




Crad
Members
-
Joined
-
Last visited
Everything posted by Crad
-
Thanks, I'll have to do some testing.
-
Ahh of course. So does that mean fuse overhead will be lower if the share is only stored on ZFS pools? (e.g. share is on ZFS nvme pool + ZFS hdd pool). The theory being that the zfs drives are always spinning and should be faster to assess the file structure?
-
That's good to know. 95%+ of my I/O is large files. file open overhead is tricky, because all the actively used data will be on ZFS pools, not the main Array, so hopefully no Fuse overhead there?
-
Hi All, I have a high I/O workload, and I'm wanting to streamline the system with a fast NVMe tier that machines can write finished files to quickly, which Unraid then automatically moves over to a bigger ZFS pool in the background. I have 3 enterprise U.2 7.68TB NVMe drives to use for this fast target and my idea is: Migrate our ZFS pool from TrueNAS to Unraid Create a RAIDZ1 pool with the 3 NVMe drives with: - An exclusive share on it as a write-only drop zone (so bypasses FUSE for full speed). - A normal share with the NVMe pool as primary and the main ZFS pool as secondary target. A little script that watches the exclusive share and when a file finishes writing, moves it into the user share. Since both are on the same physical drives, the move should be instant and the file stays on NVMe until the mover shifts it later. E.g. Writes to/mnt/nvmeRaidZ1/ExclusiveShare ---> Script Immediately moves completed file to /mnt/user/NormalDataShare (where this share is on the same nvmeRaidZ1 drives) ---> Mover handles from there. My questions and concerns are Is moving a file from an exclusive share into a user share on the same pool actually instant, and will the mover then handle it normally? Anyone doing something similar, if so, how well does it hold up? Is there a simpler built-in way to get "fast write tier that drains to bulk" that I'm missing? is FUSE going to actually cause a noticeable slowdown for a RAIDZ1 pool of U.2. NVME's? Extra Info/Context: I currently have the ZFS pool on TrueNAS as a VM on Unraid. I've not migrated because I was waiting for a significant enough reason to do so - which I think could be this. If Unraid isn't the right solution for this, I'm open to other suggestions, even keeping TN as a VM and setting up something on that. Hardware Deets: Single-socket EPYC server, plenty of PCIe/RAM 3× enterprise U.2 NVMe (planned as a RAIDZ1 pool — the fast tier) ~300TB ZFS pool (the bulk/capacity tier) Unraid 7.3.0 Dual 25GB SFP uplinks.
-
@JorgeB thanks for the instructions, I'll jump into that as soon as the server has some downtime. One thing I believe is true is that I can happily start and stop the array if I have only just booted (i.e. not started VM's or Dockers at all).
-
Hi all, Diagnostics attached I’m hoping someone can point me in the right direction. Whenever I press Stop on my Unraid array it just sits there saying “Unmounting disks…” over and over. I’ve already shut down every VM and Docker container first, but the array still won’t complete the stop. What I’m seeing every few seconds in the log is something like this (the exact directory changes): Retry unmounting disk share(s)... Unmounting disks... umount /mnt/cache_big umount: /mnt/cache_big: not mounted. exit status: 32 Eventually I give up and force-reboot, which I know isn’t ideal. Sometimes I've found running umount -l /mnt/user will help it finalize the array stop but from my understanding this is also not ideal. My setup Fairly big array - 29 disks, 500TB - plus two cache pools. A handful of remote shares (truenas) mounted with the Unassigned Devices plugin. No VMs or Dockers running when I try to stop the array Things I’ve already tried: Stopping Docker and libvirt in Settings. Making sure no computers on the network are browsing the shares. (though we do have shares mounted as drives on machines) Waiting (sometimes for an hour) – the message just keeps repeating. I’m not very technical, so if there’s a straightforward checklist or setting I’m missing, I’d really appreciate it. I just want a reliable way to shut the array down cleanly without digging into the command line every time. Thanks in advance for any advice! diagnostics-20250702-2214.zip
-
Thanks JorgeB, I'll keep an eye out for v6.13 and migrate when I'm confident of the zeroday bugs being resolved. Appreciate the help!
