
Keevil
-
Posts
85 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by Keevil
-
-
Thanks, @johnnie.black time to cancel my order with Amazon for the replacement Seagates and get something else!
Is it even worth continuing with the pre-clear? I guess not
-
Help needed...I bought 2 Seagate BarraCuda 2 TB from Amazon. I pre-cleared the first HDD and I ran into issues with Current & Pending Sectors:
197 Current_Pending_Sector 0x0012 001 001 000 Old_age Always - 65272 198 Offline_Uncorrectable 0x0010 001 001 000 Old_age Offline - 65272
Post can be found here . I was advised to get a replacement from Amazon, so that request has been sent off and the new one is on its way back.
I have just started pre-clearing the second disk and I now have another problem with the second Seagate.
I logged on and was bombarded with a number of notifications around Pending Sectors, i then waited for another 15-20 mins to see what happens. Its currently 92% the way through stage 2 of the preclear. My SMART report looks like this (notice the high reallocation sector count):
SMART Attributes Data Structure revision number: 10 Vendor Specific SMART Attributes with Thresholds: ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 1 Raw_Read_Error_Rate 0x000f 119 090 006 Pre-fail Always - 234082416 3 Spin_Up_Time 0x0003 100 100 000 Pre-fail Always - 0 4 Start_Stop_Count 0x0032 100 100 020 Old_age Always - 1 5 Reallocated_Sector_Ct 0x0033 097 097 010 Pre-fail Always - 4208 7 Seek_Error_Rate 0x000f 100 253 030 Pre-fail Always - 14681 9 Power_On_Hours 0x0032 100 100 000 Old_age Always - 7 10 Spin_Retry_Count 0x0013 100 100 097 Pre-fail Always - 0 12 Power_Cycle_Count 0x0032 100 100 020 Old_age Always - 1 183 Runtime_Bad_Block 0x0032 100 100 000 Old_age Always - 0 184 End-to-End_Error 0x0032 100 100 099 Old_age Always - 0 187 Reported_Uncorrect 0x0032 001 001 000 Old_age Always - 220 188 Command_Timeout 0x0032 100 100 000 Old_age Always - 0 189 High_Fly_Writes 0x003a 100 100 000 Old_age Always - 0 190 Airflow_Temperature_Cel 0x0022 069 067 045 Old_age Always - 31 (Min/Max 24/33) 191 G-Sense_Error_Rate 0x0032 100 100 000 Old_age Always - 0 192 Power-Off_Retract_Count 0x0032 100 100 000 Old_age Always - 0 193 Load_Cycle_Count 0x0032 100 100 000 Old_age Always - 2 194 Temperature_Celsius 0x0022 031 040 000 Old_age Always - 31 (0 24 0 0 0) 197 Current_Pending_Sector 0x0012 100 091 000 Old_age Always - 0 198 Offline_Uncorrectable 0x0010 100 091 000 Old_age Offline - 0 199 UDMA_CRC_Error_Count 0x003e 200 200 000 Old_age Always - 0 240 Head_Flying_Hours 0x0000 100 253 000 Old_age Offline - 7 (101 102 0) 241 Total_LBAs_Written 0x0000 100 253 000 Old_age Offline - 3716532224 242 Total_LBAs_Read 0x0000 100 253 000 Old_age Offline - 3907087279
I take it this disk is a dud as well?! Time to buy a different HDD as this is obviously affecting the whole batch?
-
Perfect that is exactly what I thought! Thanks for confirming this.
-
Hello,
I purchased 2 new drives from Amazon last week. I started the pre-clearing process which finished successfully after 2 days.
The problem I am now facing seems to be an issue with the SMART report.
