




M0CRT
Members
-
Joined
-
Last visited
Everything posted by M0CRT
-
Jorge...Working. Note to self, do not expect the disk to be presented in exactly the same way via a cra*py USB3 dock > SATA interface. As soon as I returned the disk to a direct SATA3 interface on the M/B...it returned as a 'ZFS' partition rather than a 'member ZFS' partition and it imported / mounted with a blink of an eye. Sure useful to note for all. Get the basics right. Thanks again and apologies. Mo
-
Fair enough. I wonder also if attempting to access the drive via a USB dock when I created it on an internal SATA port is going to cause issues. Thanks for your response and all your amazing support you provide for everyone. Mo
-
Hi Jorge. I think I may have created on command line.. Apologies for not replying sooner...How strange. Would I be able to recover files with a recovery tool?
-
Hi Jorge...Sorry for the delay in responding. root@server:~# fdisk -l /dev/sdi Disk /dev/sdi: 2.73 TiB, 3000592982016 bytes, 732566646 sectors Disk model: 001-1ER166 Units: sectors of 1 * 4096 = 4096 bytes Sector size (logical/physical): 4096 bytes / 4096 bytes I/O size (minimum/optimal): 4096 bytes / 33550336 bytes Disklabel type: dos Disk identifier: 0x4226f2f1 Device Boot Start End Sectors Size Id Type /dev/sdi1 1 4294967295 4294967295 16T ee GPT
-
'No available pools to import' when attempted. It was created on the Unraid array around 3 months ago...prior to 7 upgrade.
-
/dev/sdi: TYPE="zfs_member" PTTYPE="PMBR". is the disk...obviously. :-)
-
JorgeB...you are a star. root@server:~# blkid /dev/sda1: LABEL_FATBOOT="UNRAID" LABEL="UNRAID" UUID="2732-64F5" BLOCK_SIZE="512" TYPE="vfat" /dev/md1p1: UUID="51354d8b-de02-4b42-affd-6135b2c3c012" BLOCK_SIZE="512" TYPE="xfs" /dev/md2p1: UUID="d780ea51-40b4-4fb8-8f8d-d43e75e8b8be" BLOCK_SIZE="512" TYPE="xfs" /dev/md3p1: UUID="6ff58b58-4324-4f1f-9b39-36c69ca5498f" BLOCK_SIZE="512" TYPE="xfs" /dev/md4p1: UUID="79f41d3e-1b61-4c6c-a4c5-44f58b7c9f8f" BLOCK_SIZE="512" TYPE="xfs" /dev/loop1: BLOCK_SIZE="131072" TYPE="squashfs" /dev/nvme0n1p1: LABEL="SSD2" BLOCK_SIZE="512" UUID="129E4F7A9E4F557F" TYPE="ntfs" PARTUUID="e5c144bb-01" /dev/sdi: TYPE="zfs_member" PTTYPE="PMBR" /dev/nvme2n1p3: BLOCK_SIZE="512" UUID="9E16D8BC16D8969D" TYPE="ntfs" PARTLABEL="Basic data partition" PARTUUID="a61fa55f-f6ae-47c1-bab6-0205eca42e87" /dev/nvme2n1p1: UUID="34CC-A658" BLOCK_SIZE="512" TYPE="vfat" PARTLABEL="EFI system partition" PARTUUID="3215fab5-ac51-4177-ab85-ae023dec5eca" /dev/loop2: UUID="06090d70-8413-416b-a356-b1de5400af34" UUID_SUB="0ce29b88-ec2c-4181-a625-22bef20a7291" BLOCK_SIZE="4096" TYPE="btrfs" /dev/sdg1: LABEL="cache" UUID="11731246308525138860" UUID_SUB="5631085809690507914" BLOCK_SIZE="4096" TYPE="zfs_member" PARTUUID="5cecabc3-01" /dev/loop0: BLOCK_SIZE="131072" TYPE="squashfs" /dev/nvme1n1p2: LABEL="SSD2" BLOCK_SIZE="512" UUID="9EFAE9F3FAE9C81B" TYPE="ntfs" PARTLABEL="Basic