Magmanthe
Members
-
Joined
-
Last visited
Everything posted by Magmanthe
-
Not sure exactly what was the "correct solution". But after checking the link and disabling C-states as well as a little bit of Curve-adjusting of the CPU, it is now working as intended (from my understanding). No more reboots during Parity-sync/Rebuild and the server is now up and running and working again. Thanks @JorgeB //Magmanthe
-
hey boys and girls.. I'm in need of some assistance (diags attached) (please disregard the date - this happened right before x-mas, but I did not have more time to troubleshoot or ask your help, so I turned off the server and it's been off since) I bought 2 x 18TB disks (external then shucked) to swap with current parity drives (that were only 10's). Swapped out Parity 0 - did a re-sync and that just did it's thing, no problem Then when this was done, I was doing the same with Parity 1. Swapped out, and started the re-sync. But after some hours (a little difficult to say, cause I'm was not glued to the screen) but maybe around 3-6ish hours, the server just does a reboot. This screws up the rebuild/re-sync I tried starting it again, same thing happens. Tried a third time (this time with the window open (In the Nordics - hoping maybe a significant temperature-decrease would help). it did not (and it was like 10-12C degrees in the room, so no overheating issue). Any idea? Is the drive fucked? What troubleshooting I've tried: I have swapped / changed the SATA-cable from the disk to the MB I have moved the SATA-port used on the MB to different one (taking care not to use SATA that "could" be disabled due to M.2 drive (it is not, but making double-sure). I have changed / added another power-cable from the modular PSU - dividing the disk's on 2 wires instead of everything on 1 (possible power-overload, again just to make sure). Appreciate any help. // Magmanthe magnas-diagnostics-20251221-1722.zip
-
So I've done some more testing. Picking up my old Laptop (dusting away in the cabinet), I started it, connected to my Home Wifi and with it I am able to access //magnas and see all the shares just fine. Even opening a random picture or other media, it does start playing. So maybe it's not on Unraid the problem lies, but on my main computer, somehow? Where should I start looking into this? //Magmanthe
-
I have not.. Results after "Docker safe new perms"-run Still no access to shares.
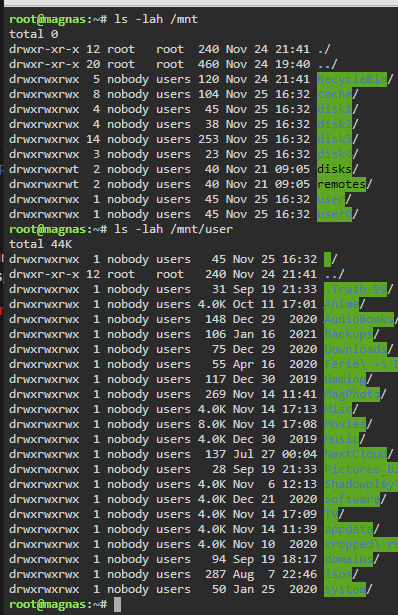
-
Ohh, sorry. didn't think the name mattered....
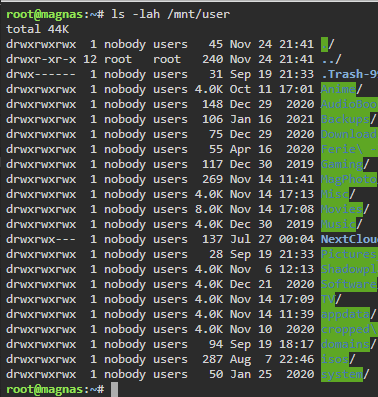
-
Hi, Doesn't seem like it..
