




Iker
Community Developer
-
Joined
-
Last visited
Everything posted by Iker
-
Thanks for the report, I'll be fixing this and reviewing other issues that come up with the style changes on Unraid 7.1.X next week.
-
Not right now, but, I'll keep in mind for a new set of features to be included in a new release (soon).
-
Can you please clarify what you are trying to achieve?, Because for releasing a snapshot, first you need to create a hold on it.
-
Hi @ggee 1. You can, but not from the UI, this is something I have been thinking on implementing as an additional option for the pool. 2. Yes, there is a little check on the "Take Snapshot" dialog for recursive operation.
-
@john_smith To activate the "Convert to Dataset" option, you need to enable "Destructive Mode" on the plugin options; I'll probably move it directly to the main UI to make it more intuitive. @d3m3zs Someone asked me for the same feature not so long ago, and I tried to include it in the latest release, but it's a little bit problematic for compatibility with other features, such as Lazy Load; however, I'll take another look and see what I can do.
-
Hi John, I have the impression that you created a folder instead of a dataset, and that's the reason you can only perform a limited set of actions.
-
You can ask the maintainer to update it to the latest version. What the plugin does is to provide the binary and daemonize it, so it can work on the background executing the backup plans. ZnapZend doesn't have a GUI or any other interface besides the CLI tool natively. My intention is to provide "some" GUI for defining and reviewing backup plans, then, the demon should execute on the defined schedules.
-
Hi @d3m3zs I'm a little bit reluctant to include ZnapZend binaries in the plugin, mainly because there is already a ZnapZend plugin on the CA, and you can also install it using docker(Probably I will submit a docker template for that in the future). My idea is to start working in the upcoming weeks on the feature for creating backup plans from the GUI (As today you can only read them) so you can create and review the backup plans using ZFS Master, but the ZnapZend docker or CA plugin executes them.
-
Hi @aglyons I just added a specific section in the first post of this thread to clarify how used/free space is calculate and why there are some discrepancies. For your particular case @novaleaf, and as you are already using Unraid 7, you can check the the following post for using the overlay2 driver and get rid of the legacy datasets completely, that change alone speeds up the zfs listing operations quite a bit.
-
Short answer: You need to escape the "-" in your pattern so that it will be "/docker%-old/.*". Long Answer: The plugin doesn't use regex, but Lua patterns, which are slightly different (https://www.lua.org/pil/20.2.html).
-
Hi @googleg it's not. Can you please share your plugins settings, just to check that everything is configured as it should.
-
Hi @foo_fighter, unfortunately, no.
-
@UnraidTobias Can you please specify what I'm supposed to fix from that thread?
-
Yes, however, you can also use the dataset name as long as it's unique, for example: "/dockerfiles/.*"
-
Please check the options for loading information in the plugin setting, as you can load it on demand instead of using a fixed schedule. I have tried reproducing the issue in the latest version and 7 rc1, but I haven't found the proper cause yet; but, as a note, the situation you describe sounds like you have thousands of snapshots or you haven't excluded dockerfiles from the listing process.
-
It's not in my plans to develop that functionality within the plugin; however, the integration with ZnapZend works just fine and lets you see the plans defined for each dataset, so please check out the plugin or the docker container available. In the future, you will also be able to create plans, but the tool (at least for now) will be ZnapZend.
-
There is a new update with the following changelog: 2024.12.08 Add - Config for pulling ZnapZend plans Fix - Refresh and settings icon Fix - Corner case if no information is loaded By default, ZnapZend integration is not active; this should fix some performance issues reported; if you still encounter issues even with the integration disabled, please report the problems in this thread.
-
Yeah, I get it, but that particular functionality was tested pretty thoroughly even more; it was designed specifically for that use case, so it seems very weird that it resurfaces again as a problem; in your case, the "Last refresh at" got updated? If not, the plugin didn't touch the disks, and it was probably something else.
-
I'm still investigating this, as it's difficult to reproduce and apparently only happens with some specific configurations; however, I'll publish an update today with a possible fix. It's not required; the configuration is dynamic and updated every 30 seconds.
-
@drmetro Can you please reproduce the issue and provide a screenshot executing "top" in a terminal? I will follow up with a couple of questions via PM to check if anything particular in your pool may cause the issue.
-
Yes, these are the simple steps: Stop any VM/docker that may be using the folder. Make sure that you enable "destructive mode" on Settings->User Utilities-> ZFS Master. Return to the main tab, and over the actions menu for the dataset, click on "Add directory Listing". Then you should be able to see every directory under the dataset (with a different icon); hit the actions button and click over "Convert to dataset" If everything goes well, delete the original directory. And that's it; please keep in mind that you need at least the same amount of free space as the directory size and the following remarks for the process:
-
I'm not so sure that I follow exactly what your issue is, from the other thread: The plugin doesn't have a lot to do with phantom mounts (It doesn't mount anything, just provides a GUI for ZFS), those are going to exists with or without the plugin, and the shares page is also completely independent; if those are the issues that you are facing, they are directly related to the pool.
-
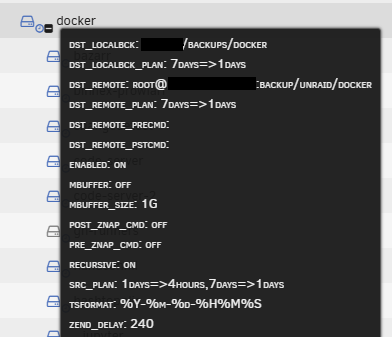
There is a new update with the following changelog: 2024.11.17 Add - ZnapZend plans information The ZnapZend integration is very straightforward; if you have created any ZanpZend backup plan for your datasets, ZFS Master will detect those and show the information in the UI under a clock icon next to the dataset name, an example in the image below. In my testing, polling the information didn't affect my dataset information loading times; however, please let me know if you find any problems, slow down, or have any issues.
-
That was part of a rework on the dialogs to "informational messages.", The spaceinvader's video is one year old, and some things have changed; for example, you can convert a folder to a dataset directly using the plugin.
-
Hi @diehard2k9, your question seems best suited for the General Support forum