data partition" PARTUUID="4be98a8a-fd5e-4270-bbb8-a8daaf16d183" /dev/loop3: UUID="000ee9d6-418c-4ffb-a250-19b192adfb04" UUID_SUB="f3543e23-3229-4f00-98e2-a64649b9d2c4" BLOCK_SIZE="4096" TYPE="btrfs" /dev/sdh1: LABEL="cache" UUID="11731246308525138860" UUID_SUB="15774442455614836752" BLOCK_SIZE="4096" TYPE="zfs_member" PARTUUID="5cecabc1-01" /dev/nvme2n1p2: PARTLABEL="Microsoft reserved partition" PARTUUID="d6062404-96f5-417f-a41c-c9c3b46bc4d7" /dev/nvme1n1p1: PARTLABEL="Microsoft reserved partition" PARTUUID="226bc947-3397-452d-83e3-8ba10168d07c" root@server:~# zpool import no pools available to import root@server:~# zpool status pool: cache state: ONLINE status: Some supported and requested features are not enabled on the pool. The pool can still be used, but some features are unavailable. action: Enable all features using 'zpool upgrade'. Once this is done, the pool may no longer be accessible by software that does not support the features. See zpool-features(7) for details. scan: scrub repaired 0B in 00:03:58 with 0 errors on Sun Sep 29 01:03:59 2024 config: NAME STATE READ WRITE CKSUM cache ONLINE 0 0 0 mirror-0 ONLINE 0 0 0 sdg1 ONLINE 0 0 0 sdh1 ONLINE 0 0 0 errors: No known data errors
-
Hi all Version 7. B2.. Looking to import a ZFS Pool that was created only on a single disk...and is separate from my main array (XFS) / cache (ZFS) Unassigned Devices shows FS as 'ZFS Member' and 'Partition'. I was expecting to be able to 'ZFS Import' but no pools are found. Do I need to off-line my array in some way? ZFS Master and Unassigned Devices + Unassigned Devices + installed. Thank you so much. Mo
-
Perfect Jorge. Worked like a charm! :-). Thanks
-
I have checked the 'cctv big disk' and it looks like it may be fully allocated: image: vdisk4.img file format: raw virtual size: 500 GiB (536870912000 bytes) disk size: 500 GiB Will the resparse still help here? i.e. am I not already allocating all the disk? XML of VM...noting the VM is a 'Synology'... <disk type='file' device='disk'> <driver name='qemu' type='raw' cache='writeback'/> <source file='/mnt/user/cctv-vm/Synology/vdisk4.img'/> <target dev='hde' bus='sata'/> <address type='drive' controller='1' bus='0' target='0' unit='4'/> </disk>
-
That's a great idea Jorge. Thanks. Think that's what the issue may be...I've run the balance on the BTRFS and i'm in a good place there. You are right, it's likely to be the 'allocation' of the images associated with my VM. I'll cp them back with 'resparsify'
-
I'll take a look :-). Thanks! UPDATE: Great article...thanks Kilrah! Yes...it's not as 'simple' as it may initially seem! :-)
-
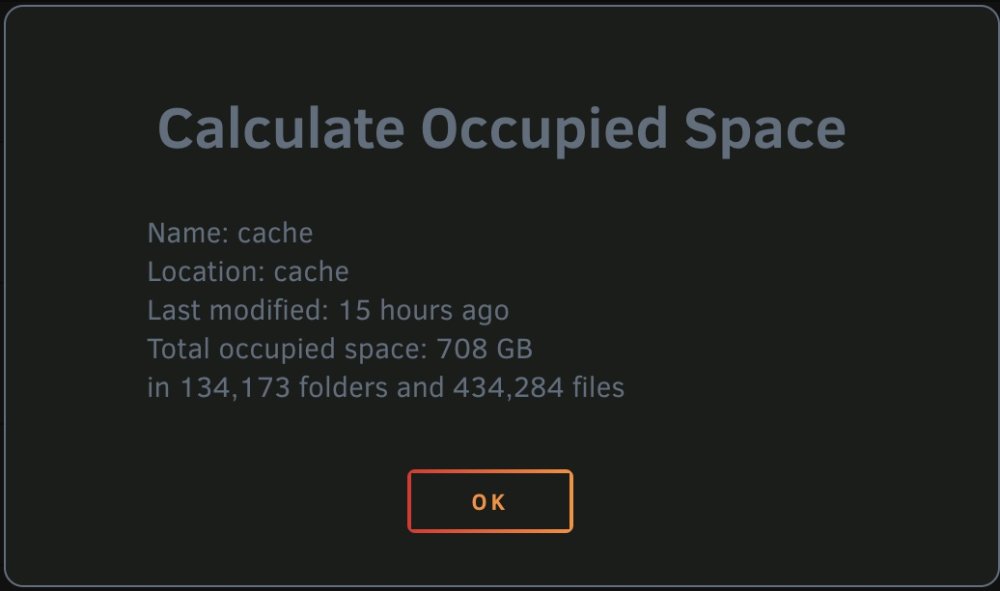
As a follow up. Calc in Unraid shows 708Gb 'occupied' but on summary page, only 70/80Gb Free...Is the BTRS volume potentially reserving some space? Surely this should be reported as approx. 290Gb free?
