




EdB
Members
-
Joined
-
Last visited
-
I noticed that as well, I pulled it out of the array on the latest array recreation (dropping the power requirements for troubleshooting). I guessed the root cause was possibly power too (either supply or delivery). I have an EcoFlow smart battery on the server so I could get some mains logging to rule out plant power. It also logs the usage and it all shows nominal so I can safely rule out input power. It's a cheap (by cheap I mean price and quality, 80+ bronze and company) PS that I've never used before so I don't know expectations on it. I usually use good quality parts but since this isn't a vital usecase, I tried to cut some corners in cost (I know, stupid me). Thank you for your response
-
This is a backup server and I don't care if I lose the data because I can rebuild from the main unraid system (again, this has been done a half dozen or so times while troubleshooting and replacing components). The following is a lot but I'm trying to keep it in order of timeline. This server has been running great for over a year. Originally, I didn't want to invest much into this configuration because its sole purpose is a network backup location for my main unraid. To that end, the components are modest (were less modest when the issues appeared, has since had upgrade replacements while troubleshooting). This was the original buildout when the issue started: - 16GB RAM Patriot Viper Steel DDR4 3000MHz (not OC) - ASUS Prime B450M-A II AMD AM4 - AMD Ryzen 5 1600 65W AM4 - ARESGAME AGV Series 500W PS (80+ Bronze) - BEYIMEI PCIe SATA 3.0 8 Port (I know, looking for cheap and it worked for a long time) - Mushkin Source-II 500GB SSD (Single cache) - Noctua Industrial cooling 3000PWM throughout (never close to a heating issue) - SanDisk 32GB Cruzer (boot, same as primary system) Drives - Parity: Seagate Ironwolf Pro 6TB Data: - 6x Seagate Barracuda 1TB (old but not failing, scheduled for replacement) - 2x Seagate Ironwolf Pro 2TB (used to replace the 1TBs) How it began and the life of the mess: Numerous power outages within a few days had me shutdown the system after the last successful parity check. It was offline for about 5 days once I was confident the power issues subsided. When bringing it back online, disk1 (a 1TB drive) was disabled (also showed up under Historical Device) so I looked in logs, etc to see the error (I/O read error) and just assumed the disk didn't survive (it was 9y old as most of these 1TBs are). Purchased a new IW Pro 2TB to replace the on-hand spare IW Pro 2TB that was going in the system to replace the disabled disk. Purchases were from 2 different vendors and the time between purchase was over 6 months so the risk of them being from the same lot is extremely low. Disk went in normal, replaced the failed one, rebuilt without an error, and the disk was fully available after rebuild. This ran without an issue for over a week and had a few controlled restarts and one power loss restart of the system (parity check returned good) during that time span. No unclean shutdowns reported for the controlled restarts. Then disk2 was disabled a day later (another 1TB that was just as old). Purchased an IW 4TB (2TB Pro drives were the same price as the non-Pro 4TB drive) to have as the next spare as the current spare was replacing the failed drive. Purchases were not from the same vendor as the one a month earlier. Rebuilt without an issue with the IW Pro 2TB spare. A day later, disk1 was in an error state, rebuild procedure and it was online (swapped with a different IW Pro 2TB spare from my main). Couple of days later, disk2 disabled and performed the same rebuild. The disabled drive would bounce between the 2 disk slots over several days for which one would be disabled. At this point, I'm figuring the SATA card and/or cables were the cause. Replaced the card with an LSI 9211-8i P20 IT Mode (same card/FW as main system) and that also caused all the cables to be replaced. Rebuilt everything with a new config, everything was fully online, and so I started the entire main system backup that ran for a few days. After backup was completed, restarted the system and it was back online with everything green. Ran without an issue for almost a week and it was time to update unraid (this is my backup but also i use it to test new versions before upgrading main). Upgrade was successful and everything green (6.11.3). Several days later, 6.11.5 was released so I upgraded and restarted. After boot, disk1 was disabled (I/O read errors) so I replaced it with another IW Pro 2TB that I had spare for my main system, rebuilt successfully. Over the night, Disk2 disabled. Bought a new DIMM to expand to 32GB (same brand/model) and rebuilt drive again (ran it with the new DIMM only to see if it was a RAM issue). Next day disk2 disabled again. Bought a new CPU (Ryzen 5 5600G w/graphics) and rebuilt it