




LFletcher
Members
-
Joined
-
Last visited
Everything posted by LFletcher
-
I've been having a look. In reality it shouldn't be too difficult to work out what goes where as its either a movie or a tv series/episode. I suppose I didn't expect everything to be in a lost+found directory, but as I've never done this before - you live and learn. I'll wait for the scan of corrupt files to finish, but what is my next step? Is it to unassign Disk 5 (physically remove it from the server), and then assign this cloned disk in its place? If I do that will unRaid recreate the old folder structure and I'll just have to manually move things into the correct place or will I have to do something else? Also what are the next steps to sorting out the issues with both Disk 3 (which we unassigned earlier) and the Parity 2 drive which also has issues still? Thanks
-
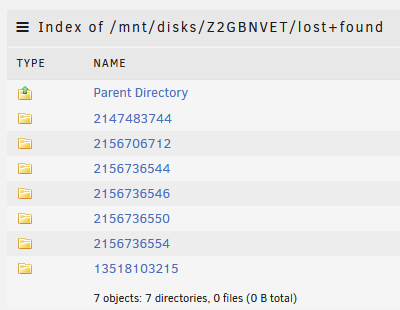
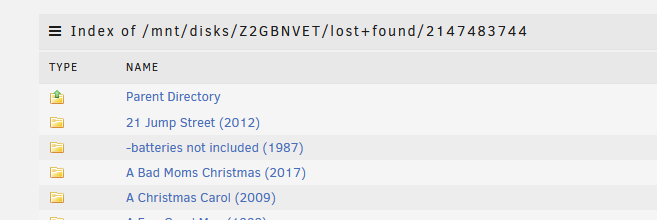
ddrescue has now finished. I then ran the xfs_repair against the cloned drive; I've now run the following commands from the ddrescue faq; printf "unRAID " >~/fill.txt ddrescue -f --fill=- ~/fill.txt /dev/sdd /boot/ddrescue.log find /mnt/disks/Z2GBNVET -type f -exec grep -l "unRAID" '{}' ';' which is still in the process of running. When looking at the data on the mounted cloned drive everything appears to now be in a lost+found directory Shouldn't the cloned drive have a directory structure that mirrored the original disk? I assumed after the check I would have been able to unassign the old bad drive (Disk 5) and assign the cloned drive in it's place, restart the array and this part of the issue would be resolved. I guess with just the lost+folder that is not going to be the case or am I missing something?
