




MikaelTarquin
Members
-
Joined
-
Last visited
-
Just want to say thank you so much for this post. I was pulling my hair out trying to figure out how to get `pigz` on my Unraid server to work, this saved my evening.
-
I have a decent number of scripts at this point, but a handful I'd really like a way to access from the Dashboard instead of going to Settings -> User Scripts -> digging through my list. Is it possible to pin certain scripts to the Dashboard in any way?
-
Not really, my solution was installing deluge instead of qbittorrent.
-
Thanks Jorge, that let me stop the mover from the CLI. I started the Mover again and that seems to be running properly now, the SSD cache pool is seeing about 100 MB/s of read and the array is busy writing. I'm guessing I just have to wait until the SSD cache pool finishes before the HDD cache pool will start? There's not a way to swap the order there, is there?
-
General info: 2 pools, cache and cache_hdd - cache is comprised of 2 mirrored 2 TB SSDs - cache_hdd is comprised of a single 8 TB HDD Most shares are set to use cache as primary One share (named 'data') set to use cache_hdd as primary I'm currently experiencing an issue where Mover seems to not be moving anything off my cache pool. I haven't checked it rigorously, but I think Mover has been running for several days now without break. However, at various times I've checked the Main tab and saw the array mostly spun down, very little activity going on, and the free space on cache_hdd gradually ticking down towards 0. Separately, I noticed the other day that all of my docker containers had vanished from the Dashboard and Docker tabs, replaced by generic LIME icons and no details listed. The containers themselves were still running and I could still access their WebUIs directly. I stopped the Docker service and when I started it up again, they all disappeared. I had to use the Previous Apps function within Apps to reinstall everything, which was a bit annoying but overall not the worst thing. I'm wondering if these could be related? Maybe my flash drive is going bad? cache_hdd is a new addition to my setup, so maybe something got misconfigured there? I feel kinda stuck, and with the Mover and Stop Array buttons greyed out, and with the CLI command 'mover stop' not seeming to do anything, hopefully someone here can help. nnc-diagnostics-20241126-0910.zip
-
Never mind! Was able to fix it by using the following docker compose: version: '3.3' services: openbooks: container_name: OpenBooks image: evanbuss/openbooks:latest ports: - "8585:80" volumes: - '/mnt/user/data/media/eBooks/to_import:/books' command: --name my_irc_name --persist --no-browser-downloads restart: unless-stopped environment: - BASE_PATH=/openbooks/ user: "99:100" volumes: booksVolume:
-
I'm not very experienced with manually adding docker containers via compose, so forgive me if this is the wrong place to ask. I was able to successfully add openbooks to my Unraid server via docker compose, but for some reason all the files it downloads come in with r-- read only permissions. I naively tried adding the PUID=99, PGID=100, and UMASK=002 lines to the environment section, thinking that might help, but no luck. Is what I am trying to do not possible? version: '3.3' services: openbooks: ports: - '8585:80' volumes: - '/mnt/user/data/downloads:/books' restart: unless-stopped container_name: OpenBooks command: --name <username> --persist environment: - BASE_PATH=/openbooks/ - PUID=99 - PGID=100 - UMASK=002 image: evanbuss/openbooks:latest volumes: booksVolume:
-
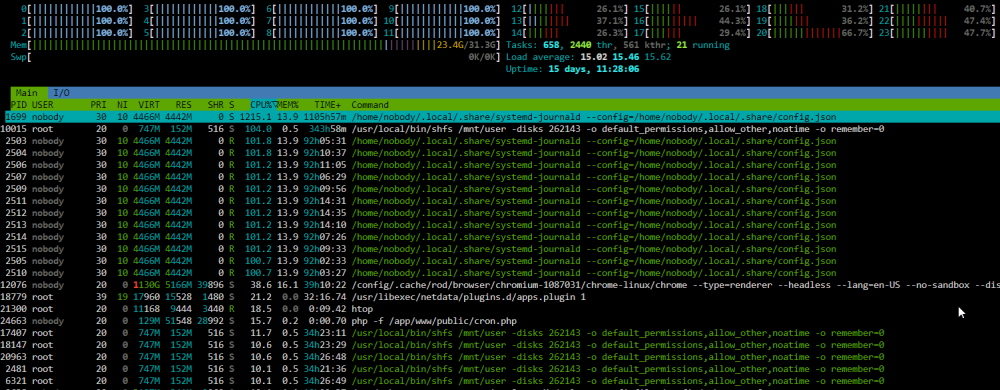
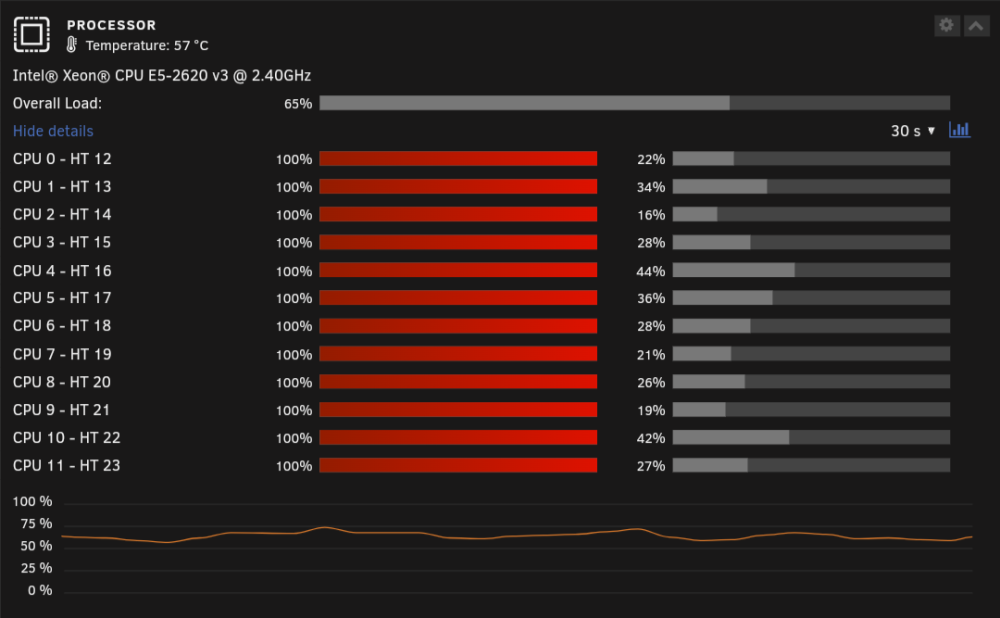
Thank you for the tip. I am not sure what these config.json files are, but they seem to be the cause of the 100% usage on those cores. Edit: I went through each docker container one by one and found that when I stopped qbittorrent (BINHEX - QBITTORRENTVPN), the CPU usage went back to normal. I'll have to keep an eye on that one I suppose.
-
Recently, half of my server's cores are showing constant 100% CPU usage, and I don't know what is causing it. Does anyone have any advice? I think it started happening after I replaced my cache SSD, in case that is relevant. nnc-diagnostics-20231207-0007.zip
-
How did you fix the issue? I've been trying to get Calibre-Web OPDS to work with my Kindle+KOReader over my reverse proxy, but so far have only had luck locally. Everything I try just results in KOReader saying "Authentication required for catalog. Please add a username and password."
-
I'm not sure why it's going so slowly. When I initially added them to the array and it did what I assume was a clear operation, it hummed along at something like 180 MB/sec average (220 at first, and slower as it got to the other side of the disks). I am using the array, which I'm sure doesn't help, but normally parity checks still happen at about 90 MB/sec for me on average (about 3-4 days) Not sure why it's going less than half that now.
-
So, is it not possible to stop the rebuild and add them without rebuilding again? I guess I don't really understand what the data rebuild could be doing to the new empty drives that's so important.
-
So, I am currently adding 2x 18TB drives to my array, which would be disks 16 and 17. It's been a while but I thought all I had to do was stop the array, add those 2 as additional drives, and start the array to let Unraid do everything. After about a day, things finished by the array showed the 2 new drives as unmountable. I stopped the array again, attempted to remove them, format them xfs like the rest of the array via unassigned devices, and then add them back before starting again. I did several things, so I may be misremembering the exact sequence, but the end result is they now in the array as emulated disks 16 and 17 (I have 2x parity drives, so I wonder what would have happened if I tried 3 at once), and the only option that looked like it would help is Data Rebuild. I kicked that off about 12 hours ago now, and it's 6% complete and averaging anywhere from 5 to 50 MB/s. I assume it's just going to spend the next week or two rebuilding "nothing", at the cost of reading through the entirety of every other drive in the array. Do I really need to just let it go through this Data Rebuild and put all that wear on everything? Or is this likely to fail as well? Is there anything I can do to stop it and add them faster? I assume with those 2 showing emulated, the rest of the array is now unprotected? nnc-diagnostics-20230807-0956.zip
-
Did you upgrade the nextcloud version inside the web UI before upgrading the docker? I finally got mine working again last night and pinned the docker to release 27 so that it doesn't break again. This page helped me a lot: https://info.linuxserver.io/issues/2023-06-25-nextcloud/
-
All I've been able to find so far is some fairly unhelpful discussion about Security Headers, which I think by uncommenting the lines in the SSL configuration file, I've already done. Swag, duckdns, and namecheap are the only common threads I can think of. Bummer.