again. Next day, disk1 disabled. Decided to remove disk1 entirely (thinking was maybe the PS isn't giving enough power at 500W when backing up/spinup/etc (since I did upgrade drives); power test later shows it's peaking 193W during boot but idle at 74W). So then I decided to buy WD Red 2TBs x2 (not shucked ones; purchased at the same time which is a break from norm for me). Everything back green and it runs for 2 days before another restart. On bootup, (with no disk1) disk2 is disabled again. Replaced it with the other WD Red 2TB, rebuilt it to green, and good until restart. Disk2 disabled. Inserted the IW 4TB (non-PRO) and decided to do an Unassigned Drive Preclear (I know it's not required anymore) and it error/fails after the pre-read is completed (EVERY disk I have fails here, it's not uncommon from what I've read). Installed Seagate tools on my windows system and attached the seagate drives for the tool tests and everything comes back good, also check all the WD Reds and they report good. Unraid also SMART reports each drive good with an extended test (again, all different vendors/lots). At this point, I've replaced all the hardware except the MB (which at one point during troubleshooting I had 6 drives on the SATA ports and it was still happening with slots 1 & 2), the parity, and the PS. Where I know there's an outside chance of it being one or both of these guys, I want to make sure before I basically upgrade something meant to be cheap into something more expensive. Is there anything within unraid that can cause this behavior or are there commands/settings that could be set to offset or stop the behavior, maybe different steps for a complete rebuild (I couldn't find any bug reports but I have seen several experiences reported that are closely similar)? I don't think the issue is with the drives (too many different manufacturers/lots) and it's such a slim chance of being the HBA that's failing the exact same disks over and over but not at the same time or everytime. I'm a WinServer engineer of 20+ years so I have vast server experience but I sadly lack in top end nix administration. I have been running my main for over 5y without any issues like this and the 2 systems are very similar in build. I can probably follow descent guidance but I'd say my knowledge in complex terminology is not on par with most of the admis here. I don't mind blowing it all away and starting from scratch, I have my main server with the prod data and I have a current offline backup so there's no risk in dataloss. I appreciate any help in advance! homenas-backup-diagnostics-20221208-1531.zip
-
Yes, correct date and time as well as the timezone. However, I think my time management is not quite right for this docker. If I run a scheduled task for a specific time on a specific day, it doesn't run until 19hours after that time (i.e. 2am executes at 9pm of the same day)
-
Finally got an opportunity to try some things. - Putting the server to v4+v6 did not further the error - Added "-o tls=yes" in the ARG line to try and force it to TLS and it did pop a new error indicating keys are not functioning. Due to the last error, and your ability to send email, I'm going to demise that it's something misconfigured or not configured on my system and the feature is functions (thanks for that!). Mine is pretty much out of the box with only a few dockers/plugins/VMs for internal usage. I've not setup remote access/administration so I've not had a need for nginx or any other similar type of remote tool. I'm guessing something along this line needs setup in order to establish TLS connections. Dockers do have internet access (like Emby, Plex, etc) so I know the bridge is working. I'll need to do some system troubleshooting to see if I can figure this part out Thank you so much for all your hard work, it is very much appreciated! ed
-
I had already tried it, it's the same INET6 error. It also doesn't automatically select the correct port, it tries 25 by default, I suspect this is because it can't get an outbound connection. I added the port to the server to try and it failed as well. I tried gmail and my own personal cloud mail server without success. From what I can tell, I have my OS network settings to use v4 Only but the docker is trying to use v6 as a default (probably the default lo for v6 that Unraid uses is causing it to appear as an available protocol). My next test is to switch the network settings to use v4 and/or v6 and retest but I can't shutdown VM and docker right now. Adding that SHOULD provide the ability for it to bridge to v4 (hybrid approach) but I'm uncertain how complex the Unraid failover configuration works. I'd rather turn on v6 for the server than to remove routes. I'm thinking that will work, or at least give a further error beyond this one. I should be able to make the switch in about 10 hours and then I'll send an update. Thanks!!!