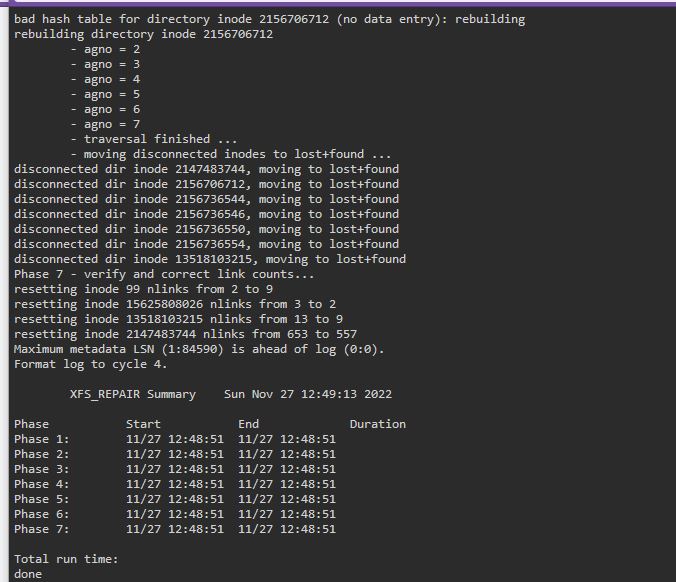
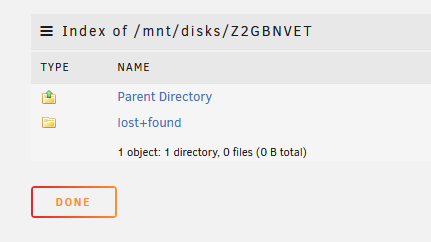
-
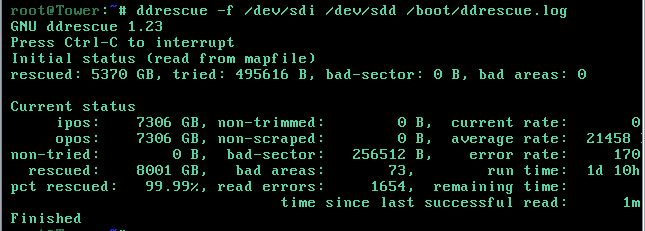
Is there any way to speed up the ddrescue process? It's been running for about 30 hours and it less than 70% done of pass 1 (ignore the run time on the screen shot, I had to restart it after 24 hours, so this is the second run)
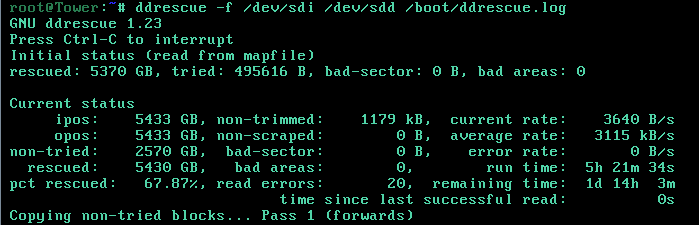
-
I have copied the important stuff onto another (external) drive. Ran the -v command and got this; So then ran the -vL and got this; And also these notifications;
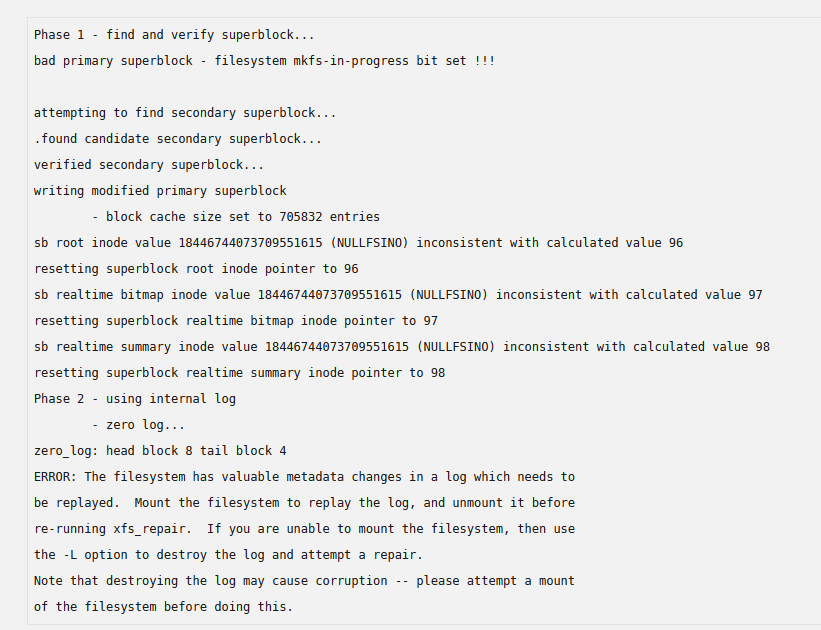
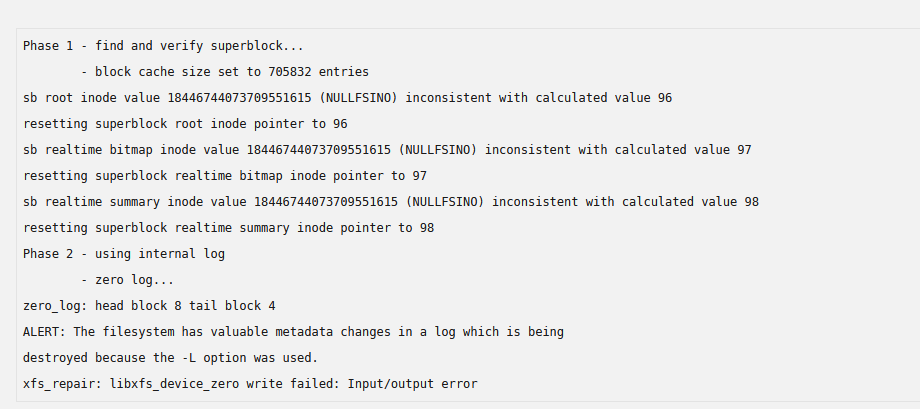
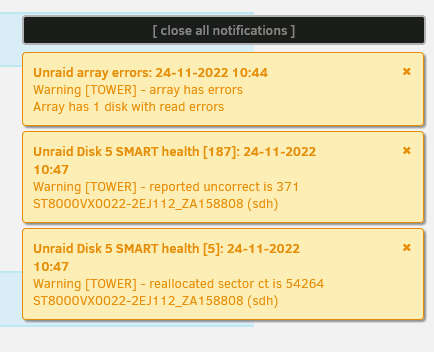
-
It's not my machine (I'm trying to sort it out for a friend), but it's safe to assume there won't be any backups. I know there are photos on the array, but I don't know where they are, or whether they are likely to be on any of the impacted drives. Obviously in an ideal world we'll be able to restore all of the drives without losing any data, but in an ideal world he would have paid more attention when the box started having issues (and given it to me sooner). What options do we have, assuming we have no backups to rely on and I need to try and save as much of the data as possible? All of the assistance I have been given so far is very much appreciated.