-
I tried fdisk -l but was getting errors. I instead tried 'gpart show' and got the below read out. Hopefully this has the answer. root@truenas[~]# gpart show => 40 104857520 vtbd0 GPT (50G) 40 532480 1 efi (260M) 532520 104300544 2 freebsd-zfs (50G) 104833064 24496 - free - (12M) => 40 35156656048 da1 GPT (16T) 40 88 - free - (44K) 128 4194304 1 freebsd-swap (2.0G) 4194432 35152461656 2 freebsd-zfs (16T) => 40 31251759024 da7 GPT (15T) 40 88 - free - (44K) 128 4194304 1 freebsd-swap (2.0G) 4194432 31247564632 2 freebsd-zfs (15T) => 40 35156656048 da4 GPT (16T) 40 88 - free - (44K) 128 4194304 1 freebsd-swap (2.0G) 4194432 35152461656 2 freebsd-zfs (16T) => 40 35156656048 da10 GPT (16T) 40 88 - free - (44K) 128 4194304 1 freebsd-swap (2.0G) 4194432 35152461656 2 freebsd-zfs (16T) => 40 35156656048 da13 GPT (16T) 40 88 - free - (44K) 128 4194304 1 freebsd-swap (2.0G) 4194432 35152461656 2 freebsd-zfs (16T) => 40 35156656048 da16 GPT (16T) 40 88 - free - (44K) 128 4194304 1 freebsd-swap (2.0G) 4194432 35152461656 2 freebsd-zfs (16T) => 40 35156656048 da22 GPT (16T) 40 88 - free - (44K) 128 4194304 1 freebsd-swap (2.0G) 4194432 35152461656 2 freebsd-zfs (16T) => 40 35156656048 da19 GPT (16T) 40 88 - free - (44K) 128 4194304 1 freebsd-swap (2.0G) 4194432 35152461656 2 freebsd-zfs (16T) => 40 31251759024 da8 GPT (15T) 40 88 - free - (44K) 128 4194304 1 freebsd-swap (2.0G) 4194432 31247564632 2 freebsd-zfs (15T) => 40 35156656048 da0 GPT (16T) 40 88 - free - (44K) 128 4194304 1 freebsd-swap (2.0G) 4194432 35152461656 2 freebsd-zfs (16T) => 40 35156656048 da2 GPT (16T) 40 88 - free - (44K) 128 4194304 1 freebsd-swap (2.0G) 4194432 35152461656 2 freebsd-zfs (16T) => 40 35156656048 da5 GPT (16T) 40 88 - free - (44K) 128 4194304 1 freebsd-swap (2.0G) 4194432 35152461656 2 freebsd-zfs (16T) => 40 35156656048 da20 GPT (16T) 40 88 - free - (44K) 128 4194304 1 freebsd-swap (2.0G) 4194432 35152461656 2 freebsd-zfs (16T) => 40 35156656048 da14 GPT (16T) 40 88 - free - (44K) 128 4194304 1 freebsd-swap (2.0G) 4194432 35152461656 2 freebsd-zfs (16T) => 40 35156656048 da23 GPT (16T) 40 88 - free - (44K) 128 4194304 1 freebsd-swap (2.0G) 4194432 35152461656 2 freebsd-zfs (16T) => 40 35156656048 da11 GPT (16T) 40 88 - free - (44K) 128 4194304 1 freebsd-swap (2.0G) 4194432 35152461656 2 freebsd-zfs (16T) => 40 35156656048 da6 GPT (16T) 40 88 - free - (44K) 128 4194304 1 freebsd-swap (2.0G) 4194432 35152461656 2 freebsd-zfs (16T) => 40 35156656048 da3 GPT (16T) 40 88 - free - (44K) 128 4194304 1 freebsd-swap (2.0G) 4194432 35152461656 2 freebsd-zfs (16T) => 40 35156656048 da12 GPT (16T) 40 88 - free - (44K) 128 4194304 1 freebsd-swap (2.0G) 4194432 35152461656 2 freebsd-zfs (16T) => 40 35156656048 da15 GPT (16T) 40 88 - free - (44K) 128 4194304 1 freebsd-swap (2.0G) 4194432 35152461656 2 freebsd-zfs (16T) => 40 35156656048 da9 GPT (16T) 40 88 - free - (44K) 128 