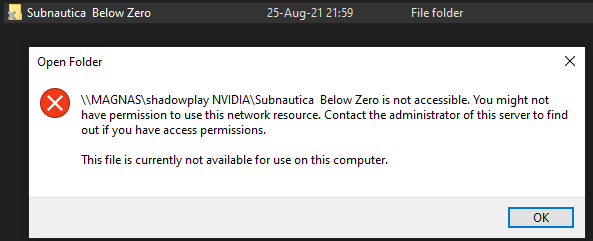 Hey all.. I need some help TLDR: I stopped being able to access shares over Network with WindowsExplorer - or playing media. (windows 10) - This all worked fine 3 days ago, before I had to shut down the server and PC. First I thought it was a Windows-issue, but after some trial and error, it seems like my user-account (on unraid) became borked somehow? (Tried to verify by creating a new user-account and giving same permissions as main (user = test). I logged into both WindowsVM and linuxVM and then tried to log into \tower from there Logging in with test works fine, everything is as it should. Reseting connection and logging in with my normal account does not work. Any way to troubleshoot this? (other than just lookin in the user-settings page? cause that looks fine), or is the easiest solution just to delete the account, and either remake it identical, or just a new-one? This is what I see when going to /Tower //Magmanthe magnas-diagnostics-20211124-1515.zip
Hey all.. I need some help TLDR: I stopped being able to access shares over Network with WindowsExplorer - or playing media. (windows 10) - This all worked fine 3 days ago, before I had to shut down the server and PC. First I thought it was a Windows-issue, but after some trial and error, it seems like my user-account (on unraid) became borked somehow? (Tried to verify by creating a new user-account and giving same permissions as main (user = test). I logged into both WindowsVM and linuxVM and then tried to log into \tower from there Logging in with test works fine, everything is as it should. Reseting connection and logging in with my normal account does not work. Any way to troubleshoot this? (other than just lookin in the user-settings page? cause that looks fine), or is the easiest solution just to delete the account, and either remake it identical, or just a new-one? This is what I see when going to /Tower //Magmanthe magnas-diagnostics-20211124-1515.zip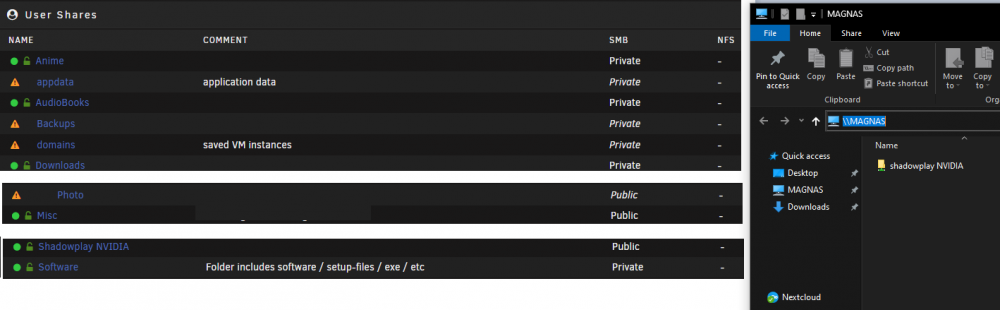 Ahh, yeah now I see what you mean.. I think I read that section kind of fast and wronlgy. Thought it was BOTH goth disabled when using the M2_2-slot... Not (like you say) that it is either SATA1 port is disabled IF SATA M.2 or PCI6 is disabled IF nvme M2.. Got it.. Thanks for pointing that out.. Anywho the whole thing is still kind of mysterious.. Like WHY would UNRAID eject the drive if it's in the M2_1-slot, while performs totally normal if the drive is in the M2_2-slot... Very strange indeed. But it is working now, and as long as I just note it down in my Notes I will remember this the next time I poke around in there Thanks again.. //MagmantheWell, not according to MSI-manual.. Source: https://download.msi.com/archive/mnu_exe/mb/E7B79v3.0.pdf Page 32/110 on the M2-page it says: SATA1 port will be unavailable when installing SATA M.2 SSD in M2_2 slot. PCI_E6 slot will be unavailable when installing PCIe M.2 SSD in M2_2 slot. M2_1 slot only supports PCIe mode. //Magmanthe