-
Thanks for your feedback Jorge. Any reason why the difference in reported free space compared to usage?
-
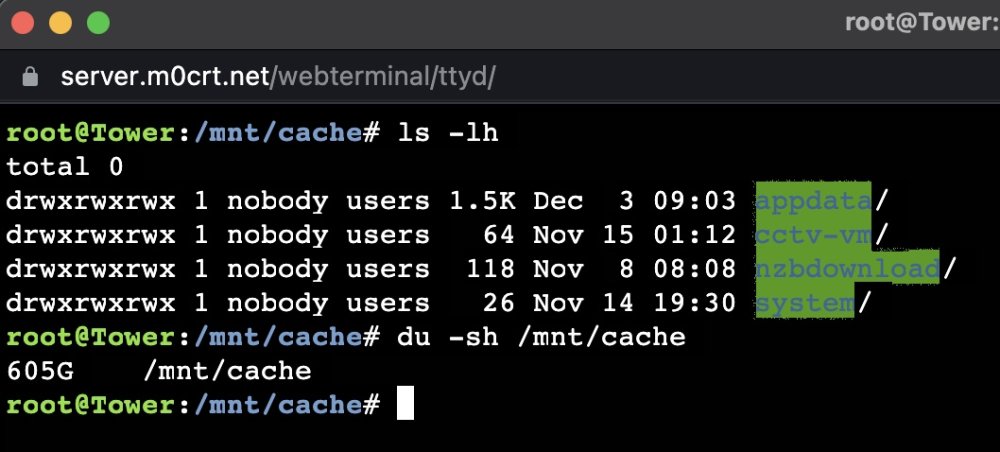
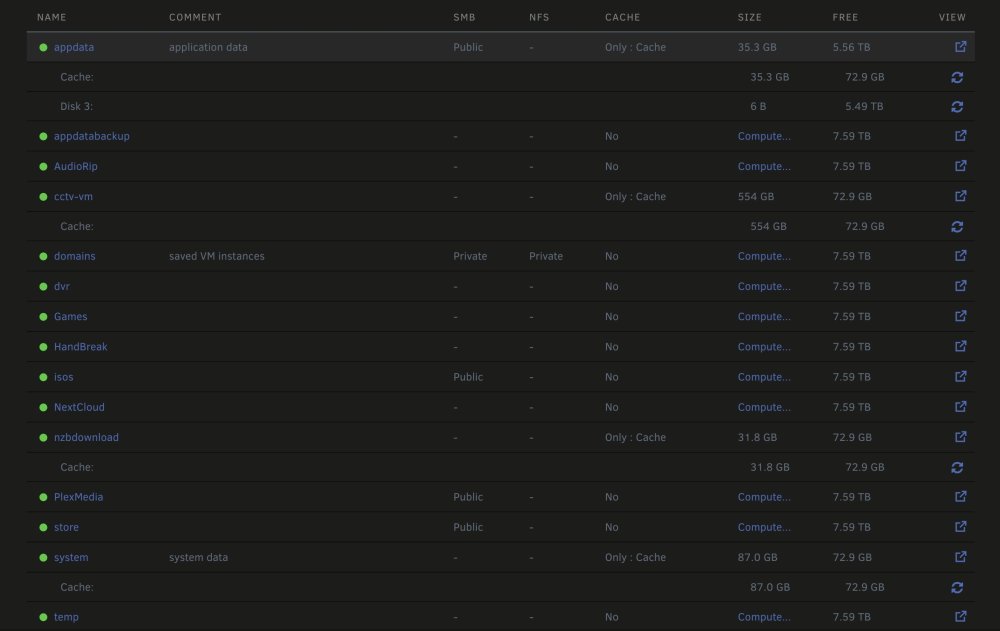
Hi All I've pondered on this for the last 24 hours and am still scratching my head. Cache pool with x2 identical SSDs. Reported available disk space of 1Tb I've several shares set to cache only: System (87.0Gb) Appdata (35.3Gb) cctv-vm (running my CCTV VM) (554Gb) nzbdownload (Deluge downloads et al) (31.8Gb) The rest of my shares do not use cache at all. When I run a calc on space used for these shares and a DU, the space used and remaining does not calculate up. For example, if I calc my cache only shares (using the Unraid GUI on the shares page), the utilise space comes to a total of 708.1Gb. However, my 'free space' on the cache shows 73.0Gb... With my rough math, I feel like I'm missing around 240Gb...Could someone explain what I may be missing here? I've run a balance and scrub on the cache pool (not expecting that this would 'fix' anything) This a block size issue? Any reason why I may be 'loosing' disk space? I've triple checked and don't have something else on the cache beyond the shares / files above. Maybe file permissions in order to 'calc' the disk space? Yours, awaiting enlightenment and putting straight! :-) Thanks

-
Thanks for the response Jorge! Didn't know I could mix the disks and copy manually...Great idea. I have actually gone something a little more crazy to get this to work. ignored ZFS and created my new XFS array...then created an unraid VM and stubbed the LSI card to the VM...created the array with the SAS disks and then mounted a remote share from the VM to the Host... lol. It's copying...albeit a little slow than natively! :-)
-
Hi Folks I've recently prep'd a new i7 12700 based device with 8X SATA ports. My original server is a HP with 'enterprise' SAS. I've moved a LSI SAS card from the HP to my new server to allow me to manually copy the files from each drive (5) (original array had x2 parity too). All going very nicely until I found I couldn't mount 4 out of the 5 SAS drives via 'unassigned devices' on the new server. I believe it's a known issue...? Well I'm feeling very distressed at the moment as I have both servers in bits and disks out! :-) It looks like there is no way of mounting the original SAS disks outside of an array without reformatting? QUESTION: This correct? Could I potentially look to 'pass-though' to an OS that could read on the new server and then copy my files off? I thought about the following solution. Can someone sanity check it? Whilst I assume I could put the disks back in the original server and mount, this isn't going to get the files on my new server without some further mess of temp keys