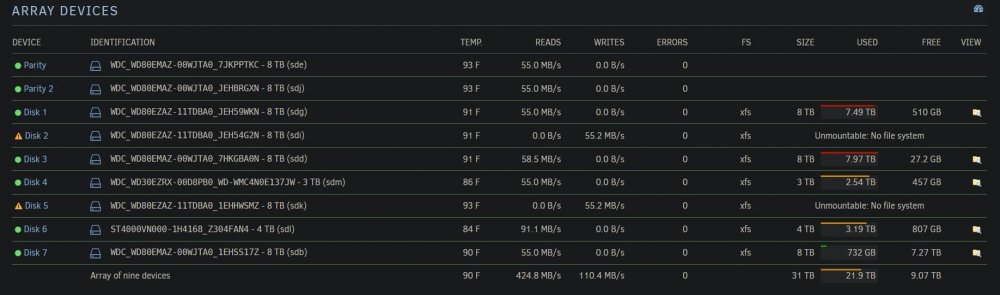
-
Right on. Thanks for the explainations and your patience. I will get to reading!
-
8 hours ago, johnnie.black said:
This is the problem, you're using 2 different size devices on the raid1 cache pool, despite the GUI showing free space you don't have any, since only the size of the smallest device is usable in raid1.
Well, crap. I was going completely off what the GUI said because I thought it was a raid 0 configuration 😕 makes sense that I am having this issue if it is raid1.
So, I have a few questions:
- I have the appdata and docker shares set to prefer which I thought would allow the docker service to write to the array in the event that the cache was full. Is that not the case here?
- What is the best way to go about replacing the smaller drive with a larger one so that I have 2 drives of the same size? Since it is in a mirror configuration, do I just replace the the smaller drive and let it rebuild or is it more complicated than that?
- Once I get everything sorted, is there any way to turn the cache pool into a raid0 configuration in order to get more performance out of it? I am already backing up dockers and appdata onto the main array regularly so losing cheap cache drives would not be the end of the world for me?
-
Docker service is suddenly failing to start. It is set to use the cache. No SMART errors on the cache array and no errors on scub. 131GB free space.
I am getting many errors like so when starting the Docker service:
QuoteMar 2 16:42:43 MediaVault kernel: BTRFS info (device loop2): has skinny extents
Mar 2 16:42:43 MediaVault kernel: lo_write_bvec: 74 callbacks suppressed
Mar 2 16:42:43 MediaVault kernel: loop: Write error at byte offset 56836096, length 4096.
Mar 2 16:42:43 MediaVault kernel: loop: Write error at byte offset 65273856, length 4096.
Mar 2 16:42:43 MediaVault kernel: loop: Write error at byte offset 69304320, length 4096.
Mar 2 16:42:43 MediaVault kernel: loop: Write error at byte offset 69844992, length 4096.
Mar 2 16:42:43 MediaVault kernel: loop: Write error at byte offset 98959360, length 4096.
Mar 2 16:42:43 MediaVault kernel: print_req_error: 74 callbacks suppressed
Mar 2 16:42:43 MediaVault kernel: print_req_error: I/O error, dev loop2, sector 111008
Mar 2 16:42:43 MediaVault kernel: loop: Write error at byte offset 100253696, length 4096.
Mar 2 16:42:43 MediaVault kernel: btrfs_dev_stat_print_on_error: 74 callbacks suppressed
Mar 2 16:42:43 MediaVault kernel: BTRFS error (device loop2): bdev /dev/loop2 errs: wr 1, rd 0, flush 0, corrupt 0, gen 0
Mar 2 16:42:43 MediaVault kernel: loop: Write error at byte offset 100696064, length 4096.
Mar 2 16:42:43 MediaVault kernel: print_req_error: I/O error, dev loop2, sector 127488
Mar 2 16:42:43 MediaVault kernel: loop: Write error at byte offset 103006208, length 4096.
Mar 2 16:42:43 MediaVault kernel: BTRFS error (device loop2): bdev /dev/loop2 errs: wr 2, rd 0, flush 0, corrupt 0, gen 0
Mar 2 16:42:43 MediaVault kernel: print_req_error: I/O error, dev loop2, sector 135360
Mar 2 16:42:43 MediaVault kernel: BTRFS error (device loop2): bdev /dev/loop2 errs: wr 3, rd 0, flush 0, corrupt 0, gen 0
Mar 2 16:42:43 MediaVault kernel: print_req_error: I/O error, dev loop2, sector 136416
Mar 2 16:42:43 MediaVault kernel: loop: Write error at byte offset 325271552, length 4096.
Mar 2 16:42:43 MediaVault kernel: BTRFS error (device loop2): bdev /dev/loop2 errs: wr 4, rd 0, flush 0, corrupt 0, gen 0
Mar 2 16:42:43 MediaVault kernel: print_req_error: I/O error, dev loop2, sector 193280
Mar 2 16:42:43 MediaVault kernel: BTRFS error (device loop2): bdev /dev/loop2 errs: wr 5, rd 0, flush 0, corrupt 0, gen 0
Mar 2 16:42:43 MediaVault kernel: loop: Write error at byte offset 333709312, length 4096.
