




eribob
Members
-
Joined
-
Last visited
-
Yeah, I have experienced that before, dont know why I did not think of it. Thanks for pointing me in the right direction!
-
Yep it looks like that was the problem, thanks! My GPU used to be on address 0e:00.0 and bound to the workstation VM like this: <hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x0e' slot='0x00' function='0x0'/> </source> <address type='pci' domain='0x0000' bus='0x04' slot='0x00' function='0x0'/> </hostdev> <hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x0e' slot='0x00' function='0x1'/> </source> <address type='pci' domain='0x0000' bus='0x05' slot='0x00' function='0x0'/> </hostdev> When I installed the new NVMe the addresses changed so that the enterprise NVMe instead got that address: IOMMU group 28: [8086:0a54] 0e:00.0 Non-Volatile memory controller: Intel Corporation NVMe Datacenter SSD [3DNAND, Beta Rock Controller] [N:1:0:1] disk INTEL SSDPE2KX080T8__1 /dev/nvme1n1 8.00TB Since I did not check that, the VM probably tried to bind the enterprise NVMe to it when it started and that caused it to become disconnected? I changed the address in the VM xml to 0f:00.0, and now it works as normal. IOMMU group 29: [10de:1b82] 0f:00.0 VGA compatible controller: NVIDIA Corporation GP104 [GeForce GTX 1070 Ti] (rev a1) [10de:10f0] 0f:00.1 Audio device: NVIDIA Corporation GP104 High Definition Audio Controller (rev a1) Again thanks for the hint! I am just sorry I did not find the source of the problem that this thread was originally about though...
-
OOOHHHH thanks! Now I need to test something: When I installed the new NVMe drive the vfio binding for my GPU disappeared and I had to rebind it at boot. Maybe the enterprise NVMe was somehow accidentally bound to the workstation VM instead of the GPU? And since the workstation VM is on autostart it would bind the enterprise NVMe... I will test and post back!
-
OK, I am sorry but that comment is not really helpful to me. What happened was that when I installed the new NVMe, the old one "enterprise" stopped working. In the "main" tab I could no longer see used/available space. Since all dockers and VMs are on that drive, none of them were working. This happened immediately when I started the array. I tried rebooting the server and the same thing happened again. So I shut down the server and took the new NVMe drive out and now the old one ("enterprise") is working as normal again. The "enterprise" NVMe is attached to a PCI-e → SFF 8643 card with a SFF 8643 → SFF 8639 cable. The new NVMe was attached to the first M.2 slot on the motherboard.
-