4194304 1 freebsd-swap (2.0G) 4194432 35152461656 2 freebsd-zfs (16T) => 40 35156656048 da18 GPT (16T) 40 88 - free - (44K) 128 4194304 1 freebsd-swap (2.0G) 4194432 35152461656 2 freebsd-zfs (16T) => 40 35156656048 da21 GPT (16T) 40 88 - free - (44K) 128 4194304 1 freebsd-swap (2.0G) 4194432 35152461656 2 freebsd-zfs (16T) => 40 35156656048 da17 GPT (16T) 40 88 - free - (44K) 128 4194304 1 freebsd-swap (2.0G) 4194432 35152461656 2 freebsd-zfs (16T) root@truenas[~]#
-
Hey JorgeB, Thanks for clarifying. Below is the output of the command. NOT SUPPORTED AND WILL RESULT IN UNDEFINED BEHAVIOR AND MAY RESULT IN SYSTEM FAILURE. root@truenas[~]# zpool status -LP pool: bender state: ONLINE scan: resilvered 1.14G in 00:00:14 with 0 errors on Mon Nov 13 12:37:07 2023 config: NAME STATE READ WRITE CKSUM bender ONLINE 00 0 raidz2-0 ONLINE 00 0 /dev/gptid/1c3282f8-a9e2-11ed-8ba9-90e2ba51bb98 ONLINE 00 0 /dev/gptid/a61b64f1-b95c-11ed-b489-90e2ba51bb98 ONLINE 00 0 /dev/gptid/626f9b8b-bbfa-11ed-b489-90e2ba51bb98 ONLINE 00 0 /dev/gptid/7e4a37b3-c3a9-11ed-86ea-90e2ba51bb98 ONLINE 00 0 /dev/gptid/78848cb7-c539-11ed-86ea-90e2ba51bb98 ONLINE 00 0 /dev/gptid/6ef07dfe-ee0a-11ed-aee8-649d99b1c839 ONLINE 00 0 raidz2-1 ONLINE 00 0 /dev/gptid/6a4d6117-0fe8-11ee-b63b-649d99b1c839 ONLINE 00 0 /dev/gptid/15448335-5e3f-11ed-9303-0f1015e0808c ONLINE 00 0 /dev/gptid/15da757a-5e3f-11ed-9303-0f1015e0808c ONLINE 00 0 /dev/gptid/09c559b3-a1e7-11ed-b8d5-90e2ba51bb98 ONLINE 00 0 /dev/gptid/bae999f3-a9d4-11ed-8ba9-90e2ba51bb98 ONLINE 00 0 /dev/gptid/d0c826f7-a771-11ed-b8d5-90e2ba51bb98 ONLINE 00 0 raidz2-2 ONLINE 00 0 /dev/gptid/5741d584-60a0-11ed-802c-39bdfddf3cbf ONLINE 00 0 /dev/gptid/5752effa-60a0-11ed-802c-39bdfddf3cbf ONLINE 00 0 /dev/gptid/f80e6066-c202-11ed-86ea-90e2ba51bb98 ONLINE 00 0 /dev/gptid/575e1866-60a0-11ed-802c-39bdfddf3cbf ONLINE 00 0 /dev/gptid/576f9f57-60a0-11ed-802c-39bdfddf3cbf ONLINE 00 0 /dev/gptid/5766d0e4-60a0-11ed-802c-39bdfddf3cbf ONLINE 00 0 raidz2-3 ONLINE 00 0 /dev/gptid/8dd09fb5-9a05-11ed-bff9-90e2ba51bb98 ONLINE 00 0 /dev/gptid/363fadf4-6618-11ed-babf-ab7eb0fc78df ONLINE 00 0 /dev/gptid/3618c735-6618-11ed-babf-ab7eb0fc78df ONLINE 00 0 /dev/gptid/3634c7d1-6618-11ed-babf-ab7eb0fc78df ONLINE 00 0 /dev/gptid/36220bd6-6618-11ed-babf-ab7eb0fc78df ONLINE 00 0 /dev/gptid/3605a5a4-6618-11ed-babf-ab7eb0fc78df ONLINE 00 0 errors: No known data errors pool: boot-pool state: ONLINE scan: scrub repaired 0B in 00:00:01 with 0 errors on Tue Nov 7 03:45:01 2023
-
Hi All, I currently use Unraid with an archival array of drives and I run TrueNAS as a VM on Unraid in order to use ZFS. The TrueNAS pool is made up of 4 vdevs of 6 drives each. From SpaceinvaderOne's video awhile back it wasn't clear whether multi-vdev pool import was supported. I've seen some information on the forums about it but I want to be 100% certain of the process. Could someone shed some light? Ty!