Mar 2 16:42:43 MediaVault kernel: print_req_error: I/O error, dev loop2, sector 195808
Mar 2 16:42:43 MediaVault kernel: BTRFS error (device loop2): bdev /dev/loop2 errs: wr 6, rd 0, flush 0, corrupt 0, gen 0
Mar 2 16:42:43 MediaVault kernel: print_req_error: I/O error, dev loop2, sector 196672
Mar 2 16:42:43 MediaVault kernel: BTRFS error (device loop2): bdev /dev/loop2 errs: wr 7, rd 0, flush 0, corrupt 0, gen 0
Mar 2 16:42:43 MediaVault kernel: print_req_error: I/O error, dev loop2, sector 201184
Mar 2 16:42:43 MediaVault kernel: BTRFS error (device loop2): bdev /dev/loop2 errs: wr 8, rd 0, flush 0, corrupt 0, gen 0
Mar 2 16:42:43 MediaVault kernel: print_req_error: I/O error, dev loop2, sector 635296
Mar 2 16:42:43 MediaVault kernel: BTRFS error (device loop2): bdev /dev/loop2 errs: wr 9, rd 0, flush 0, corrupt 0, gen 0
Mar 2 16:42:43 MediaVault kernel: print_req_error: I/O error, dev loop2, sector 651776
Mar 2 16:42:43 MediaVault kernel: BTRFS error (device loop2): bdev /dev/loop2 errs: wr 10, rd 0, flush 0, corrupt 0, gen 0
Mar 2 16:42:43 MediaVault kernel: BTRFS: error (device loop2) in btrfs_commit_transaction:2259: errno=-5 IO failure (Error while writing out transaction)
Mar 2 16:42:43 MediaVault kernel: BTRFS warning (device loop2): Skipping commit of aborted transaction.
Mar 2 16:42:43 MediaVault kernel: BTRFS: error (device loop2) in cleanup_transaction:1860: errno=-5 IO failure
Mar 2 16:42:43 MediaVault kernel: BTRFS info (device loop2): delayed_refs has NO entry
Mar 2 16:42:43 MediaVault kernel: BTRFS: error (device loop2) in btrfs_replay_log:2281: errno=-5 IO failure (Failed to recover log tree)
Mar 2 16:42:43 MediaVault root: mount: /var/lib/docker: can't read superblock on /dev/loop2.
Mar 2 16:42:43 MediaVault kernel: BTRFS error (device loop2): open_ctree failed
Mar 2 16:42:43 MediaVault root: mount errorI have attached logs. Given that I have no drive errors, and lots of free space, am I probably looking at a corrupted docker image here?
Edit: Doing a lot of googling, it seems that these errors are probably related to docker corruption from one thing or another.
Also, is there anything I can do in order to get a response and or help from someone? I am kinda new asking for support on the forums but over the last year I have made several posts requesting assistance and I never get so much as a reply. Is there something else I need to be doing in order to get some help?
-
I am getting lots of errors like this:
QuoteFeb 22 00:13:35 MediaVault nginx: 2020/02/22 00:13:35 [error] 4190#4190: *121 upstream timed out (110: Connection timed out) while reading response header from upstream, client: 192.168.1.5, server: , request: "POST /webGui/include/DashUpdate.php HTTP/2.0", upstream: "fastcgi://unix:/var/run/php5-fpm.sock", host: "928ff7e263d1fbd5f5cbb5f6bbc6e017bbde0929.unraid.net", referrer: "https://hash.unraid.net/Dashboard"
- These errors seemed to be preceded by a clock sync error and my logs also have the wrong time associated with them (2 hours later than when they were created)
- The dashboard is failing to load completely and I am dealing with unclean shutdowns.
- Took 20 minutes to restart and over an hour to fully shutdown after creating the log last night.
- While I had access to the dashboard all the cores on the two cpus were under quite a lot of load which I have never really seen outside of plex doing multiple transcodes.
- Server was very slow and unresponsive at times while it was running.
- WeGUI works fine as long as the array is not started but I know not starting the array pretty much removes 99% of the functionality of the system so there is not much to go wrong there.
Edit: It seems to be related to a docker container. When I turn on docker but prevent all containers from starting everything goes well. So I guess I am gonna have to go through and test each one to find out where the problem is. Any help with reading the logs would be much appreciated.
Logs are attached.
-
So my container automatically updated on me and I could not log in at all. I tried removing the WebGUI\Password part as suggested a few pages ago and login with admin:admin and that did not work. Deleted the .conf file to let it regenerate and that didn't work. Tried reverting to the previous version with the old .conf file and that did not work.
How do I go about regaining access to the WebGUI? The container is running fine other than that little problem...