Hi again! Sorry for the long delay, and for not marking this as solved despite your excellent efforts JorgeB. Maybe I got closer to the solution today. I installed a new NVME drive in the server (one of the M.2 slots) and suddenly my enterprise M.2 SSD that has zfs stopped working. I got the following in the system log (could not run diagnostics): Jun 7 17:14:13 MONSTERSERVERN kernel: WARNING: Pool 'enterprise' has encountered an uncorrectable I/O failure and has been suspended. Jun 7 17:14:13 MONSTERSERVERN kernel: Jun 7 17:14:13 MONSTERSERVERN kernel: WARNING: Pool 'enterprise' has encountered an uncorrectable I/O failure and has been suspended. Jun 7 17:14:13 MONSTERSERVERN kernel: Jun 7 17:14:13 MONSTERSERVERN kernel: WARNING: Pool 'enterprise' has encountered an uncorrectable I/O failure and has been suspended. Jun 7 17:30:43 MONSTERSERVERN kernel: zio pool=enterprise vdev=/dev/nvme1n1p1 error=5 type=1 offset=1768154103808 size=102400 flags=180880 Jun 7 17:30:43 MONSTERSERVERN kernel: WARNING: Pool 'enterprise' has encountered an uncorrectable I/O failure and has been suspended. Jun 7 17:30:43 MONSTERSERVERN kernel: Jun 7 17:30:43 MONSTERSERVERN kernel: WARNING: Pool 'enterprise' has encountered an uncorrectable I/O failure and has been suspended. This happened immediately on boot and the drive was unusable. I tried simply removing the NVME drive and now it works again. Another thing I recently did was enabling autostart on my workstation VM (Fedora 40) with GPU passthrough. I am now suspecting that this is power issue, perhaps my powersupply is old or too small? It is a 750W unit. Corsair, pretty good quality, but 5 years old now. Perhaps it gets overloaded during boot if all dockers are starting in addition to the VM with the GPU etc? Or do you have any other suggestions? Why would installing one NVME drive cause another (U.2 drive) to fail? /Erik syslog 2.txt syslog.txt
-
An update: Ran memtest, no errors after 8 hours, see attached images. I am using this PCI-e to SFF-8643 adapter to connect the U.2 drive: https://www.amazon.se/dp/B0B6CJ889T/ref=pe_24982401_506182521_TE_item Do you think that may cause these issues? /Erik
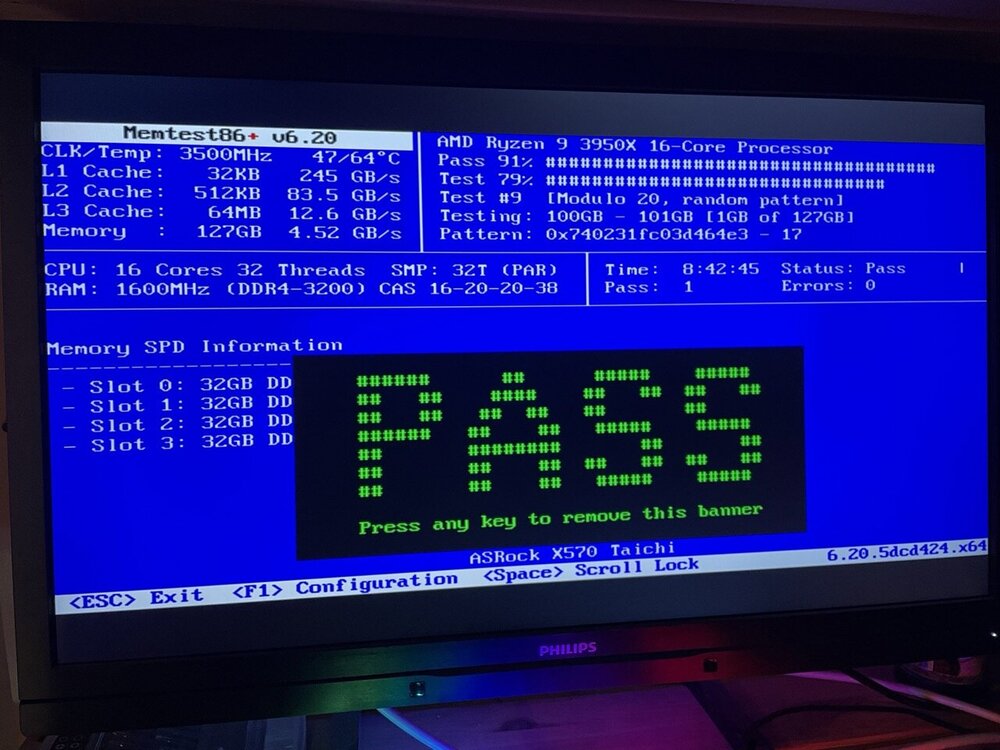
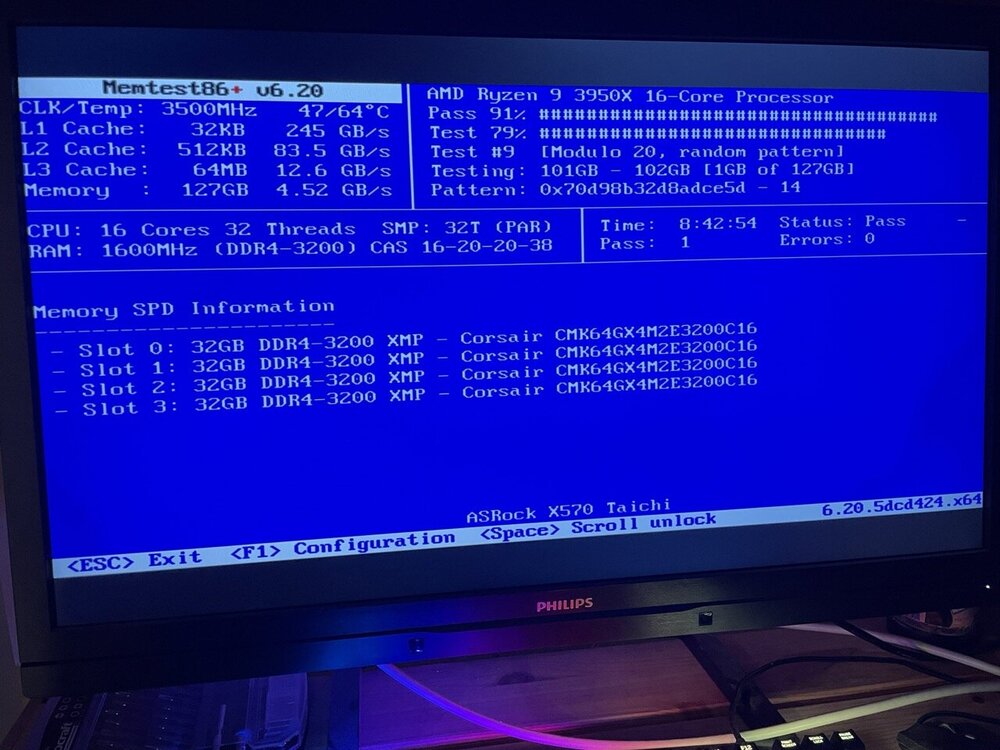
-
OK, will start by running memtest tonight. Should I performe a zfs scrub on the pools? Can that detect this kind of errors? I have also seen some wierdness since moving to zfs. I have made each of my appdata folders a separate zfs pool (spaceinvader one video...) and some of them are not accessible in krusader. It says "cannot open the folder" when I try. Is this a permission issue or normal behaviour when trying to access zfs pools from krusader? The folders are accessible thorugh the unraid gui and I can cd into them in the terminal. BTW, the reason I am hesitant to recreate the file system is that I do not have any redundancy in my pools. I have one on the NVME and one on one of the array drives. I backup the nvme to the array every night with ZFS snapshots and replication. I can wipe the nvme and restore from backup but it will take some time...