-
Thanks, looks like I have an issue as I never get over 95mb/s regardless of reconstruct write... I'll investigate further
-
Out of interest, what write speeds are you getting to the array?
-
@Pri, your post could not have come at a better time for me. I'm looking to build a similar kind of server and have been given quotes by 45Drives and TrueNAS which are just insane (I was going for quotes because while I've built several PC's and HEDT servers, I've not dabbled in real server hardware and so all the numbers and compatibilities were throwing me off. I'm wondering if I could pick your brain via direct message as I have several questions! (I've sent you a message) With that said, I'm keen to share knowledge too, so for anyone else reading, once I have my new server built (it'll be a few months) I will make a post to share the specs and decisions we made.
-
Just ran into this issue and wanted to chime in. If you're trying to copy a whole folder of files, it seems to treat this as a single size when checking the available cache space and will throw at error. For example, I have a folder that is 700gb to move, full of 15gb files, my share is set to cache 'yes' and 200gb free space. When I drag an drop said folder, it gives the not enough space error because of the total filesize, even though each individual file is only 15gb or smaller. Worth noting that changing the share to cache 'no' will work, but because of the way unraid propagates share changes, it's something I personally can't do as I have scripts processing and files syncing via rclone which end up throwing errors when I do that.
-
Did you ever find a solution for this?
-
It's been so long I don't remember if I submitted a bug report for it. I don't believe I did as I came here to discover whether it was something I was doing wrong, but didn't really get anywhere. Ultimately, it's been working on active-backup and I just run a direct connection to the UNRAID server. 10gbit is fast enough for me now as I run most of my processing in a VM now on Unraid so not much needs to come through the NIC.
-
For anyone stumbling into this now or in the future. the --shrink argument was added to the command. Go read this comment:
-
Just wanted to provide an update here. I ended up being pulled into another project for the last 6 weeks so I've been unable to test the above suggestions, however we fixed the issue by instead passing through a dedicated drive to the VM. This was the ultimate plan anyway, we figured it was easiest to just go that route. Thanks for the help again!
-
Thanks @Squid, I'll apply these changes over the weekend and see how it performs. I read a few other things in the FAQ which could help so I'll try them all. I'll report back when I have more.