When I try to run a report it say
QuoteErrors occurred - Check SMART report
If I look at the history I see this:
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error # 1 Short offline Completed: read failure 90% 62 3385911640 # 2 Extended offline Completed: read failure 90% 62 3385911640 # 3 Short offline Completed: read failure 90% 62 3385904704 # 4 Extended offline Completed: read failure 90% 62 3385911640 # 5 Extended offline Completed: read failure 90% 62 3385904704 # 6 Short offline Completed: read failure 10% 18 2503511816
I then looked at the SMART error log and it has the following:
ATA Error Count: 15319 (device log contains only the most recent five errors) CR = Command Register [HEX] FR = Features Register [HEX] SC = Sector Count Register [HEX] SN = Sector Number Register [HEX] CL = Cylinder Low Register [HEX] CH = Cylinder High Register [HEX] DH = Device/Head Register [HEX] DC = Device Command Register [HEX] ER = Error register [HEX] ST = Status register [HEX] Powered_Up_Time is measured from power on, and printed as DDd+hh:mm:SS.sss where DD=days, hh=hours, mm=minutes, SS=sec, and sss=millisec. It "wraps" after 49.710 days. Error 15319 occurred at disk power-on lifetime: 51 hours (2 days + 3 hours) When the command that caused the error occurred, the device was active or idle. After command completion occurred, registers were: ER ST SC SN CL CH DH -- -- -- -- -- -- -- 40 53 00 ff ff ff 0f Error: UNC at LBA = 0x0fffffff = 268435455 Commands leading to the command that caused the error were: CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name -- -- -- -- -- -- -- -- ---------------- -------------------- 25 00 00 ff ff ff ef 00 2d+03:11:04.789 READ DMA EXT 25 00 00 ff ff ff ef 00 2d+03:11:04.767 READ DMA EXT 25 00 00 ff ff ff ef 00 2d+03:11:02.523 READ DMA EXT 25 00 00 ff ff ff ef 00 2d+03:11:02.425 READ DMA EXT 25 00 00 ff ff ff ef 00 2d+03:10:59.427 READ DMA EXT Error 15318 occurred at disk power-on lifetime: 51 hours (2 days + 3 hours) When the command that caused the error occurred, the device was active or idle. After command completion occurred, registers were: ER ST SC SN CL CH DH -- -- -- -- -- -- -- 40 53 00 ff ff ff 0f Error: UNC at LBA = 0x0fffffff = 268435455 Commands leading to the command that caused the error were: CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name -- -- -- -- -- -- -- -- ---------------- -------------------- 25 00 00 ff ff ff ef 00 2d+03:10:29.708 READ DMA EXT 25 00 00 ff ff ff ef 00 2d+03:10:29.690 READ DMA EXT 25 00 01 ff ff ff ef 00 2d+03:10:29.679 READ DMA EXT 25 00 01 ff ff ff ef 00 2d+03:10:29.678 READ DMA EXT 25 00 00 ff ff ff ef 00 2d+03:10:29.667 READ DMA EXT Error 15317 occurred at disk power-on lifetime: 51 hours (2 days + 3 hours) When the command that caused the error occurred, the device was active or idle. After command completion occurred, registers were: ER ST SC SN CL CH DH -- -- -- -- -- -- -- 40 53 00 ff ff ff 0f Error: UNC at LBA = 0x0fffffff = 268435455 Commands leading to the command that caused the error were: CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name -- -- -- -- -- -- -- -- ---------------- -------------------- 25 00 00 ff ff ff ef 00 2d+03:07:56.308 READ DMA EXT 25 00 00 ff ff ff ef 00 2d+03:07:56.253 READ DMA EXT 25 00 01 ff ff ff ef 00 2d+03:07:56.240 READ DMA EXT 25 00 01 ff ff ff ef 00 2d+03:07:56.240 READ DMA EXT c8 00 01 2f d2 da e9 00 2d+03:07:56.230 READ DMA Error 15316 occurred at disk power-on lifetime: 51 hours (2 days + 3 hours) When the command that caused the error occurred, the device was active or idle. After command completion occurred, registers were: ER ST SC SN CL CH DH -- -- -- -- -- -- -- 40 53 00 ff ff ff 0f Error: UNC at LBA = 0x0fffffff = 