




HiSoC8Y
Members
-
Joined
-
Last visited
Everything posted by HiSoC8Y
-
Just an update, I read somewhere that i flash it without the ROM file, and i reflashed my card again without it. Now, I don't get the option for the BIOS of the card when the server boots. But what I did, i connected all the hard drives via the new card and the Intel extender, and my unRAID VM read all the drives as they were before, even the assignment to the slots are correct. Before i put my server into production, i want to be sure that it's ok and nothing is wrong. Update I brought the array up, and all was ok, and i tested spin up and down, and it worked. anything else i should test?
-
This is another screen (after flashing) that shows the card with the firmware version P19 20mb image hosting
-
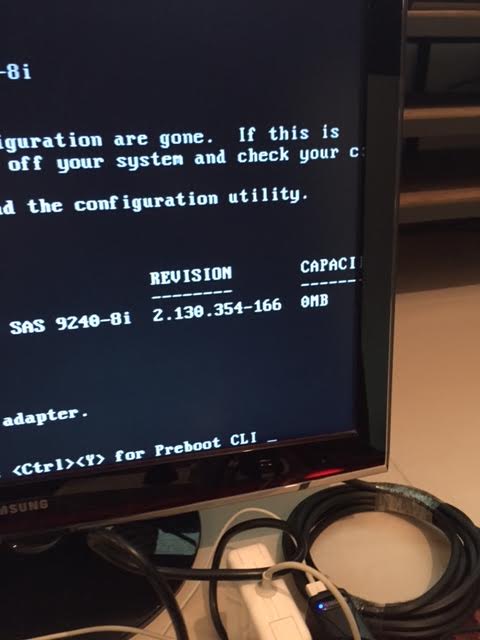
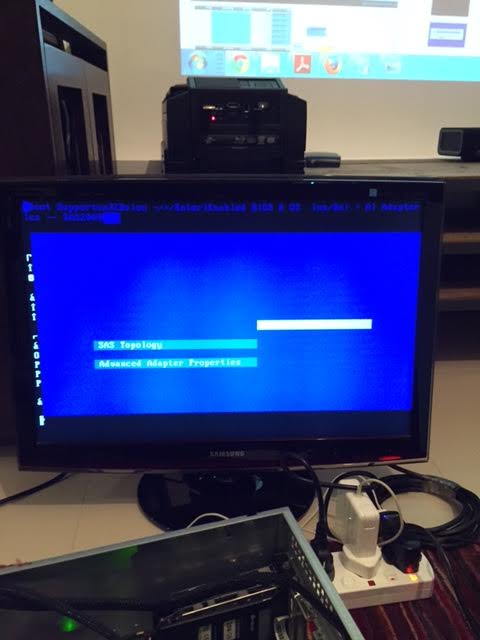
Ok, so i did it, all went good, and attached is my original adapter info i got before flashing. However, now, when i press CNTL-C enter the card settings, i get this weird blue screen (attached) (the black screen attached is the info before flashing the card). the settings page (card BIOS/blue screen) is messed up, and i can't see any settings. i flashed with 9211-8i P19. Right now, only the card is installed, without any HDDs attached. what could be wrong? If so, is there I could go back? ADAPTERS_original.TXT Flashlog1.txt
-
Do i just download the files for P19 from LSI website? I download P19 for the 9211-8i DOS? I'm confused now with many posts and files and guides. Can you please guide me? Which files should i use? Do i need to replace any files with the original P19 files from LSI? is it for 9211-8i? Ok, So I'll try to explain the steps I need to follow (from my understanding), correct me if I'm wrong: 1.) First, I download the zip file included in the first post of this topics, which is related to my card, which is LSI MegaRAID SAS2008 (LSI MegaRAID to SAS2008(P11).zip - 5.87 MB) 2.) I download the latest P19 DOS version files from LSI for 9211-8i. 3.) I replace the the firmware files in step 1. with the files download in step 2 (the firmware files 2118it.bin and sas2flsh.exe). 4.) I follow the guide mentioned in the __READMEFIRST.txt file that is included in the files downloaded in step 1. So now, this will give me an IT mode card of 9211 8i, which can be used with unRAID. Am I correct?
-
It's LSI SAS 9240-8i, it's in the original LSI retail box
-
Hi Fireball, So, I got my new LSI MegaRAID card, which is with SAS2008 (LSI00200). Do I follow your guide or I follow the original guide/first post, which is this If i follow the original post/first post that is specific for the LSI MegaRAID, that one has P11, how can i use it with the P19?
-
Hi I just received my new card, which is a: LSI MegaRAID with SAS2008 chipsets It's in the original LSI retail box. My question, Do I need to flash it to IT mode, or it comes with options in the BIOS (enable/disable)?
-
I'm really getting tired of this M1015. My computer doesnt POST when the card is installed. Update You will find detailed findings of my issue in this thread Ok, here is a detailed pic of my card, front and back. http://lime-technology.com/forum/index.php?topic=22239.0 which package should i use for this?
-
Hi I got the IBM M1015 (sas9220-8i). Which firmware/procedure should I use? Thanks