-
OK that's unfortunate. The U.2 NVME was probably more heavily utilised, but I find it hard to believe that a brand new enterprise nvme would fail. Is there a way to test a zfs pool for errors?
-
Thank you for spotting this. Does it give any information about where the problem might lie? I have 2 drives with ZFS, one U.2 Intel P4510 that is bran new and has a very good endurance rating, and one HDD that is also quite new, no smart errors reported so far. Or could it be a RAM issue? I do not have ECC. How do I recreate the zfs file system? Do I need to format? Does it say which zfs pool is causing the issue?
-
I have had the same issue twice during the last weeks now. The unraid web gui suddenly becomes unresponsive and some of my docker services are no longer reachable. If I open the webgui in a incognito window I get to the login prompt, and when I enter "root" and my password the unraid GUI becomes blank and loads forever without giving me a 404 or a 503 or any error. The server is still reachable through ssh, and some docker services can be accessed. My windows 11 VM was still working normally. I tried to get the diagnostics through the terminal with the "diagnostics" command but it never finished. I instead copied the syslog to the USB and attach it here. I tried to both restart `/etc/rc.d/rc.nginx restart` and kill the nginx process but it did not work. ps -aux | grep nginx gave me a list of processes, and after trying to kill them with kill -9 [PID] a list of 4 processes with `D` status (uninterruptable) remained. I tried to restart the server with `reboot -n` but nothing happened. Finally I had to pull the plug on the server. After rebooting, everything is back to normal (except for complaints about unclean restart). Attaching diagnostics that I took once the server was back up again. Since this has happened twice now I would appreciate any help you guys can give me on what might be the issue. Best regards Erik monsterservern-diagnostics-20240519-2203.zip syslog_240519.txt
-
I have the exact same problem. Followed SpaceinvaderOne's guide to setup appdata folders as ZFS datasets. Then tried to remove old folders containing data for apps that I do not use anymore. I tried first using the "ZFS master" plugin in destructive mode, but got "Operation not permitted" error. The same when using the command line: `zfs destroy -fr [DATASET]`. It worked when I first use your command `zfs set mountpoint=none [DATASET]`. Why is this necessary? Is there a way to automate this so that I can remove pools using the GUI?
-
thanks, did not read carefully before buying. Placed an order for that cable now.
-
Hi again! Finally got around to buying an M.2 drive! I ended up with an intel p4510 8TB drive instead. It is PCI-e 3.0 but I figure that is enough and the IOPS are great. Anyway, it works fine, but I am getting slower read/write speeds than expected. I tested writing a large file from the drive to a RAM disk and got around 1.2GB/s (expected around 3GB/s). I am wondering if the cable is the issue? I bought this cable: https://www.amazon.se/dp/B097BDG3TX/ref=pe_24982401_503747021_TE_SCE_dp_1 It says SAS 12G or internal NVMe, could it be that it is limited to 1.2GB/s? Perhaps 100cm is too long to allow for max speeds? In that case I will buy the same cable you bought and try again. The PCI-e card I bought is this one: https://www.amazon.se/dp/B0B6CJ889T/ref=pe_24982401_503747021_TE_SCE_dp_1 - could it be the problem? However, it should just be a dumb link from the PCI-e slot to SFF-8643 ports so perhaps it should be fine? /Erik
-
Thanks, I think the problem was actually that I updated the BIOS today and that reset the IOMMU setting so It was suddenly off and no PCI passthrough was working, when I enabled that again the warning messages about the flash drive disappeared. I think I will run a memtest as well though, had some other problems with BTRFS today.
-
Hi! Several problems at once today... Suddenly I started getting messages that my flash drive is corrupted. Attached diagnostics. I can however browse the contents in the Unraid GUI and I managed to create a flash backup. Do I need to replace the flash drive? /Erik monsterservern-diagnostics-20240130-1543.zip