-
Heya, I have a windows VM I use for processing high resolution images. I've been running some tests with a mixture of Cache (nvme), Array (spinning disks) and Vdisk's - both ones stored on nvme drives and stored on traditional hdd's - and I'm a little confused by the results: What are these tests doing? Without getting too into it, we're essentially taking 90, 400mb files and combining them into one 14gb file with a fair bit of CPU and GPU processing of various sorts in between - hence the large amount of RAM, 16GB GPU and high end CPU. Each time the process runs it uses around ~64gb of RAM and ~12GB of GPU VRAM, that just indicates the primary driver of the time difference is definitely the read/write. R/ = read from W/ = write to ===== VM Specs: 128gb ram | 5950x 20 threads | 6800xt ===== 1 - R/vdsk-Cache - W/vdsk-Cache - 4:30 per frame 2 - R/vdsk-Array - W/vdsk-Array - 9:00 per frame 3 - R/vdsk-Array - W/share-Cache - 10:30 per frame 4 - R/share-Cache - W/share-Cache - 8:45 per frame 5 - R/share-Array - W/share-Cache - 14:00 per frame 6 - R/share-Array - W/vdsk-Cache - 12:10 per frame Explaining the above a little further: The optimal hardware arrangement seems to be (line 1); to read from, and write to, a VDISK located on the Cache pool. This results in a time of 4min 30 seconds. However, because VDISKS occupy their allocated space fully, this is not feasible as I would need a VDISK of approximately 12TB on NVME drives which would be quite costly. Line 2 is the same setup but the VDISK is stored on the Array (spinning HDDs). This takes twice as long to complete, not bad, but it still requires a VDISK to permanently fill a significant portion of one of the HDDs in the Array. Line 3 is where things gets confusing. By changing the output directory to the a share located on the Cache pool, I would expect the output time to improve, since the Cache should be significantly faster even with the emulated network adapter. Lines 4-6 are further tests I did but these either are non-optimal settings, or produced slower results than other options which are more optimal, so they are just here for thoroughness. -------------- Does anyone have insight as to why it might be slowing down in line 3 vs line 2? What is it about copying to a cache pool share that causes it to be so much slower than a VDISK on spinning disks? Any insight is appreciated!
-
Couldn't remember as it's been so long but I just tried with the array stopped right now and still no dice. No matter what bonding mode I set it to, once applied it goes back to active-backup.
-
Oh Thanks guys, @trurl you give a good argument there for setting Docker files to cache-only. I don't think bypassing the share for a bit of performance is something I need though, thankfully!
-
No it's not, I've set everything in the power settings to maximum performance and double checked it wasn't going to sleep. I've also noticed that the suspension is immediate once the RDP session is closed, which seems very strange.
-
Hey All, I use a windows 10 VM for processing tasks (rendering, stitching, etc). I connect via remote desktop to check on processing and setup any new tasks, then I'll close RDP and come back every few hours. It's been working fine like this for months until a few weeks ago. Now, anytime I close the session, the entire vm seems to be suspended until I next connect. The only exception to this is a photoshop script I run, this seems to continue fine. However, a custom command line script and a software called PTGUI (360 image stitching software) both get suspended. I'm running Unraid Version 6.9.1 Stable These are my main VM settings. I haven't changed anything here in awhile. Does anyone what could be causing this issue or what I could try to fix it?
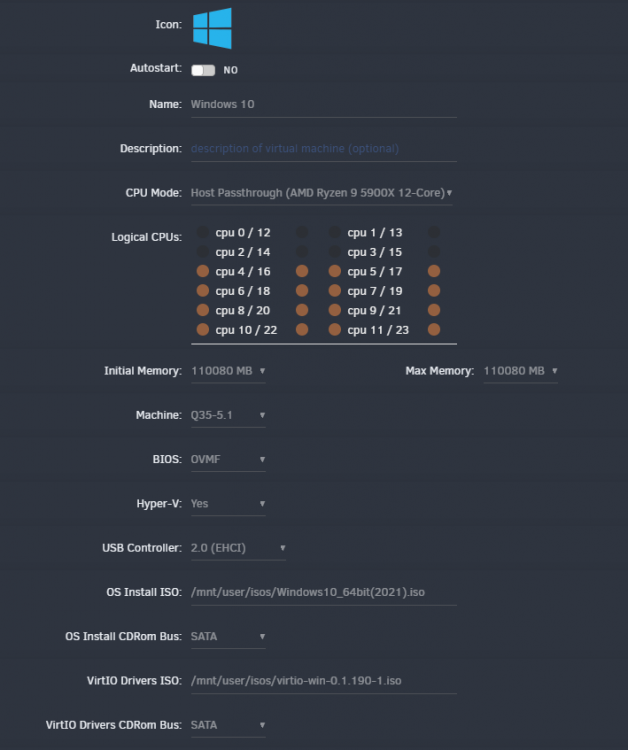
-
Interesting... do you know if anyone has tested this performance difference or if there's any unraid documentation on it?

