jbrubaker
Members
-
Joined
-
Last visited
-
Canceled the read check, added the referenced PCIe exemption to the config, rebooted. Disk 11 still reporting disabled with contents emulated. Now reallocated sector count is reading 440, where it said 7 before reboot. The logging exemption doesn't seem to have helped with the PCIe log spam, but here's the diagnostics after the reboot and the array coming up. hyperion-diagnostics-20230718-1214.zip
-
Hello, all. I followed the "Replacing a Data Drive" procedure to replace a non-parity 4TB disk with a 10TB disk (parity is also 10TB). Stopped array, unassigned 4TB, shutdown and swapped disks, turn on, assign new 10TB to 4TB's previous slot, start array, rebuild commenced. Around 7 hours into the rebuild, Disk 11 (which is the new disk I just inserted) gets disabled due to errors: "Disk 11 is in error state" and "Reallocated sector ct is 7". The rebuild process is currently paused at 2.88TB of 10TB and reports "Read-Check in progress." There are "Cancel" and "Resume" buttons on the read check. There was only 2.54TB of data on the replaced 4TB disk, so the rebuild is "past the point" of the previous drive's data; I don't know if that's relevant. I still have the 4TB disk I removed. Should I cancel or resume the read check, and what effect will that have on the drive rebuild/parity sync operation? I actually have another spare 10TB I could in at some point, but I don't want to jeopardize the rest of the disks in the meantime. Attempting to run a SMART test on the disabled disk appears to not work at this point. I can replace the SATA cable as well, but still want to know how to handle the current rebuild/Read-check in progress operation. Thanks for any guidance. disk 11 log.txt hyperion-diagnostics-20230718-0728.zip
-
Just wanted to report back that after about 86 hours of disk rebuilding, everything is functional. Followed the steps in my previous post for each disk, one at a time, and each one rebuilt correctly, even in spite of many of the disks reporting "unmountable" before they were rebuilt. My last few disks were empty, but I elected to rebuild them anyway instead of format, as I wasn't really sure if formatting them would impact the parity disk or not. At any rate, thanks for the help! Just added in the newest disk from Black Friday sales. Onward and upward!
-
Thanks for your help. I stopped array, and mounted one of the array disks in Unassigned Devices. All the data I checked was intact. I unmounted it from Unassigned Devices, and with it unassigned from the array, I started the array. The emulated disk mounted and as far as I can tell the data still looks good, so I think I can proceed to rebuilding the disk. Running the first disk rebuild now.
-
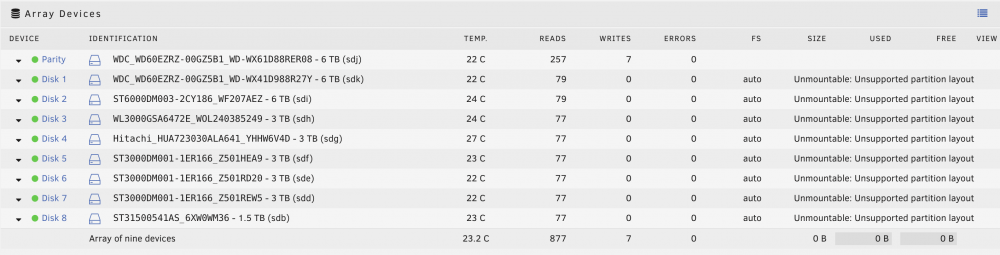
Thank you both for your replies. I attempted the disk move tonight, and as predicted, Unraid said the disks were missing when I booted and "Wrong" when I selected the appropriate disk. I created a new config as recommended by @trurl, checked "Parity already valid", and started the array, then got the "Unmountable: Unsupported partition layout" on each of the disks (except parity) that had been connected to the previous RAID controller (now on the Dell H310). When the system was booting, I believe I saw something flash by about the GPT layout sector something not being at the end of disk or something. I did some Googling and couldn't find many useful hints at what to try. Any thoughts? Edit: Found this in the log: "Alternate GPT header not at the end of the disk" Dec 1 23:42:30 Hyperion kernel: ata4: SATA link up 