Ahh, yeah now I see what you mean.. I think I read that section kind of fast and wronlgy. Thought it was BOTH goth disabled when using the M2_2-slot... Not (like you say) that it is either SATA1 port is disabled IF SATA M.2 or PCI6 is disabled IF nvme M2.. Got it.. Thanks for pointing that out.. Anywho the whole thing is still kind of mysterious.. Like WHY would UNRAID eject the drive if it's in the M2_1-slot, while performs totally normal if the drive is in the M2_2-slot... Very strange indeed. But it is working now, and as long as I just note it down in my Notes I will remember this the next time I poke around in there Thanks again.. //MagmantheWell, not according to MSI-manual.. Source: https://download.msi.com/archive/mnu_exe/mb/E7B79v3.0.pdf Page 32/110 on the M2-page it says: SATA1 port will be unavailable when installing SATA M.2 SSD in M2_2 slot. PCI_E6 slot will be unavailable when installing PCIe M.2 SSD in M2_2 slot. M2_1 slot only supports PCIe mode. //Magmanthe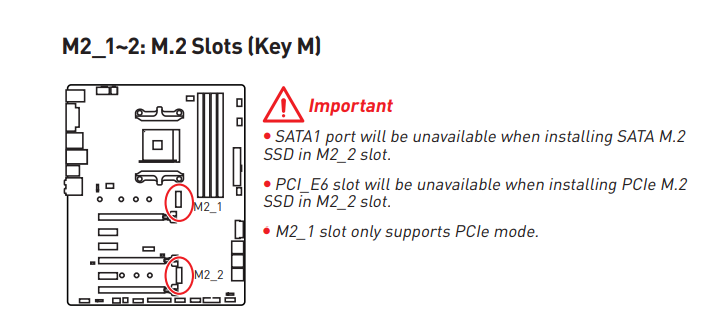 So just a quick update. Plan was to get a new nvme (probably a samsung-one). So to prepare for this, I removed the small EVO250GB from M2_1-slot. And then I installed the "old" Corsair Force MP510 in the M2_2-slot (so that the "main-slot" would be free and clear for when the new NVME-arrived in the mail). Put the server back in it's room and started it up. Yes, the first boot, it didn't understand much of what was happening (due to the removing of, and adding of a new drive) but after stopping the array, assigning the Corsair as the Cache and then starting the array, I did a full server reboot. Once the server came back up (I fully expecting it to eject the drive as previously stated in the diags earlier in the thread) and prepared to stop the array, remove/add the drive and start it again. But to my surprise, now it just worked, totally fine and normal. No ejection of the drive, no I/O error, no nothing.. I was very surprised. So I tried some more reboots and it still holds strong. Very strange indeed. So for now, I guess I don't have to get a new NVME.. (Just need to remember that the SATA1-port and PCIe6-slot is now disabled because I'm using the M2_2-slot..) Again thanks for the help, @JorgeB... Much appreciated //MagmantheHappy Weekend Tried with a new (well