

5252525111
-
Posts
48 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by 5252525111
-
-
On 10/11/2022 at 7:38 PM, NonDescriptPerson said:
{"statusCode":404,"message":"ENOENT: no such file or directory, stat '/ghostfolio/apps/client/index.html'"}
You need to create a new variable in your configuration, click `add another path, port, variable, label or device` and choose `variable` set key to `NODE_ENV` and value to `production` and it should work after that.
-
Change setting under 'Settings > Global Shares Settings' look for Tunable (support Hard Links): and set it to No.
-
On 9/26/2021 at 1:11 AM, Shonky said:
How's your fix holding up? I get this sporadically. certainly not every 3-4 days. 1-3 months perhaps.
So far it's holding up well. I'm having new issues with NFS but don't think that's related to this at all. Long story short, no more panics.
On 9/26/2021 at 1:11 AM, Shonky said:Is the suggested fix to have docker restricted to a sub range of the full /24 and then for each docker that needs it, only use IPs within that range?
That was one of the main fixes for me. I used a range outside my DHCP and reserve that for containers on unraid. If I recall correctly since I currently don't have access to my system, 100-223 is my LAN range, 50-99 I used for static and 224-255 (192.168.99.224/27) I reserve for containers on unraid.
-
Sadly I use NFS everyday. Will see if I can find an alternative for my other devices. I'll look into what limetech suggested and set "Settings/NFS/Tunable (fuse remember)" to 0.
-
-
noticed this. Not sure what would cause this to happen.
d????????? ? ? ? ? ? user/ drwxrwxrwx 1 nobody users 71 Oct 6 16:15 user0/
-
I've attached my logs in hopes someone can help.
30 days is the most I've ever managed to get unraid to not crash. But the past couple days I've gone back to daily crashes. This time it seems to crash my shares and containers but the gui is still responsive. After a reboot everything is fine again. No hardware changes or new software I can think of.
From my limited understanding, the logs are saying the docker network crashed?
Any advise is much appreciated.
EDIT: Updated title from "6.9.2 I've been running stable for 30days and now daily crashes." to "6.9.2 30 days stable, suddenly unraid unmounts /mnt/user"
-
Followed the drive. Swapped it out and seems to be good now.
Thanks for the help!!! Much appreciated.
-
-
Just started copying everting back to the pool already have this
Tatooine:~# btrfs dev stats /mnt/app_cache/ [/dev/nvme0n1p1].write_io_errs 129163 [/dev/nvme0n1p1].read_io_errs 0 [/dev/nvme0n1p1].flush_io_errs 3 [/dev/nvme0n1p1].corruption_errs 0 [/dev/nvme0n1p1].generation_errs 0 [/dev/nvme1n1p1].write_io_errs 0 [/dev/nvme1n1p1].read_io_errs 0 [/dev/nvme1n1p1].flush_io_errs 0 [/dev/nvme1n1p1].corruption_errs 0 [/dev/nvme1n1p1].generation_errs 0
I take it, it could be a failing drive. Specifically `nvme0n1p1`?
-
Thanks @JorgeB.
I put `nvme_core.default_ps_max_latency_us=0` in and decided I may as well do a BIOS update. The cache pool was still read only, but I've back everything up and will be formatting the drives. Hopefully it won't occur again.
-
ran the btrfs stats. seems like both have numbers there.
Tatooine:~# btrfs dev stats /mnt/app_cache/ [/dev/nvme0n1p1].write_io_errs 2350795 [/dev/nvme0n1p1].read_io_errs 953269 [/dev/nvme0n1p1].flush_io_errs 74132 [/dev/nvme0n1p1].corruption_errs 9861 [/dev/nvme0n1p1].generation_errs 0 [/dev/nvme1n1p1].write_io_errs 0 [/dev/nvme1n1p1].read_io_errs 0 [/dev/nvme1n1p1].flush_io_errs 0 [/dev/nvme1n1p1].corruption_errs 239 [/dev/nvme1n1p1].generation_errs 0
Is this a btrfs issue or M.2 issue? should i be looking to replace my NVMEs?
-
Woke up this morning to hundreds of warnings and emails that "Cache pool BTRFS missing device"
Decided to restart unraid and now my pool is read only but the drive is there. Going to try copying everything off the cache to the array and format the drives in the pool. Not the first time my btrfs goes to read only, getting frustrated by it.
1. Is what I'm planning to do alright?
2. is there anything I can do to prevent this from happening again?