268435455 Commands leading to the command that caused the error were: CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name -- -- -- -- -- -- -- -- ---------------- -------------------- 25 00 00 ff ff ff ef 00 2d+03:07:43.707 READ DMA EXT 25 00 00 ff ff ff ef 00 2d+03:07:43.638 READ DMA EXT 25 00 00 ff ff ff ef 00 2d+03:07:40.843 READ DMA EXT 25 00 00 ff ff ff ef 00 2d+03:07:40.769 READ DMA EXT 25 00 01 ff ff ff ef 00 2d+03:07:40.753 READ DMA EXT Error 15315 occurred at disk power-on lifetime: 51 hours (2 days + 3 hours) When the command that caused the error occurred, the device was active or idle. After command completion occurred, registers were: ER ST SC SN CL CH DH -- -- -- -- -- -- -- 40 53 00 ff ff ff 0f Error: UNC at LBA = 0x0fffffff = 268435455 Commands leading to the command that caused the error were: CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name -- -- -- -- -- -- -- -- ---------------- -------------------- 25 00 00 ff ff ff ef 00 2d+03:07:17.806 READ DMA EXT 25 00 00 ff ff ff ef 00 2d+03:07:17.747 READ DMA EXT 25 00 01 ff ff ff ef 00 2d+03:07:17.730 READ DMA EXT 25 00 01 ff ff ff ef 00 2d+03:07:17.729 READ DMA EXT c8 00 01 c5 1f 31 e3 00 2d+03:07:17.716 READ DMA
I have also downloaded and attached the full SMART report.
The big question, should this drive go into my unRAID array or be sent back to Amazon? I am thinking the latter currently!
-
On 20/07/2017 at 9:19 AM, johnnie.black said:
I'd recommend the following:
Run an extended SMART test on the cache disk, if it fails replace it, if it passes replace cables and since you have some free connect it to an onboard SATA port, check filesystem on that disk, delete and recreate docker image and see if the issues go away.
1Thanks I will give this a go and see if that helps!
-
unRAID Version: 6.3.5
I have run the amazing "Fix Common Problems" plugin as I have had 2 occasions today where my cache drive (250GB) has suddenly turned into Read Only Mode. I also noticed earlier that there were some errors in the Main GUI page.
When running the Fix Common Poblems page the following Errors were found:
-
Call Traces found on your server
- Your server has issued one or more call traces. This could be caused by a Kernel Issue, Bad Memory, etc. You should post your diagnostics and ask for assistance on the unRaid forums
So here I am! Any help would be great!
Thanks
-
Call Traces found on your server
-
Ahh thanks for the advice regarding the revised card, that is instant help!
Regarding plans for the server, the primary use case is for Plex, this is going to be given to a significant number of users, so after doing research this was the reason for dual CPU's. However, I also want to run a number of VMs to run as build servers, and also as a general backup server.
I have already run out of SATA ports for the 10 drives I already have, so if I am going to change the motherboard, I may as well go big....get it all done in one go!
-
I am looking to upgrade my unRAID server from:
- Asus P8H61-M LE
- Intel Core i3 2100 3.10GHz
- 2x 5 Bay IcyDock (this will be going to 4x IcyDock's soon!)
- Lian Li A77FB
- Supermicro AOC-SASLP-MV8
- Coolermaster GX 750W PSU
To a much more powerful CPU and Motherboard, plus more RAM:
- Asrock EP2C602–4L/D16
- 2 x Intel Xeon E5–2670 SR0KX
I am going to follow the blog post here...
If anyone has any pointers around pros or cons, or if there is other great material that could be shared, that would be great!
-
Few...thank god for that...its been a long time since i set this up. Thanks for your help!
-
Hello,
Is it normal not have a shares menu?
I have just upgraded from 5.0.beta14 to 6.0-beta10a, and as the parity check runs there is no shares tab. I find this a little strange...is this normal.