-
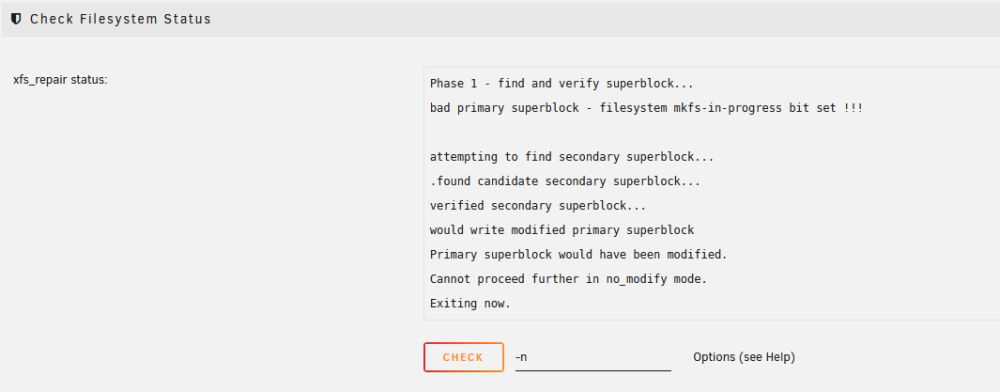
OK, so I restarted the array in maintenance mode and ran the check with -nv and this was the output I assume I now need to run; -v /dev/md5
-
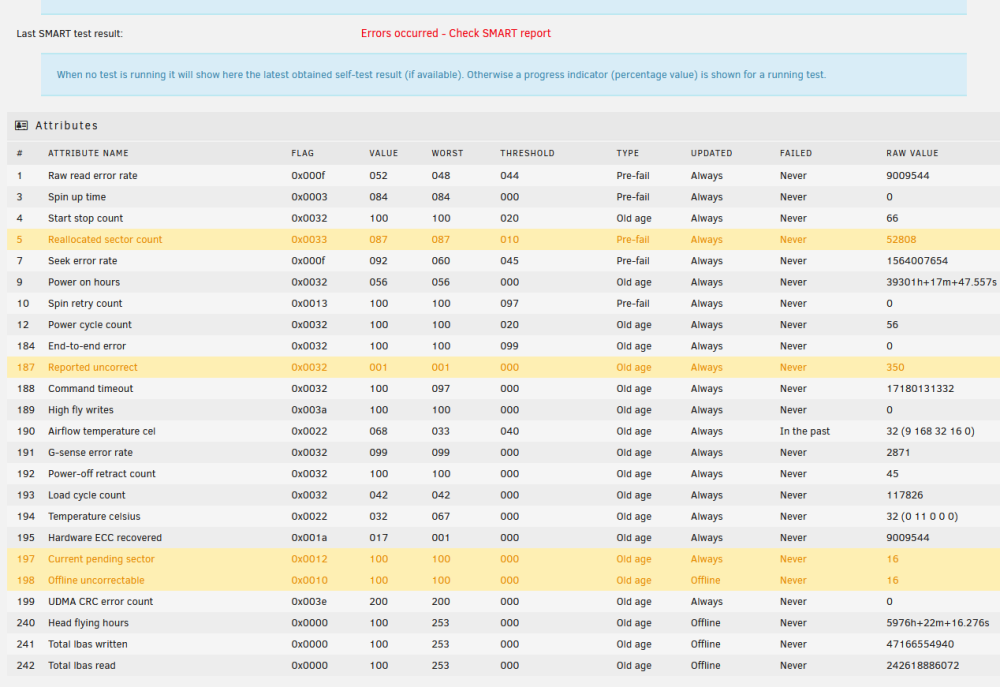
Yes, the disk was unassigned when I started the server, so I reassigned it, but I hadn't started the array up until now. I have unassigned disk 3 and started the array. Disk 3 now resides in the unassigned devices section Disk 5 isn't happy though and states its unmountable I've attached the updated diagnostics file. tower-diagnostics-20221123-1623.zip
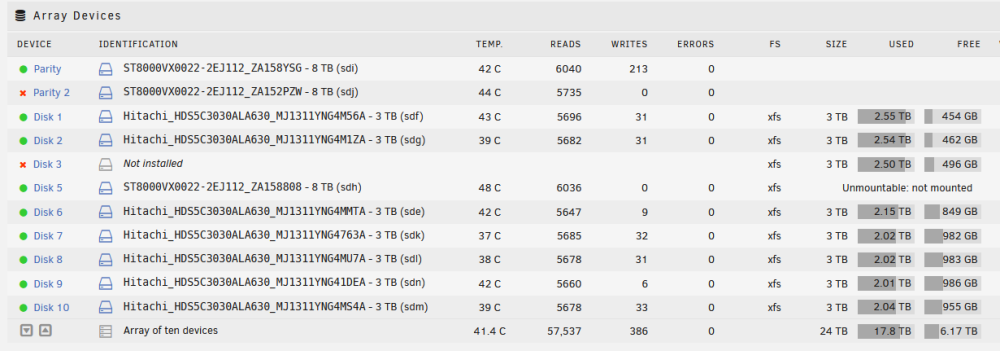

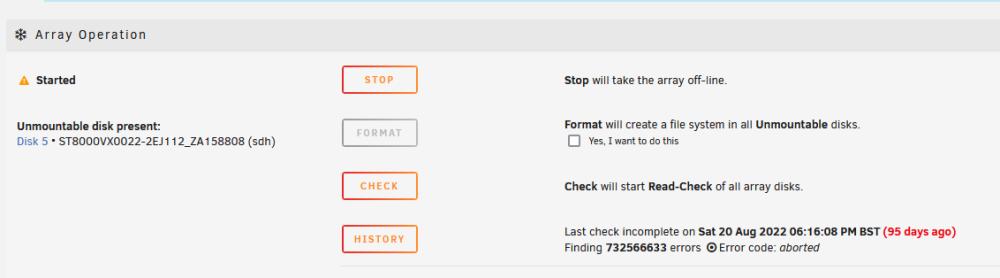
-
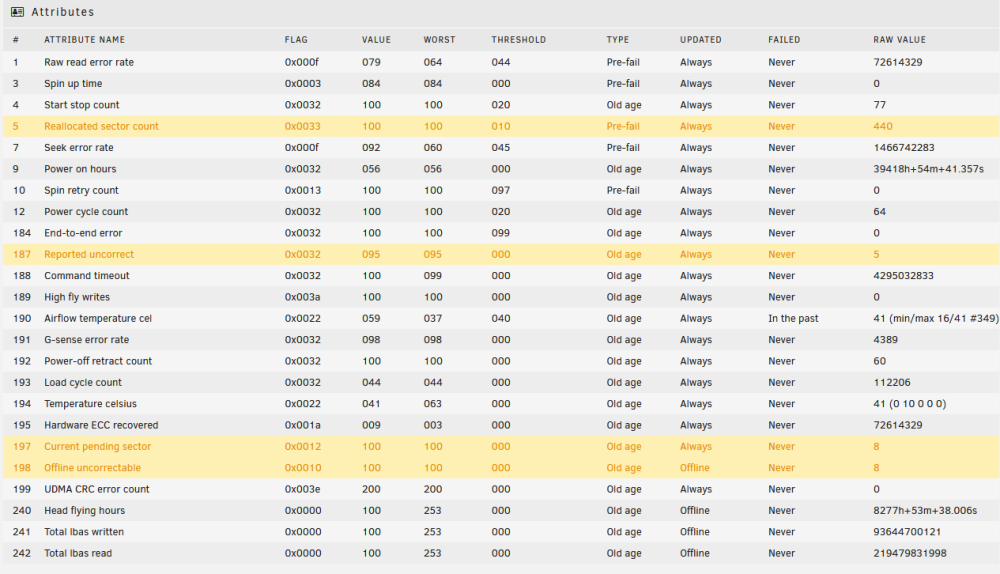
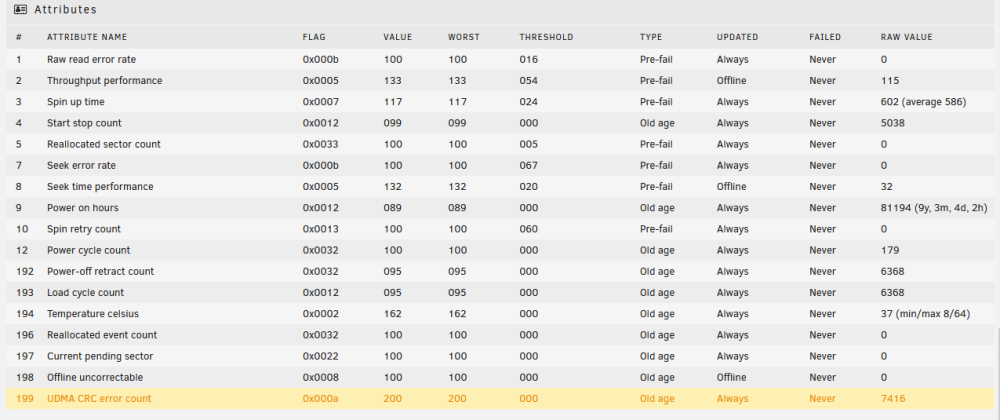
Parity 2 passes a SMART test, but unRAID isn't happy with the results Disk 3 was unassigned when I booted the server up. When I allocated the drive thats when