3. Could someone help me try and figure out what happened?
attached is the diagnostics before the restart
tatooine-diagnostics-20210510-0630.zip
-
2 hours ago, boomam said:
Anyone else getting "/.well-known/webfinger" & "/.well-known/nodeinfo" with 21.0.0
I believe you need to add the following to your nginx config
# Make a regex exception for `/.well-known` so that clients can still # access it despite the existence of the regex rule # `location ~ /(\.|autotest|...)` which would otherwise handle requests # for `/.well-known`. location ^~ /.well-known { # The following 6 rules are borrowed from `.htaccess` location = /.well-known/carddav { return 301 /remote.php/dav/; } location = /.well-known/caldav { return 301 /remote.php/dav/; } # Anything else is dynamically handled by Nextcloud location ^~ /.well-known { return 301 /index.php$uri; } try_files $uri $uri/ =404; }
See documentation https://docs.nextcloud.com/server/21/admin_manual/installation/nginx.html and also https://docs.nextcloud.com/server/21/admin_manual/issues/general_troubleshooting.html#service-discovery -
tatooine-diagnostics-20210220-2045.zip
Seemed to happen after I tried to remove a container that wouldn't start (tdarr_aio). Shorty after my containers were stopping and I would get an error when I try to start or manage any of them.
This is the error I see.
`Error: open /var/lib/docker/image/btrfs/.tmp-repositories.json262781941: read-only file system`
Not sure what to do, any help is much appreciated.
-
On 2/4/2021 at 8:54 AM, tasmith88 said:
@Josh.5 Seems like i'm not the only one having this issue. Any way to figure this out and resolve?
started happening to me today as well. Have to turn it off for the time being.
-
Every time I search this issue, I come right back to this post. I MAY have found the solution and hope it may help someone else.
I'll preface this first. I've been having this issue for months. On average I would crash 3-4 days, and once I made it to 5 only to be let down again. At time of writing this it marks my 10th day stable, which is no major milestone but looks promising. I made a few changes at once and I'm not sure which one fixed it so I'll write them all down.
- I noticed we had the same switch, the Mikrotik CRS312-4C+8XG-RM. My first change was here, under the link tab I disabled (unchecked) all "Flow Control Tx/Rx" from unraid ports. I don't know why this was enabled by default but unless you need it, disable it.
-
In unraid I made changes to my network settings. The `nf_nat_setup_info` issue when doing research is network related. after digging in non unraid specific issues it seems to be a wide range of things.
-
Settings> Network Settings
- My main network in unraid was let mostly unchanged. I assigned a static IP in unraid, matching the static mapping on my router. If you have VLans on your main network it seems that unraid broadcasts the vlans with the same mac and can cause confusion for your router.
-
I set all vlans on this network to not get auto assigned IP. Note, if you are using bridge network on this vlan you'll have to have an ip.
I followed a guide to set this up. https://staging.forums.unraid.net/topic/62107-network-isolation-in-unraid-64/?ct=1612387651
-
Settings > Docker
- This is the one I truly believe may have fixed the issue. One of the issues I've read is that the docker service assigns an ip address to containers that are in use by something else on your network.... or something along those lines. So you should be setting a range that your router doesn't use and have your docker service run in that range. To do this set enable docker to no and apply change. Once your containers are turned off make sure you're in advanced view. You'll see check boxes for custom network. for each of those enabled you'll want to set a DHCP range. So lets say on your router you isolate 192.168.1.128 to 192.168.1.159 which is br0 you can write the CIDR as 192.168.1.128/27 (you can do CIDR transitions at this site https://www.ipaddressguide.com/cidr).
-
Settings> Network Settings
Hopefully those make sense. Figured I'd share, in hopes this is the solution and possibly help someone else out there. If I crash again I'll update this to let other know. If something above is not clear let me know I'll try to clarify. This is mostly new to me.
-
Never figured it out, I ended up buying a used intel card off ebay.
-
restored back to 6.9.0-rc1, seems to be working
 Guess I'll post this in the issues for rc2.
Guess I'll post this in the issues for rc2.
Thanks @Vr2Io
-
Could I do a fresh install while maintaining the configurations?
I managed to get safe mode to boot up long enough to get the diagnostics but it's only for the current boot so probably nothing useful.
-
Just tried safe mode, same error.
-
Hardware
Asus X570 WS Motherboard
AMD 2700x
IBM 45W9122 LSI SAS9201-8i
Solarflare SFN5122F
GTX 560
Unraid Version
6.9.0-rc2
Other issues I've had
I can't access the system to get the logs/diagnostics this time.
Things I've tried
- I've set the bios back to default settings then reapplying everything I need.
- researching efx_farch_ev_process right now
-
I don't know what I'm doing wrong. I've attached a video of it crashing and screenshots of my bios settings.
Am I missing something in the bios? Did I do something wrong? I'm at my wits end with unraid constantly having issues. I've never been stable for more than 7 days. I'm about to give up.