Screenshot attached

-
Correct they have just released a Linux client however im not willing to pay $999/year for the privilege, especially as i an early adopter and i paid $49 for a whole your with unlimited storage.
-
I think we will have to wait for Bitcasa to release its HEADLESS linux version then we can look at trying and install it. Until then we will be unable to do anything!
-
Ok yes, i have added a cache drive. And there is one one share that is active on the cache drive, it doesnt sync across to the array, however it is a share. So this will explain it.
Thanks
-
Hello,
I am suddenly seeing two user directories. User and User0. Is there a reason i am seeing two??
Screenshot attached.
Many Thanks
Michael Down
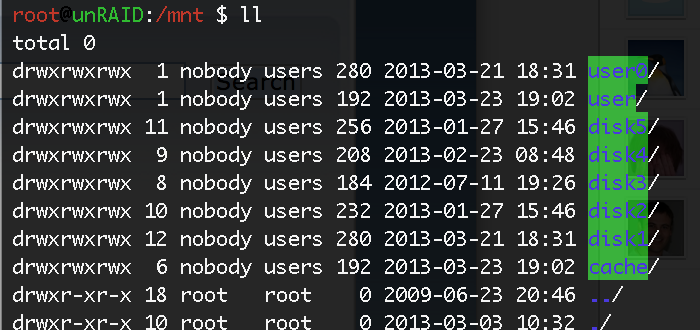
-
Hello,
Has anyone looked at integrating Bitcasa with unRAID? I have just purchased there plan and i was wondering if anyone else has purchased Bitcasa and have been able to integrarte it with unRAID.
Many Thanks
-
When doing that, will it change the version number in the top right hand corner. Or is there something else that i will also have to do?
-
Are these the steps:
[*]Prepare the flash: either shutdown your server and plug the flash into your PC or Stop the array and perform the following actions referencing the flash share on your network:
[*]Copy the files bzimage and bzroot from the zip file to the root of your flash device, overwriting the same-named files already there.
Reboot your server. Once boot-up has completed, you should see "Stopped. Configuration valid." array status with all disks assigned correctly.
[*]Click on each disk link on the Main page and examine the Partition format field. If you see "MBR: error", or "MBR: unknown" for any disk, do not Start the array; instead post your finding in the Forum announcement thread for this release. If everything looks ok, click Start to bring the array on-line.
[*]Go to Utils/New Permissions and execute that utility to change file ownership and permission settings. This is necessary for proper operation of the 5.0 security model.
-
Thanks, i have dont that, create a share called apps, then changed it too cache only. PERFECT! Lets see if this works....
Hmmm...interesting. Is it an easy upgrade? Is there some sort of installation guide i could follow?
-
Im using 5.0-beta14 does it work on this version?
Also i have attached a screenshot of the location of my .apps folder and how it gets copied across into my array.