6.0 Gbps (SStatus 133 SControl 300) Dec 1 23:42:30 Hyperion kernel: ata4.00: ATA-9: ST3000DM001-1ER166, Z501REW5, CC25, max UDMA/133 Dec 1 23:42:30 Hyperion kernel: ata4.00: 5860533168 sectors, multi 16: LBA48 NCQ (depth 32), AA Dec 1 23:42:30 Hyperion kernel: ata4.00: configured for UDMA/133 Dec 1 23:42:30 Hyperion kernel: scsi 4:0:0:0: Direct-Access ATA ST3000DM001-1ER1 CC25 PQ: 0 ANSI: 5 Dec 1 23:42:30 Hyperion kernel: sd 4:0:0:0: Attached scsi generic sg3 type 0 Dec 1 23:42:30 Hyperion kernel: sd 4:0:0:0: [sdd] 5860533168 512-byte logical blocks: (3.00 TB/2.73 TiB) Dec 1 23:42:30 Hyperion kernel: sd 4:0:0:0: [sdd] 4096-byte physical blocks Dec 1 23:42:30 Hyperion kernel: sd 4:0:0:0: [sdd] Write Protect is off Dec 1 23:42:30 Hyperion kernel: sd 4:0:0:0: [sdd] Mode Sense: 00 3a 00 00 Dec 1 23:42:30 Hyperion kernel: sd 4:0:0:0: [sdd] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA Dec 1 23:42:30 Hyperion kernel: mpt2sas_cm0: host_add: handle(0x0001), sas_addr(0x5000000080000000), phys(8) Dec 1 23:42:30 Hyperion kernel: GPT:Primary header thinks Alt. header is not at the end of the disk. Dec 1 23:42:30 Hyperion kernel: GPT:5859352575 != 5860533167 Dec 1 23:42:30 Hyperion kernel: GPT:Alternate GPT header not at the end of the disk. Dec 1 23:42:30 Hyperion kernel: GPT:5859352575 != 5860533167 Dec 1 23:42:30 Hyperion kernel: GPT: Use GNU Parted to correct GPT errors. Dec 1 23:42:30 Hyperion kernel: sdd: sdd1

-
An update was just pushed to the spaceinvaderone/Macinabox repo on github. The (foxlet fetch-macos.py) script which fetches the disk image from Apple was grabbing the wrong ID. The new push changes the parameters passed to that, which in turn fetches the correct Catalina image. Mine was fetching Mojave instead of Catalina. I deleted the old VM and the Macinthebox container. Re-installed the docker from CA, and now it is correctly pulling Catalina.
-
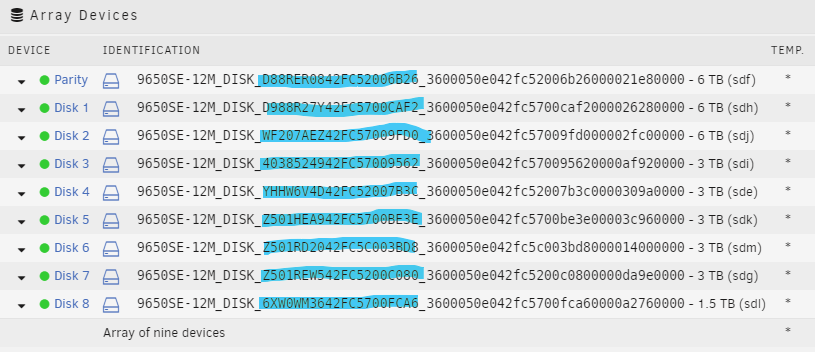
First post. Be kind? I've been running Unraid (currently 6.7.2) for about 4 months now. My SuperMicro dual Xeon server has developed some issues, possibly related to a power outage or insufficient cooling. At any rate, I'm putting together a new-from-used-parts machine (Ryzen 7 2700X, X370) and want to move the drives (and the Unraid USB) to the new machine. Google (and this forum) tell me that Unraid should have no problem identifying the drives and placing them in the correct slot in the array when I first boot the new build. However, I'm a little worried that it will work correctly with my setup. My SuperMicro is using a 9650SE-12ML RAID card which does not support IT mode. The drives are setup in "single" mode in the card config, but the controller still sits in front of the disks and prevents "direct" access (e.g. blocks SMART, etc.) and changes the drive identifier string. Here's one of my disks on the RAID controller with the id string: Oct 29 20:56:25 Hyperion kernel: md: import disk0: (sdf) 9650SE-12M_DISK_D88RER0842FC52006B26_3600050e042fc52006b26000021e80000 size: 5859363788 I am putting an IT-mode RAID card in the new box (Dell H310, LSI 2008) to get SMART support. I am pretty sure that after I swap the drives to the new system/controller and boot Unraid, the disk identifier for each disk is going to be different on the new controller. Do I simply need to make a note of each drive's actual identifier and then manually match them up with the appropriate slots in Array Devices when I boot the new hardware with the old drives (see attachment)? Am I making this too complicated? Am I missing something else important. Thanks for any guidance.