the udma crc message popup box came up. The drives are on a miniSAS backplane so it's unlikely to be a cable issue causing the crc errors. To the best of my knowledge I don't believe anything has been written to the emulated disk 3. Thanks
-
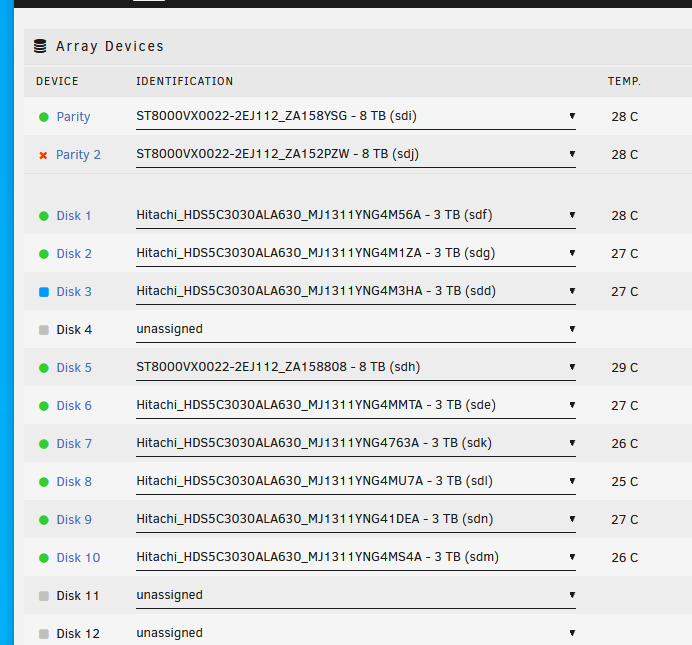
Hi, Helping a friend who has some issues with his unRAID server. My understanding is that the parity drive had issues first of all and went offline (Parity 2). Then there was issues with a data drive (disk 3 - sdd) - this appears to have udma crc errors. I did SMART checks on the other drives and it appears Disk 5 (sdh) has issues as well, although it hasn't failed the drive (yet). I've got 3 14TB drives, which I had originally planned to replace both the parity drives with and also disk 3. Now that disk 5 also has potential issues I can get another 14TB drive to replace that. My question is, can the data from disk 3 be recovered or is it lost? If it can be recovered whats the correct order to do things in? Do I need to copy the data from disk 5 before that has any more issues? I've attached the diagnostics file as well. Thanks in advance. tower-diagnostics-20221123-1310.zip
-
Hi, I've had similar issues to others with the new beta plugin with regards to it filling up the /var/log space. Started a thread here as I didn't realise it was due to the plugin, https://lime-technology.com/forum/index.php?topic=47893.0 I've run, mount -o remount,size=256m /var/log and I can see that has extended the space. Will it have broken the 2 preclears that I have been running against some 8TB Seagate drives or will it have kept on running? It also appears to have had the side effect of preventing me from accessing my unRAID shares from a windows machine (but I assume that due to the /var/log space filling up).
















