




Hairy
Members
-
Joined
-
Last visited
Everything posted by Hairy
-
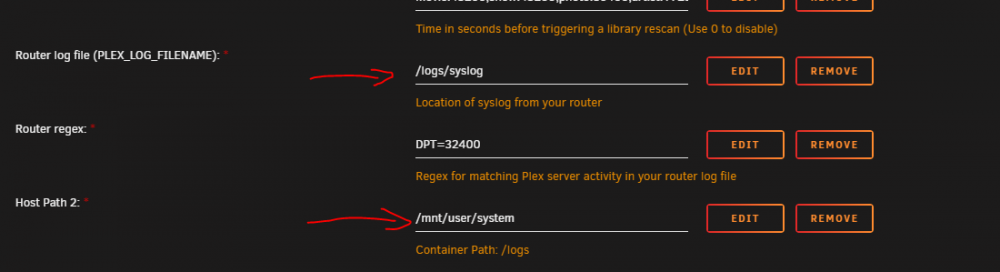
Hello Tried to use your setup to automagical start and stop the powerhungry server, but I have some problems setting it up My environment: - Powerhungry PlexServer on Unraid with running Plex in a docker container - Power effeciency miniServer on Unraid with your docker container - Router: Synology RT Router with syslog forwarded to the miniServer (will be saved under /mnt/user/syslogs/syslog-IPADDRESS.log ) I have some confusion with the default xml, as there is the log path mentioned twice and even then only the folder and not the direct .log filepath? As you can see in the PLEX_LOG_FILENAME is asking for the router logs (in my case for /mnt/user/syslogs/syslog-IPADDRESS.log?), but is this the in-container path the script is checking for a log, or what does the variable do ? In addition, what is then the "Host path 2", as this one is not really described in the github. Is this then the in-container logs path which is checking for the router logs? If yes, why is the default then the system share? I tried a lot of possible combinations out, but nothing seems to work. The closest I got without auto stopping the container was to the following error message: PLAY [all] ********************************************************************* TASK [Gathering Facts] ********************************************************* fatal: [PLEX_HOST_IP]: FAILED! => {"ansible_facts": {}, "changed": false, "failed_modules": {"setup": {"ansible_facts": {"discovered_interpreter_python": "/usr/bin/python"}, "failed": true, "module_stderr": "Shared connection to PLEX_HOST_IP closed.\r\n", "module_stdout": "ERROR:root:code for hash md5 was not found.\r\nTraceback (most recent call last):\r\n File \"/usr/lib64/python2.7/hashlib.py\", line 147, in <module>\r\n globals()[__func_name] = __get_hash(__func_name)\r\n File \"/usr/lib64/python2.7/hashlib.py\", line 97, in __get_builtin_constructor\r\n raise ValueError('unsupported hash type ' + name)\r\nValueError: unsupported hash type md5\r\nERROR:root:code for hash sha1 was not found.\r\nTraceback (most recent call last):\r\n File \"/usr/lib64/python2.7/hashlib.py\", line 147, in <module>\r\n globals()[__func_name] = __get_hash(__func_name)\r\n File \"/usr/lib64/python2.7/hashlib.py\", line 97, in __get_builtin_constructor\r\n raise ValueError('unsupported hash type ' + name)\r\nValueError: unsupported hash type sha1\r\nERROR:root:code for hash sha224 was not found.\r\nTraceback (most recent call last):\r\n File \"/usr/lib64/python2.7/hashlib.py\", line 147, in <module>\r\n globals()[__func_name] = __get_hash(__func_name)\r\n File \"/usr/lib64/python2.7/hashlib.py\", line 97, in __get_builtin_constructor\r\n raise ValueError('unsupported hash type ' + name)\r\nValueError: unsupported hash type sha224\r\nERROR:root:code for hash sha256 was not found.\r\nTraceback (most recent call last):\r\n File \"/usr/lib64/python2.7/hashlib.py\", line 147, in <module>\r\n globals()[__func_name] = __get_hash(__func_name)\r\n File \"/usr/lib64/python2.7/hashlib.py\", line 97, in __get_builtin_constructor\r\n raise ValueError('unsupported hash type ' + name)\r\nValueError: unsupported hash type sha256\r\nERROR:root:code for hash sha384 was not found.\r\nTraceback (most recent call last):\r\n File \"/usr/lib64/python2.7/hashlib.py\", line 147, in <module>\r\n globals()[__func_name] = __get_hash(__func_name)\r\n File \"/usr/lib64/python2.7/hashlib.py\", line 97, in __get_builtin_constructor\r\n raise ValueError('unsupported hash type ' + name)\r\nValueError: unsupported hash type sha384\r\nERROR:root:code for hash sha512 was not found.\r\nTraceback (most recent call last):\r\n File \"/usr/lib64/python2.7/hashlib.py\", line 147, in <module>\r\n globals()[__func_name] = __get_hash(__func_name)\r\n File \"/usr/lib64/python2.7/hashlib.py\", line 97, in __get_builtin_constructor\r\n raise ValueError('unsupported hash type ' + name)\r\nValueError: unsupported hash type sha512\r\nTraceback (most recent call last):\r\n File \"/root/.ansible/tmp/ansible-tmp-1644598320.2319295-72292159337465/AnsiballZ_setup.py\", line 102, in <module>\r\n _ansiballz_main()\r\n File \"/root/.ansible/tmp/ansible-tmp-1644598320.2319295-72292159337465/AnsiballZ_setup.py\", line 94, in _ansiballz_main\r\n invoke_module(zipped_mod, temp_path, ANSIBALLZ_PARAMS)\r\n File \"/root/.ansible/tmp/ansible-tmp-1644598320.2319295-72292159337465/AnsiballZ_setup.py\", line 37, in invoke_module\r\n from ansible.module_utils import basic\r\n File \"/tmp/ansible_setup_payload_hpw4Eo/ansible_setup_payload.zip/ansible/module_utils/basic.py\", line 124, in <module>\r\n File \"/usr/lib64/python2.7/sha.py\", line 10, in <module>\r\n from hashlib import sha1 as sha\r\nImportError: cannot import name sha1\r\n", "msg": "MODULE FAILURE\nSee stdout/stderr for the exact error", "rc": 1, "warnings": ["Platform linux on host PLEX_HOST_IP is using the discovered Python interpreter at /usr/bin/python, but future installation of another Python interpreter could change this. See https://docs.ansible.com/ansible/2.9/reference_appendices/interpreter_discovery.html for more information."]