




Caduceus
Members
-
Joined
-
Last visited
-
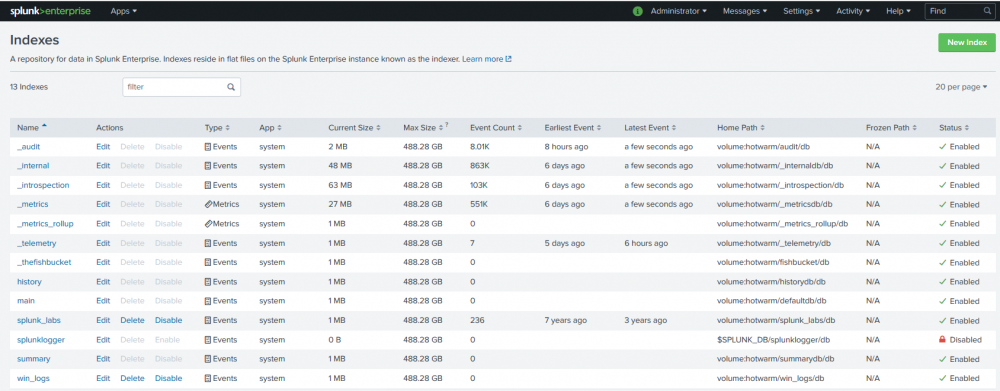
I tried to follow these instructions to the letter... unfortunately, every time I restart the container or just restart splunkd, all of my indexed data seems to no longer be searchable on restart. The index data can still be seen in the persistant shares (ie. /splunkdata and /splunkcold). If I stop splunk and delete everything in /splunkdata and /splunkcold, then splunk start. Everything will re-index again. If I don't delete the data, I cannot search the data whether I restart or not. So some record of the files being indexed remains persistant in fishbucket db. I have not idea why my other data seems to disappear on restart. I was doing some Splunk Labs for an Sales Engineer 2 accreditation and I spent half my time wondering why my files weren't being indexed... turned out that they had been indexed but on restart they disappeared and because there was data still in fishbucket they wouldn't be re-parsed with any changes I made and re-indexed. Here are my docker volume mappings: /splunkcold <> /mnt/user/splunk-warm-cold/ #this is a unraid cached array share for cold buckets /opt/splunk/etc/licenses <> /mnt/user/appdata/splunkenterprise/license #I persist a developer license here /test <> /mnt/user/appdata/splunkenterprise/test/ #ingesting test files from here /opt/splunk/etc/system/local <> /mnt/user/appdata/splunkenterprise/etc/system/local #indexes.conf lives here /splunkdata <> /mnt/user/appdata/splunkenterprise/splunkdata #hot-warm data is persisted here on ssd cache /opt/splunk/etc/apps <> /mnt/user/appdata/splunkenterprise/etc/apps /opt/splunk/etc/auth <> /mnt/user/appdata/splunkenterprise/etc/auth Here is my indexes.conf stored in /opt/splunk/etc/system/local which is persisted to a share (/mnt/user/appdata/splunkenterprise/etc/system/local): [volume:hotwarm] path = /splunkdata maxVolumeDataSizeMB = 3072 [volume:cold] path = /splunkcold maxVolumeDataSizeMB = 51200 [default] # 90 days in seconds frozenTimePeriodInSecs = 7884000 homePath = volume:hotwarm/$_index_name/db coldPath = volume:cold/cold/$_index_name/colddb thawedPath = /splunkcold/$_index_name/thaweddb tstatsHomePath = volume:hotwarm/$_index_name/datamodel_summary # Splunk Internal Indexes [_internal] frozenTimePeriodInSecs = 7884000 homePath = volume:hotwarm/_internaldb/db coldPath = volume:cold/cold/_internaldb/colddb thawedPath = /splunkcold/_internaldb/thaweddb tstatsHomePath = volume:hotwarm/_internaldb/datamodel [_audit] frozenTimePeriodInSecs = 7884000 homePath = volume:hotwarm/audit/db coldPath = volume:cold/cold/audit/colddb thawedPath = /splunkcold/audit/thaweddb tstatsHomePath = volume:hotwarm/audit/datamodel [_introspection] frozenTimePeriodInSecs = 7884000 homePath = volume:hotwarm/_introspection/db coldPath = volume:cold/cold/_introspection/colddb thawedPath = /splunkcold/_introspection/thaweddb tstatsHomePath = volume:hotwarm/_introspection/datamodel [_metrics] frozenTimePeriodInSecs = 7884000 homePath = volume:hotwarm/_metricsdb/db coldPath = volume:cold/cold/_metricsdb/colddb thawedPath = /splunkcold/_metricsdb/thaweddb tstatsHomePath = volume:hotwarm/_metricsdb/datamodel [_metrics_rollup] frozenTimePeriodInSecs = 7884000 homePath = volume:hotwarm/_metrics_rollup/db coldPath = volume:cold/cold/_metrics_rollup/colddb thawedPath = /splunkcold/_metrics_rollup/thaweddb tstatsHomePath = volume:hotwarm/_metrics_rollup/datamodel [_telemetry] frozenTimePeriodInSecs = 7884000 homePath = volume:hotwarm/_telemetry/db coldPath = volume:cold/cold/_telemetry/colddb thawedPath = /splunkcold/_telemetry/thaweddb tstatsHomePath = volume:hotwarm/_telemetry/datamodel [_thefishbucket] frozenTimePeriodInSecs = 7884000 homePath = volume:hotwarm/fishbucket/db coldPath = volume:cold/cold/fishbucket/colddb thawedPath = /splunkcold/fishbucket/thaweddb tstatsHomePath = volume:hotwarm/fishbucket/datamodel [history] frozenTimePeriodInSecs = 7884000 homePath = volume:hotwarm/historydb/db coldPath = volume:cold/cold/historydb/colddb thawedPath = /splunkcold/historydb/thaweddb tstatsHomePath = volume:hotwarm/historydb/datamodel [summary] frozenTimePeriodInSecs = 7884000 homePath = volume:hotwarm/summarydb/db coldPath = volume:cold/cold/summarydb/colddb thawedPath = /splunkcold/summarydb/thaweddb tstatsHomePath = volume:hotwarm/summarydb/datamodel [main] frozenTimePeriodInSecs = 7884000 homePath = volume:hotwarm/defaultdb/db coldPath = volume:cold/cold/defaultdb/colddb thawedPath = /splunkcold/defaultdb/thaweddb tstatsHomePath = volume:hotwarm/defaultdb/datamodel # Begin Custom Indexes [splunk_labs] homePath = volume:hotwarm/splunk_labs/db coldPath = volume:cold/cold/splunk_labs/colddb thawedPath = /splunkcold/splunk_labs/thaweddb tstatsHomePath = volume:hotwarm/splunk_labs/datamodel [win_logs] homePath = volume:hotwarm/win_logs/db coldPath = volume:cold/cold/win_logs/colddb thawedPath = /splunkcold/win_logs/thaweddb tstatsHomePath = volume:hotwarm/win_logs/datamodel Monitoring Console / Data / Indexes Before a Restart Any ideas how I can fix this? I love the idea of having a container but I can't live with it as is Thanks! I also attached the container logs to see if that gives any insight. ****UPDATE**** I think I discovered the answer in the logs: 11-17-2020 09:07:31.535 +0000 INFO BucketMover - will attempt to freeze: candidate='/splunkdata/splunk_labs/db/db_1505895227_1388693545_13' because frozenTimePeriodInSecs=7884000 is exceeded by the difference between now=1605604051 and latest=1505895227 11-17-2020 09:07:31.535 +0000 INFO IndexerService - adjusting tb licenses 11-17-2020 09:07:31.545 +0000 INFO BucketMover - AsyncFreezer freeze succeeded for bkt='/splunkdata/splunk_labs/db/db_1505895227_1388693545_13' splunk_docker_logs.txt It turns out that the Splunk Lab files they give you have dates back from 2014... so the event dates in my case and in most peoples cases exceed by far the amount of time it takes to send a bucket of events to a frozen bucket. So on restart it sends all of my just indexed data, directly to frozen because of the latest event date in that newly indexed bucket and therefore I can't see the data anymore. Seem that the data was persisting just fine and this is expected behavior. For the lab data I will change the frozenTimePeriodInSecs > greater than the event dates. I hope this helps others, even if just looking at screenshots and config files if they are looking to do the same thing.
-
I was mistaken. This change doesn't seem to fix it. But in $splunk_home/etc/apps/journald_input/local/app.conf if we add: [install] state = disabled That seems to fix it by disabling the app.
-
This message is persistent in my Messages. Is this error expected?