and network transfers. Could I create a new ZFS pool as my new, permanent array on my new server and mount FOUR out of the FIVE member disks as a 'new' array to provide an opportunity to copy off the content? I would only be able to use four initially as the SAS card/cable can only support 4 at a time. I know I won't have parity protection but would this get me to my data to provide ability to copy? I could then create a new array when this copy had finished with the remaining 1 single disk. Would this work or is there 'another way'? I'm deeply concerned. Any help greatly appreciated. Thanks Mo
-
Hi Folks Can I have a sanity check on my migration please? Migrating from ML350P Gen 8 HP server to a new 12700 Intel Asrock Z690 PG Riptide solution. The original array was operating as XFS using SAS disks. My new array will be ZFS and SATA based. The cache drives and unassigned devices, graphics cards and PCIE USB3 controller will be physically moving. The original SAS disks (XFS array) won't. :-) Whilst I assume I could just network transfer the files from old to new using a 'temp' license on the new until completed, I also assume I could drop a PCIE SAS card in to the new server in order to read the individual original array member disks and transfer the files directly off one at a time onto the new ZFS mounted array on the new server? This will save time on the transfer at 1G (although I could have bought an add-on 2.5G card for the HP. To be sure...I don't need to mount the original array on the new server to affect a solid transfer? All the data is stored on the member disks and thus I just need to copy from them...no need to bring over the parity drives? Thanks! Mo
-
Hi Folks I've been passing through both an on-board (HP 350ML Gen8) USB2 controller to an Ubuntu VM for sometime with no issues; perfect. However, it seems that something has changed. The device I'm passing through, a FlightStick Pro SDR device, is low power and, along with another couple of devices, works perfectly well (using a fibre to USB convertor to cover some distance and isolate the power for radio work)...issue is one of 'timing' and potentially dropped data from the USB device. https://discussions.flightaware.com/t/re-mlat-timing-issue-error-configuration-check/80767 https://github.com/wiedehopf/adsb-wiki/wiki/mlat-in-VMs There are some 'Proxmox' settings...anything to suggest for QEMU? I've moved the hardware over to a Raspberry Pi4 and no issues what so ever. Testing the VM with passthrough of a USB3 Renisas card, also highlights 'clock timing issues'. Is there any best practice of how to check / tune USB pass-through performance? As mentioned, the devices pass-though fine, performance and 'timing' seems to be an issue. Will the controller type on the VM make any difference to the configuration of the pass-through? Are there any settings / manual changes I should look to make? Thanks Mo