used) nvme. Turned off server - Removed the 1TB corsairs Force MP510 (that did work on the "old" hw). Installed a 250GB Samsung 960 EVO, and turned on the server. After boot I took out a diagnostics-zip. The Samsung EVO was discovered as unassigned. I stopped the array put the EVO as Cache-drive and started the Array. Had to format the drive (as it was not XFS) and then it just kind of worked. I then installed 3 random apps/dockers (cause that data lives on the cachedrive) and then restarter the server. Now UNRAID boots totally normally and detects and treats the 250EVO as a normal cache-drive. No ejection or anything. After boot I took out another Diagnostics (for comparison reasons, but that might not be needed). Just based on my experiences here, it does seem that some kind of mix between I guess the MB, Unraid and that specific Corsair-series of NVME's just doesn't play nice with eachother? or? //magmanthe magnas-diagnostics-after_NVME_setCache.zip magnas-diagnostics-firstBoot after nvme-swap.zipHi, Done. Attached is diags from a reboot nothing else. //magmanthe magnas-diagnostics-20210609-1931.zipHi, Thanks for the quick reply, however I have to report NoJoy on this. Added line to the Syslinux Config and rebootet, and the same happens when it boots back up. New picture taken from attached monitor. Regarding BIOS: I upgraded the BIOS to latest from MSI (release 31|st of May I believe) before booting to unraid for the first time, so that is already covered. However something peculiar. If I stop the array, unmark/remove the cache from the pool-dropdown list re-add the nvme to the cache-pool start array. It does seem to work normally again. All dockers (that write to the cahce) function (opening KRUSADER i can browser the cache-drive). So I mean yeah, it works, if I take the time to stop/remove/add/start the array I guess... 🤔 Any clues? //Magmanthe
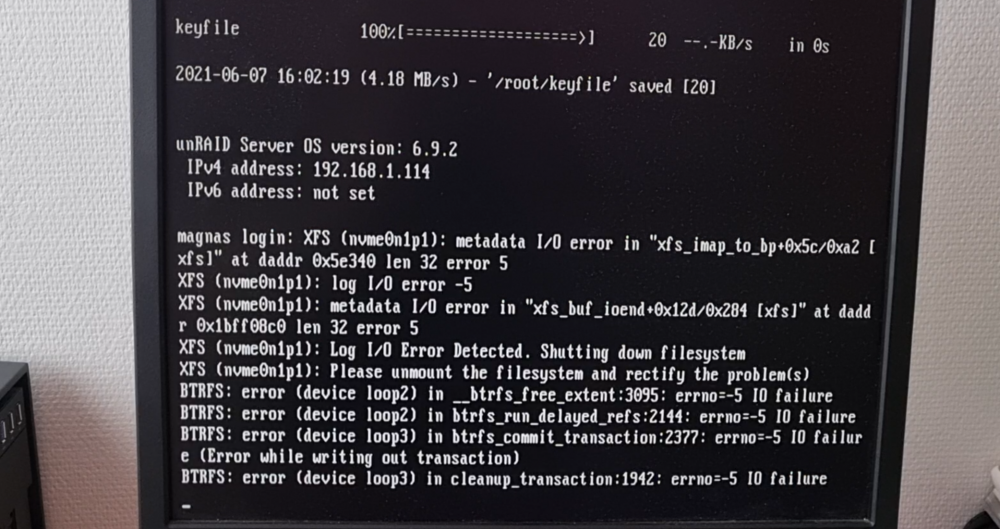
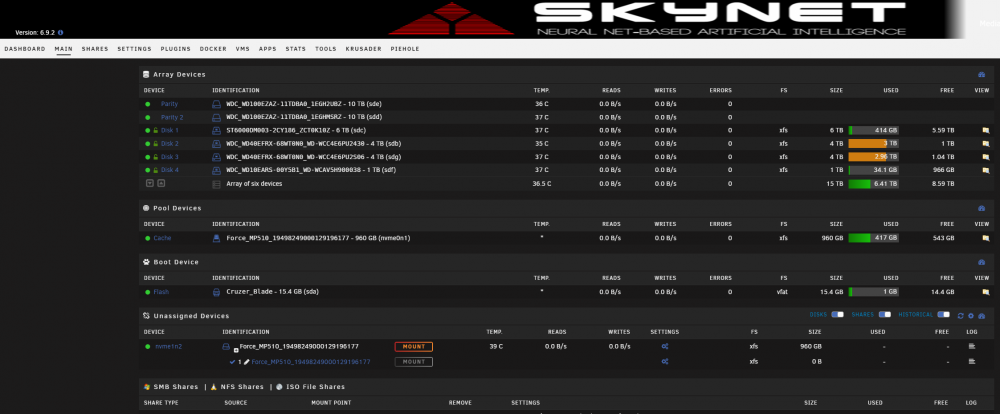
So just a quick update. Plan was to get a new nvme (probably a samsung-one). So to prepare for this, I removed the small EVO250GB from M2_1-slot. And then I installed the "old" Corsair Force MP510 in the M2_2-slot (so that the "main-slot" would be free and clear for when the new NVME-arrived in the mail). Put the server back in it's room and started it up. Yes, the first boot, it didn't understand much of what was happening (due to the removing of, and adding of a new drive) but after stopping the array, assigning the Corsair as the Cache and then starting the array, I did a full server reboot. Once the server came back up (I fully expecting it to eject the drive as previously stated in the diags