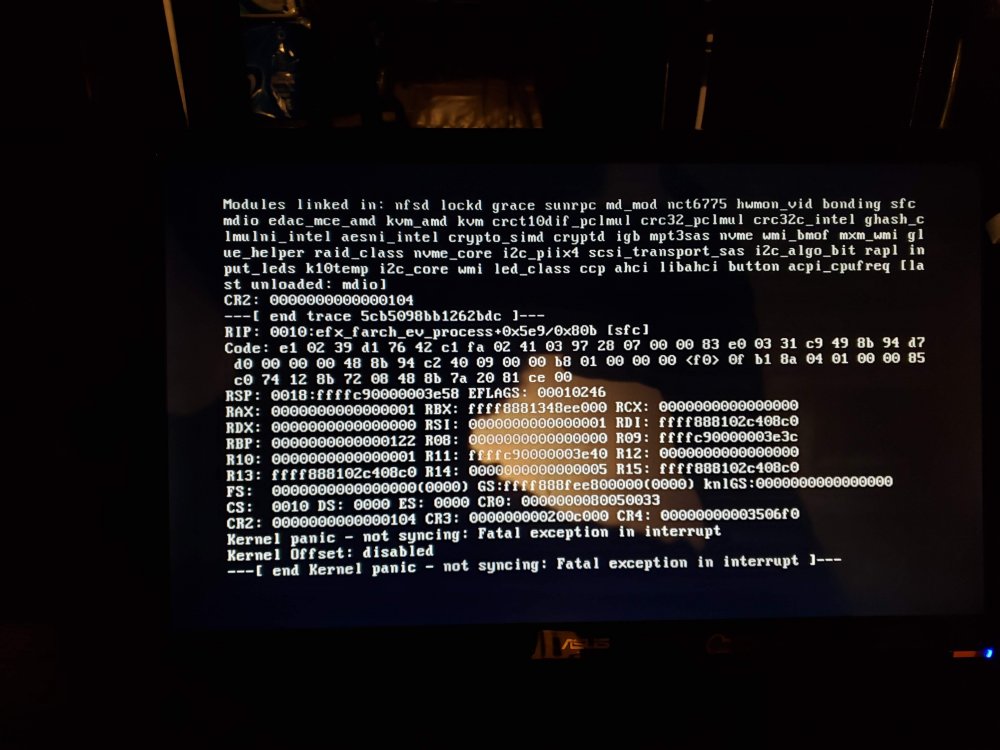
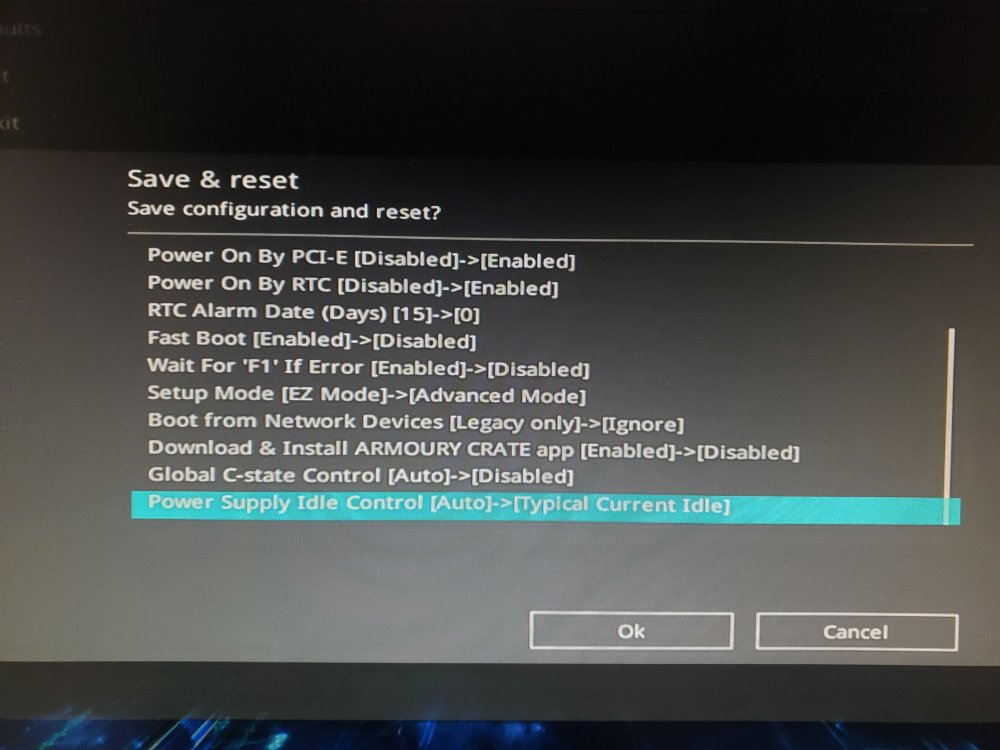

-
Disabled Organizr, I’m 4 days stable now. Seems to be related to



[SUPPORT] ALEXBN71 - CODEPROJECT.AI_SERVER
in Docker Containers
Posted
For those running CP.AI using the gpu docker container. It seems like CP hasn't been building it for about 5 months. What you can do is change it to a cuda container and have the latest version.
Simply update `codeproject/ai-server:gpu` to one of the following depending on your GPUs capabilities.
- `codeproject/ai-server:cuda11_7`
- `codeproject/ai-server:cuda12_2`