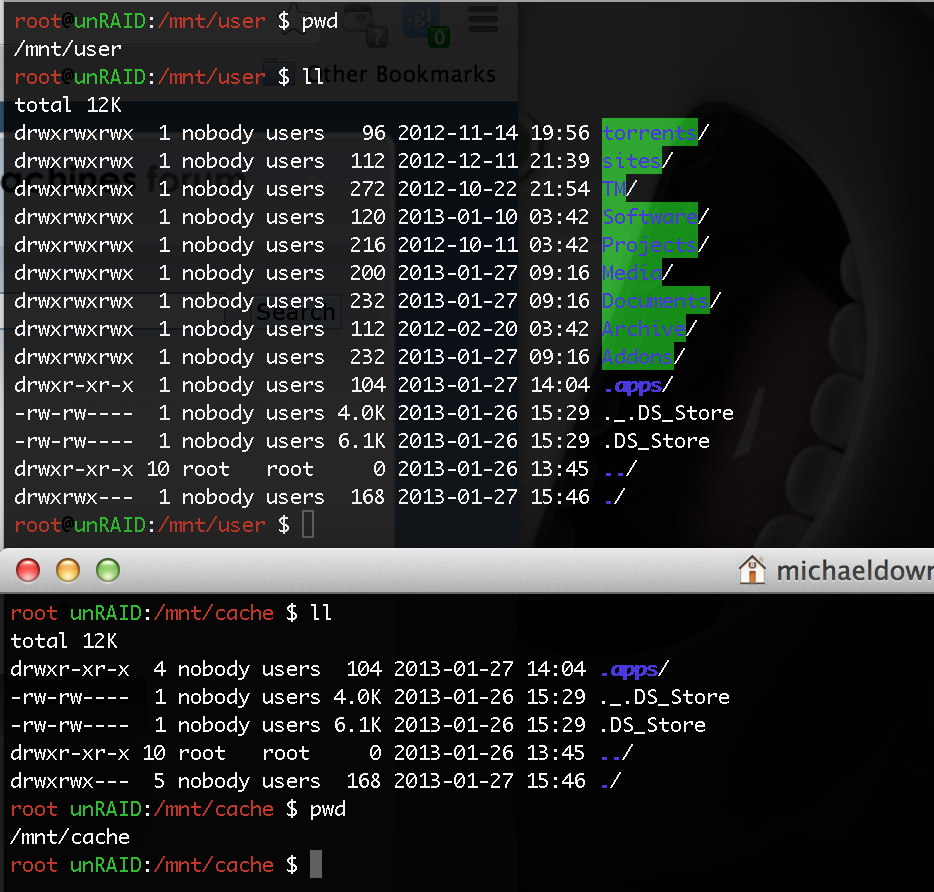
-
No, i created the .apps folder on the command line, and not through the gui. However it is still replicating onto the array; even with a dot prefix.
-
Hello,
I have just installed a cache drive and all files are being moved. I have a folder called .apps which contains folders for sickbeard and sab. However it is being moved, it is located here:
/mnt/cache/.apps
On the unraid website it says the following:
The mover will not move any top-level directories which begin with a '.' character. Such directories will not exist in normal use, but an advanced user may use this knowledge to create directories which won't get moved.
http://lime-technology.com/wiki/index.php/Cache_disk#The_Mover
How can i stop the .apps folder from being moved?
-
Hello,
Im hoping someone will be able to help, i rebooted my unRIAD server and i noticed that Disk 2 now has a red flashing circle next to it. How do i proceed to rebuild the drive?
Many Thanks
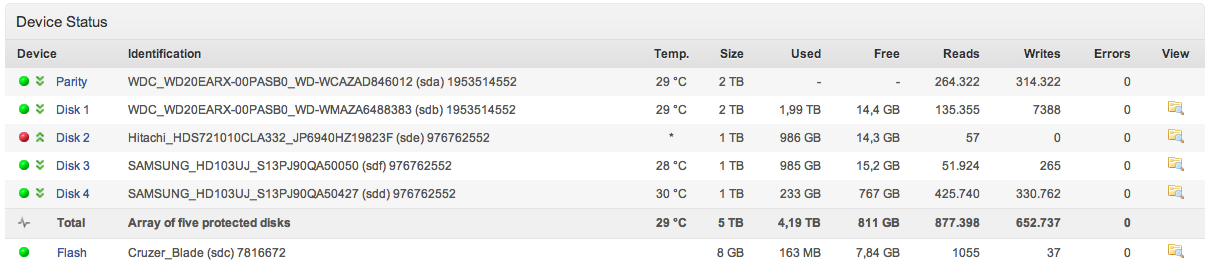
-
Hello,
If sickbeard is unable to shutdown when using the GUI is there a method of shutting it down?
Would killing the process work?
-
Did you ever get this fix? Or figure out a method?




[SOLVED] Seagate Drive Pre-clear issues
in General Support
Posted
It's off again! Just as I go to cancel more notifications start firing:
Thanks for all your help.