




Prbecker
Members
-
Joined
-
Last visited
-
Thank you so much for reviewing my config and for the suggestions. I am definitely going to take your suggestions and implement them!
-
Sorry for the delay! Attached is the diag after disabling both. Thank you tower-diagnostics-20240327-1641.zip
-
Agh, you are right, I did not do this step. I missed this portion of your comment when following through on JorgeB's comment. Maybe this is why I can't connect to sonarr? I'm able to connect to/interact with the rest of my containers except for sonarr. It just displays the "cannot connect" page in the browser. I tried deleting the container and re-adding it from the template then deleting the container + image then re-adding it from the template and still no go. It's up, or so it says, but I can't seem to make a connection to it. I am able to click and launch the console. If I grab linuxserver's version of sonarr I'm able to use it but I'd rather try to get this one working again.

-
tower-diagnostics-20240326-1241.zip Output from the Check Filesystem Status: Phase 1 - find and verify superblock... Phase 2 - using internal log - zero log... ALERT: The filesystem has valuable metadata changes in a log which is being destroyed because the -L option was used. - scan filesystem freespace and inode maps... clearing needsrepair flag and regenerating metadata agi_freecount 840, counted 839 in ag 2 sb_icount 1714048, counted 1750528 sb_ifree 4102, counted 13564 sb_fdblocks 366196900, counted 369685270 - found root inode chunk Phase 3 - for each AG... - scan and clear agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 correcting imap correcting imap correcting imap correcting imap correcting imap correcting imap correcting imap correcting imap - agno = 2 correcting imap correcting imap correcting imap correcting imap correcting imap correcting imap bad CRC for inode 3031665751 bad CRC for inode 3031665751, will rewrite cleared inode 3031665751 - agno = 3 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 1 - agno = 2 - agno = 3 Phase 5 - rebuild AG headers and trees... - reset superblock... Phase 6 - check inode connectivity... - resetting contents of realtime bitmap and summary inodes - traversing filesystem ... bad hash table for directory inode 3038392851 (no leaf entry): rebuilding rebuilding directory inode 3038392851 - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify and correct link counts... Maximum metadata LSN (78:1390421) is ahead of log (1:2). Format log to cycle 81. done
-
That's what I figured too. By the time I came back to the console, the mover had finished. At one point I had a lot of containers and honestly I didn't know what I was doing when trying to troubleshoot a problem a few years ago. After finding the resolution to whatever that problem was I just never resized it. Should I modify it?
-
I did need to run it with the -L switch. It ran for a few minutes and the cache drive was able to be mounted. Looks good, thanks again!
-
Thank you, reading through the section now. The mover started running(?) so I'll start the procedure when its complete.
-
Hi all -- I noticed that pihole wasn't blocking ad's this morning and I was unable to connect to the docker instance and some other docker containers so I rebooted my box. When it came back up, I was able to start the array but noticed that my cache disk was unmountable. I'm hoping the disk isn't totally dead or corrupt. Please see attached diags. Thank you! tower-diagnostics-20240326-1128.zip

-
Thank you!
-
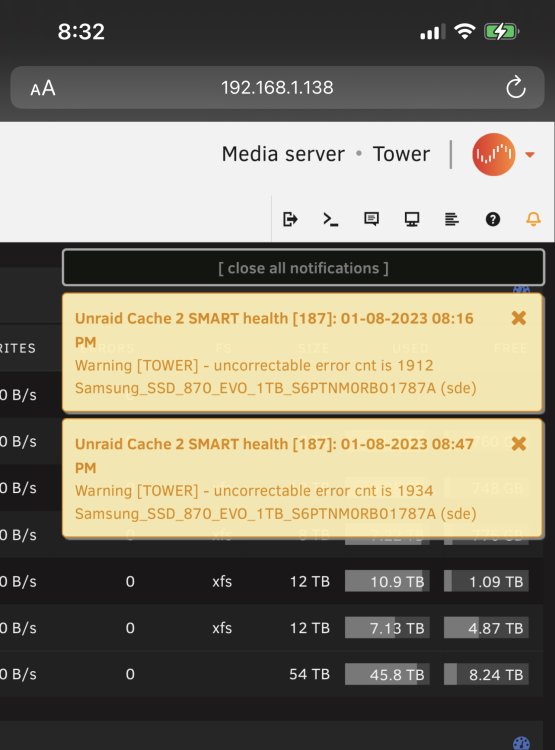
Hello everyone. Recently I have gotten alerts saying that my cache pool has failed the SMART tests stating that there are "uncorrectable" counts. Today, I went to move my shares off the cache pool and onto the array in an attempt to reformat the pool and then if that didn't help, to replace the drives. When i first started the mover, it was moving pretty slowly then eventually crawled to a stop, which is the condition its in now. It's been running for over 12 hours and no progress has been made. I'm kind of at a loss on what to do. What are my next steps here? Thank you. tower-diagnostics-20230802-0858.zip
-
I tried googling around for a release date for v6.10 (unraid shows the "next" branch as 6.10.0-rc2 and "stable" as 6.9.2 which is what i'm currently on) as I'm facing this issue too but didn't have the option to change the setting to ipvlan. Is there an expected release date possibly?