-
Same error. After a little more investigation, now that I have confirmation that adding the port to the servername is functional, it might be a TCPIPv6 binding issue. IF INET6 is indicating the correct error, that is. Apparently, it's a common enough issue with docker where it will bind to v6 and if you're running v4 it will fail. From what I've gone through so far (about 20 postings), there's no "easy" way to fix it and sometimes it's confined to an OS and docker combo (although this is muddled too because some say it works correctly on their same OS). I'm not certain specifically, and will continue to scour. My google-fu is still running validation but I thought I'd respond with the preliminary findings. Thanks again!!!
-
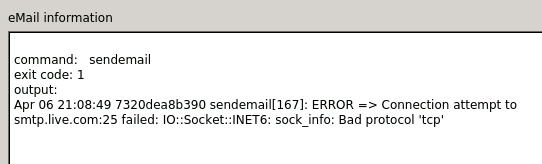
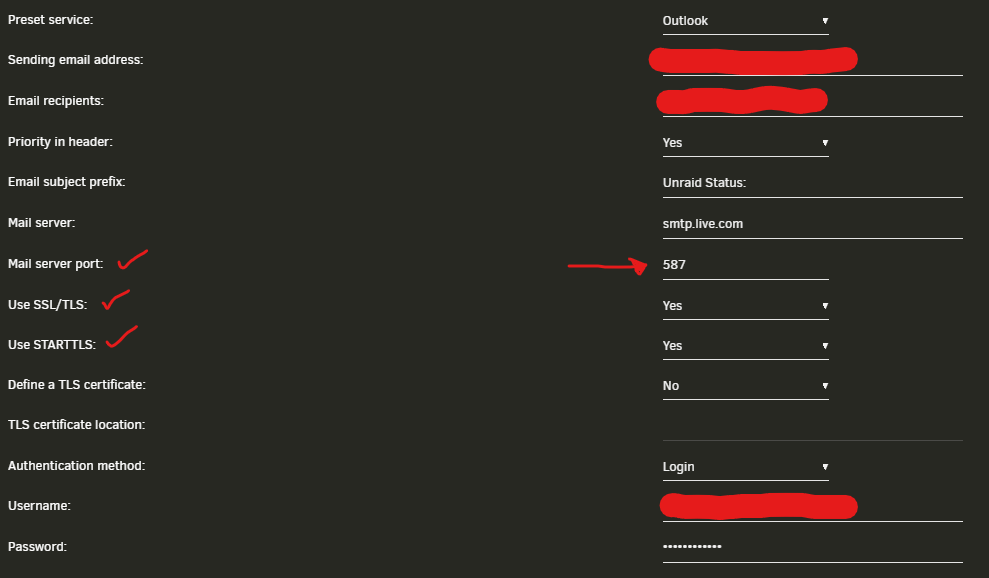
Thank you for the quick work! Unfortunately, it didn't work and I think it's because it uses the default port 25. is there a VAR for port selection? smtp.live.com uses a different port (587) and it'd be more configurable for other servers or relays using a VAR for the port. TLS was used during the attempt and this is definitely further than initially tested. Thank you so much for this effort!
-
Correct. I'd like to use it, if available. Is another method being used elsewhere or are people not sending status emails for jobs?
-
luckyBackup question: I've been trying to figure out how to get the email feature to work so I assume I'm missing critical information in setting it up. LB documentation mentions installing packages (whatever you want to use) and use the command for that package. unraid already has built-in mail function (I use this with my user.scripts) but what I can't figure out is how to get that to work with LB, if possible. I'd prefer not to introduce additional software when a function is built-in (redundant to me) and I'd like to keep the process as simple as possible. Could someone please help me by pointing me in the correct direction for a resolution? I'd like to transition to LB from the user.script backup solution I'm currently using but without the email function it is not desirable for my requirement. Thanks in advance, ed