earlier in the thread) and prepared to stop the array, remove/add the drive and start it again. But to my surprise, now it just worked, totally fine and normal. No ejection of the drive, no I/O error, no nothing.. I was very surprised. So I tried some more reboots and it still holds strong. Very strange indeed. So for now, I guess I don't have to get a new NVME.. (Just need to remember that the SATA1-port and PCIe6-slot is now disabled because I'm using the M2_2-slot..) Again thanks for the help, @JorgeB... Much appreciated //MagmantheHappy Weekend Tried with a new (well used) nvme. Turned off server - Removed the 1TB corsairs Force MP510 (that did work on the "old" hw). Installed a 250GB Samsung 960 EVO, and turned on the server. After boot I took out a diagnostics-zip. The Samsung EVO was discovered as unassigned. I stopped the array put the EVO as Cache-drive and started the Array. Had to format the drive (as it was not XFS) and then it just kind of worked. I then installed 3 random apps/dockers (cause that data lives on the cachedrive) and then restarter the server. Now UNRAID boots totally normally and detects and treats the 250EVO as a normal cache-drive. No ejection or anything. After boot I took out another Diagnostics (for comparison reasons, but that might not be needed). Just based on my experiences here, it does seem that some kind of mix between I guess the MB, Unraid and that specific Corsair-series of NVME's just doesn't play nice with eachother? or? //magmanthe magnas-diagnostics-after_NVME_setCache.zip magnas-diagnostics-firstBoot after nvme-swap.zipHi, Done. Attached is diags from a reboot nothing else. //magmanthe magnas-diagnostics-20210609-1931.zipHi, Thanks for the quick reply, however I have to report NoJoy on this. Added line to the Syslinux Config and rebootet, and the same happens when it boots back up. New picture taken from attached monitor. Regarding BIOS: I upgraded the BIOS to latest from MSI (release 31|st of May I believe) before booting to unraid for the first time, so that is already covered. However something peculiar. If I stop the array, unmark/remove the cache from the pool-dropdown list re-add the nvme to the cache-pool start array. It does seem to work normally again. All dockers (that write to the cahce) function (opening KRUSADER i can browser the cache-drive). So I mean yeah, it works, if I take the time to stop/remove/add/start the array I guess... 