-
Hi All Strange issue with passthrough of my 1660S. Due to USB breakout requirements, I've forced MMU groups to split out. pcie_acs_override=downstream,multifunction vfio_iommu_type1.allow_unsafe_interrupts=1 I now have the GPU, Audio and 'USB Controller' all in their own MMU group with no sharing. IOMMU group 32:[10de:21c4] 0a:00.0 VGA compatible controller: NVIDIA Corporation TU116 [GeForce GTX 1660 SUPER] (rev a1) IOMMU group 33:[10de:1aeb] 0a:00.1 Audio device: NVIDIA Corporation TU116 High Definition Audio Controller (rev a1) IOMMU group 34:[10de:1aec] 0a:00.2 USB controller: NVIDIA Corporation TU116 USB 3.1 Host Controller (rev a1) On the Windows 10 VM Config, I assign the GPU and sound card as expected but receive the following error: internal error: qemu unexpectedly closed the monitor: 2021-04-18T08:32:22.076398Z qemu-system-x86_64: -device vfio-pci,host=0000:0a:00.1,id=hostdev1,bus=pci.9,addr=0x0: vfio 0000:0a:00.1: failed to setup container for group 33: Failed to set iommu for container: Operation not permitted Seeing that the audio controller is in a separate, isolated MMU group, I'm struggling to understand why I'm facing this issue. Any ideas? HP MP350P Gen 8 with latest bios. Thanks Mo tower-diagnostics-20210418-0934.zip
-
Hi Folks For those having issue with the Big Sur install and 'Method 2'. Try and edit line 273. to include an 'rm' before the dmg line. This will remove the permission denied and hopefully continue with the script. Worked for me. Remember, if you reconfigure the container, you will remove the edit as it's within the container and not part of the appdata. Line 273. of the unraid.sh within /macinabox folder of the container.
-
This works a treat. Ensure you disable Fast Boot in Windows 10 power settings for the ACPI tables to recache. Perfect. 🙂
-
Nice one Jummama. I'll take a look. I did attempt to patch utilising the aforementioned sed method but on checking my ACPI tables it still wasn't working. Do I need to refresh the tables somehow on an existing VM? Any reason why I cannot patch within an Unraid Terminal session? Thanks
-
Hi Folks As documented elsewhere, it seems that certain game developers are now taking on themselves to block running of their content on virtual platforms. With the potential, documented in the linked Reddit post below, how easy would it be to either provide an option for a 'hardened' QEMU version OR facilitate building a custom version (as documented in the post)? Whilst I have dev tools installed, cannot complete the build due to missing deps...namely pixman in my case. Keen to get RDR2 up and running once more. Thoughts would be most welcome.