-
How do I go about routing my client's traffic out of the internal docker subnet to my network's subnet in bridged mode (only mode I could get working)? All my network subnets for unraid are defualt so the openvpn server assigns clients onto the 172 subnet but my network is on the 192 range. Clients can access anything on the unraid server, as well as the gateway for the 192 subnet, but cannot ping anything else in the 192 range. I am using an Edgerouter X as the gateway and the unraid server on the other side of a UniFi switch in mostly default configuration as far as routing is concerned.
The specific option which was mentioned in SpaceInvaderOne's updated video under configuration > vpn settings > routing > specific the private subents to which all clients should be given access does not seem to work in my situation. I have been battling with this for a few weeks now trying to figure it out on my own but anything I change that intuitively makes sense just breaks the server and I have to reinstall and reconfigure it to try again.
-
5 minutes ago, bubo said:
Left click on your Docker and choose Console.
Don't forget to exit out of the console when you're done, or the connection will remain open inside the Docker.
Man, this is embarrassing. Where do I go from there? I typed help to see what commands are available and there is nothing like what the server should have available. If I am not mistaken, which I just may be, that is the console for the docker and not the "in game" console? I am trying to promote users to admin since the server settings are not working in regards to admins.
-
Sorry since it looks like this has been asked a million times but I am having difficulty figuring it out... how do I access the console for the Factorio server? I get that you need to remote console into it, but how exactly do I go about that? Very sorry if this is some really basic stuff.
-
I am having some issues (probably configuration on my end) with the Factorio docker. I can get everything working great when connecting to it on my LAN, and I can get the server to broadcast in the public games listing from Factorio.com, but I cannot connect to my server remotely even with ports forwarded. Has anyone ran into this issue with the Factorio server or any other one for that matter that might help?
I am using an Edgerouter x, everything on the same subnet, ports forwarded to the Factorio server, I have tried configuring the server in Bridge, Host, and custom w/ static ip, and still no luck. Maybe a firewall or NAT issue? Most of the stuff I can find on google is solved because someone forgot to forward the ports but that is not my case here.
EDIT: Nevermind. I actually used my brain for a minute and realized it is a NAT thing. Connecting to my VPN first and then trying to connect through the matchmaking works as it should. 🤦♂️
-
How would I go about verifying that I am connected to my VPN? Based on some initial mistakes I made on setup and reading the documentation I understand that the webUI would be inaccessible if it was not connected, but I just wanted to know if there are other ways to verify.
-
10 hours ago, wgstarks said:
Is Deluge really showing no active torrents? My guess is that you are seeding. You can configure the bandwidth used for this in the app settings.
It is showing active torrents, but most of them don't have anything going on in the "Up Speed" column and their "Uploaded" stat is extremely small, most showing less than 50MB uploaded compared to the many tens of GB downloaded. There are sporadic uploads at varying times, but nothing sustained and nothing large enough to cap out my transfer bandwidth.
When I go into the preferences to set global and per-torrent seed caps of zero or anything else it is still going full tilt on the transfer rate measured at my Edgerouter.
Edit:
What are the chances / is it even possible that I have something configured improperly and instead of writing directly to disc, my server is sending all that data across the network back to itself to write to the array? When the array is writing at full speed the transfer rate is maxed and when the array is writing at a slow speed, the internet transfer is around the same speed. Sounds insane, and I am not even sure it is possible. But bandwidth seems to be increasing / decreasing with array write speed.That really doesn't make a whole lot of sense. -
Hi there, I am completely new to just about everything associated with unRaid and the Docker system so I am probably just having a fundamental misunderstanding about how this stuff works, but I am noticing something weird nonetheless. I got everything up and running with my PIA account linked to deluge and everything seems to work okay from the unraid/deluge side of things, but when deluge is running it is somehow maxing out my upload connection even though nothing is actually being uploaded. It seems to be tied to the download rate, for example, if I limit deluge to 5MB/s down, then the upload sits around the same speed. It does this all the way until it reaches the limit at around 8MB/s up, so when I am running full bandwidth downloading my upload is constantly capped.
Is there something I am completely misunderstanding about my setup or is there something really weird going on here?
Thanks for your time.


Intermittent Shutdowns
in General Support
Posted · Edited by Civrock
After about 2 years of running good I am experiencing random shutdowns. At first I thought it was my PSU because I was using an old EVGA bronze from like 15 years ago... Replaced that with a new one and the issue is still continuing. I ran memtest for well over 24 hours and that passed with no issues as well. The system is also connected to an UPS and it has been tested with full poweroutages thanks to construction so I think I can rule that out for the most part. My next step, unless you guys can find something in the logs pointing towards an issue, was going to be setting up a vm and stress testing the cpus. I think that might not really test them properly if I remember how hypervisors assign cpu usage. They were installed recently, but have been function fine for about 6 months. Who knows what kind of lottery I rolled with used server parts, though.
Attached diagnostics from after reboot.
I also started keeping a syslog record with the syslog server feature since this started happening.
This is what the log looked like in the hours before the shutdown:
mediavault-diagnostics-20200721-2131.zip