🤔 Any clues? //Magmanthe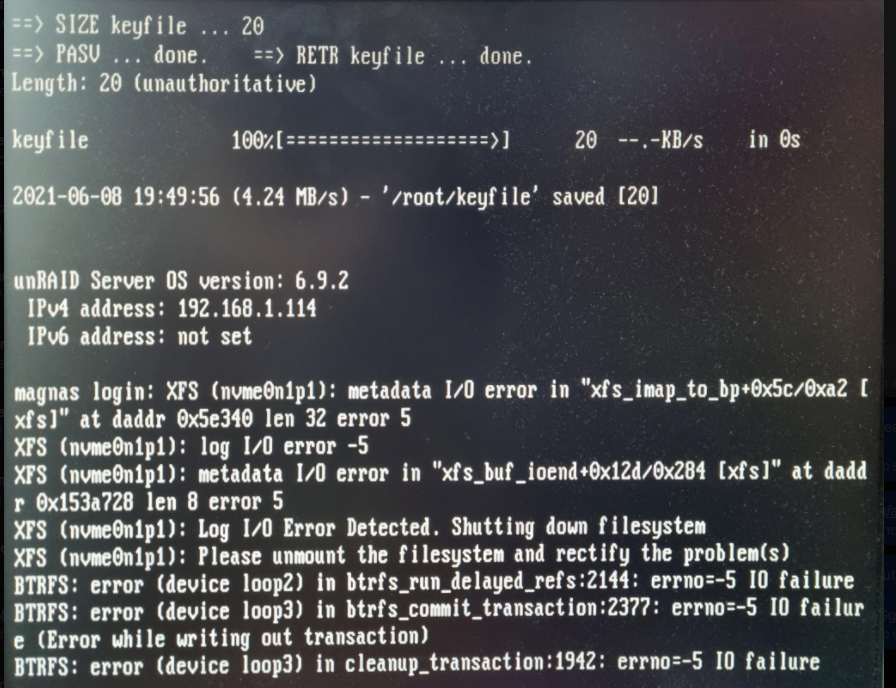 Hey so I had some issues with my old UNRAID HW TLDR I had some issues with a HBA as well as old HW, so I got some new HW and now I have some problems with the Cache-drive. I got an upgrade to the hardware, to the following: CPU – Ryzen 5 3600 MB - MSI x470 Gaming Plus RAM – Crucial Ballistix 32GB HBA - LSI 9211-8i + my old NVME from previous system – Crucial Force MP510 1TB This was also the cache-drive in my "old" Unraid server. So long story short, I started the new server, it boots nicely, and logs-in (checked from WebGui). However there is a problem with the nvme-Cache-drive. MB_Bios sees the Force MP510-drive fine. Unraid also sees it, but it sort of "ejects it"? I dunno 🤷♂️.. Also if I press the "mount"-button (see picture) nothing happens, it starts to mount (with the spinny-circle) for like .5seconds, before it turns back to the Mount-button. Attaching: pic from Server (taken just after auto-download of keyfile and log-in) UnraidWebGui-ss Logfile (without GO-file due to cleartext username and PW) the Cachedrive (nvme) worked fine before the HW-upgrade. I am using the M2_1-slot on the MB. It still has another slot M2_2-slot. I have NOT yet tried to switch it around, I'm trying here first. Reason: if using the M2_2-slot, it will disable SATA1 and one of the PCIe-slots, and I'm trying to avoid this. Thanks for any help and input from you all. //Magmanthe magnas-diagnostics-20210608-1613.zip
Hey so I had some issues with my old UNRAID HW TLDR I had some issues with a HBA as well as old HW, so I got some new HW and now I have some problems with the Cache-drive. I got an upgrade to the hardware, to the following: CPU – Ryzen 5 3600 MB - MSI x470 Gaming Plus RAM – Crucial Ballistix 32GB HBA - LSI 9211-8i + my old NVME from previous system – Crucial Force MP510 1TB This was also the cache-drive in my "old" Unraid server. So long story short, I started the new server, it boots nicely, and logs-in (checked from WebGui). However there is a problem with the nvme-Cache-drive. MB_Bios sees the Force MP510-drive fine. Unraid also sees it, but it sort of "ejects it"? I dunno 🤷♂️.. Also if I press the "mount"-button (see picture) nothing happens, it starts to mount (with the spinny-circle) for like .5seconds, before it turns back to the Mount-button. Attaching: pic from Server (taken just after auto-download of keyfile and log-in) UnraidWebGui-ss Logfile (without GO-file due to cleartext username and PW) the Cachedrive (nvme) worked fine before the HW-upgrade. I am using the M2_1-slot on the MB. It still has another slot M2_2-slot. I have NOT yet tried to switch it around, I'm trying here first. Reason: if using the M2_2-slot, it will disable SATA1 and one of the PCIe-slots, and I'm trying to avoid this. Thanks for any help and input from you all. //Magmanthe magnas-diagnostics-20210608-1613.zip