}}, "msg": "The following modules failed to execute: setup\n"} PLAY RECAP ********************************************************************* Python 2.7 and 3.9 is installed with the nerdpack on the plexServer and I tried it with and without root user (and clearing the appdata folder everytime). Seems to be some kind of issue with the server? The X-Plex-Token is extracted directly from the local plexServer as described in your link., but I also tried the https://app.plex.tv/desktop/#!/ variant (as that was a different token) Anything else I am missing or mixing up? Will upload the santized logs on debug level also : wakerup_logs.log Thank you and wish you a great further day
-
Ah got it, so it's not considering if the attached drives are SSD or HDD. Oke, then the question which would be left is, is there a hot spare functionality without scripting it myself ?
-
Hello I have searched some information about that topic, but I am not 100% certain if this is even possible in Unraid and if there would be a benefit even. Is there a way, to set a RAID1 TWO SSDs and one HDD of the same size? And in addition, would there be a benefit of the speed of the SSD (be it only on the reading part) or is the speed determined by the general slowest device, in this case the HDD? I read that some hardware RAID1 can be "smart" enought so that they primarly use the SSD RAID1 at first especial with the reading part, this seems to be called "write first", but is that method also implemented in the software RAID1 wich Unraid is using? I know, it sounds a little ridiculous, but I am on to installing a Cache in my Unraid server, but I still don't trust consumer SSD's with 24/7 useage and my idea would be, to be on the safe side, that the HDD is like a "Backup/failsafe" of that. My goal would be, that the 12 "big disks" are only being used if needed, and Docker/VMs should be stored soley on the SSD's and on that small HDD. Maybe the HDD as "hot spare" is also enough? So that if an SSD is going to die, that THEN the HDD will be utilized as failsafe, or am I too overthinking/scared of an failure ? The question then would be, is there an automatic hot spare function? I thought I read it somewhere a year ago, but I cant find anything about it anymore besides that post: Would be interested what your thoughts are about that, or if it's completly nonesense what I am talking about.
-
Uninstalled corefreq and no random reboots for days, seems that this was the cause...I guess?
-
Hello I got some random Kernel panics on my old machine, and it seems to be related either to [corefreqk] or my GPU? Will attach the syslogs (or a trimmed version of that, I am not 100% certain if the whole syslog is not containing any privacy information , still a Unix newbie ). My assumption for corefreq is the mentioned [corefreqk] in the stacktrace, but it could also be the GPU which is doing folding@home and Plex in Docker container and that one is the newest add to the hardware and the issue started up then. What is weird, is that one core is 100% always busy when f@h is beeing run (that is not the weird part), but the "busy core" itself is jumping around, maybe an indirect cause for corefreq to crash? iLO is not showing any issues, errors or botched up NMI, so for now I would assume it's not an hardware error, but of course maybe it's only not a visible one. Uninstalled the plugin for now, to be sure, but testing will take some days. So the question would be for now: Did I read the trace correctly? If no, where to start to look at? And if it's the corefreq, how to get in touch with the maintainer? Maybe other people with a similar hardware will have the same issue. Or maybe at least that he can shout at me that I am the fault and not his program , jk . Installed is corefreq v2021.07.13 The machine is a - HP ProLiant DL380p gen8 - Dual Intel Xeon CPU E5-2630L v2 - 80 GB RAM (4 and 8 GB mixed) - HP Ethernet 10Gb 2-port 530 FLR-SFP+ Adapter - Smart Array P420i Controller (HBA mode, SATA and SAS HDD's mixed) - NVIDIA Quadro P620 Thank you and wish you all a nice day. syslog-cut.txt unraid-diagnostics-20211101-1430.zip
-
Really looking forward to this as a plugin (if you will ever make one) I mainly have HDD's and had to fill them nearly full (95% and more) as new disks are expensive now with corona and the fragmentation is rather high and can "feel" already the performance drain of it. Thank you for your time into looking stuff like this and making it available for non linux pro's

