




pika
Members
-
Joined
-
Last visited
-
worked for me, too! not sure how to migrate to another container though. maybe someone could explain that in detail? i would not like to crash my paperless setup
-
Hello! I've been running Nextcloud for a while now. For some time now (2 months) Nextcloud becomes unreachable after ~2days (no error in Container logs), CPU goes to 100%. After Container Restart everything works fine again (with CPU at normal level, Nextcloud reachable). any ideas why this would happen? best regards
-
no more problems after reboot. strangest things happen 😅
-
i have rebootet another time (quite desperate...). should i post diagnostics without any container installed or should i install some containers, reboot, diagnostics? edit: i have set them all up, and this time i got them all running. strange thing. what can i do to be sure they won't all disappear on next reboot? in the attachment you can find acutal diagnostics (after re-installing all the containers and no reboot). and another thing that seems strange: when i go to docker > docker size i get a total size of 19.1GB (Container) + 1.43GB (writeable) + 26.3MB (Log), but on the dashboard the Docker vdisk is on 99% (38.8GB / 40.0GB)? datatower-diagnostics-20260504-2136.zip
-
thank you! i got some dockers running again. the most essential dockers don't start/work anymore. nextcloud won't connect to mariaDB MongoDB has a problem with locked file (so the unifi controller won't start). edit: after reboot all docker containers have vanished again...
-
Hello! I wasn't able to update some dockers for some days. when performing an update in the end i got the error "file exists". yesterday i noticed that my nextcloud was offline and all four CPU on 100%. i stopped and restartet docker service. the containers then startet again, CPU again on 100% and nextcloud still down (no errors on logs). after a few minutes the whole docker section on the webUI vanished and on the docker site i got this error: i tried a restart and suddenly everything seemed to work again. CPU on normal levels, dockers showing, nextcloud online. after restart unraid started the parity check - unscheduled. tried to update 2-3 dockers, still got the same error (file exists). one day later i find nextcloud offline again, docker section hidden again and the same error as posted above. strange enough: all dockers seem to work - (don't know why nextcloud not reachable). i can't post the exact update error because i can't start the update process because "Docker Service failed to start" and no containers showing. in the attachment you can find diagnostics. please help 🫠 datatower-diagnostics-20260504-0735.zip
-
in the end my system rebooted after an hour or so... and even generated diagnostics (attached). do you also need the previously generated diagnostics? (~2hours earlier) datatower-diagnostics-20250418-1317.zip
-
it's not rebooting, syslog says: Apr 18 12:57:32 DataTower shutdown[4157149]: shutting down for system reboot Apr 18 12:57:33 DataTower init: Switching to runlevel: 6 Apr 18 12:57:33 DataTower rc.6: Running shutdown script /etc/rc.d/rc.6: Apr 18 12:57:33 DataTower init: Trying to re-exec init Apr 18 12:57:33 DataTower rc.6: Saving system time to the hardware clock (UTC). Apr 18 12:57:33 DataTower rc.6: Creating system time correction file /etc/adjtime. Apr 18 12:57:33 DataTower rc.6: /sbin/hwclock --utc --systohc Apr 18 12:57:35 DataTower rc.local_shutdown: Waiting up to 90 seconds for graceful shutdown... Apr 18 12:57:40 DataTower shfs: share cache full Apr 18 12:57:40 DataTower shfs: share cache full Apr 18 12:57:47 DataTower shfs: share cache full Apr 18 12:58:16 DataTower kernel: mdcmd (38): nocheck cancel Apr 18 12:58:16 DataTower emhttpd: Spinning up all drives... Apr 18 12:58:16 DataTower emhttpd: read SMART /dev/sdd Apr 18 12:58:16 DataTower emhttpd: read SMART /dev/sde Apr 18 12:58:16 DataTower emhttpd: read SMART /dev/sdb Apr 18 12:58:16 DataTower emhttpd: read SMART /dev/sdc Apr 18 12:58:16 DataTower emhttpd: read SMART /dev/nvme0n1 Apr 18 12:58:16 DataTower emhttpd: read SMART /dev/sda Apr 18 12:59:05 DataTower rc.local_shutdown: Forcing shutdown... Apr 18 12:59:05 DataTower rc.local_shutdown: Status of all loop devices Apr 18 12:59:05 DataTower rc.local_shutdown: losetup -a Apr 18 12:59:05 DataTower rc.local_shutdown: Active pids left on /mnt/* Apr 18 12:59:05 DataTower rc.local_shutdown: fuser -mv /mnt/addons /mnt/cache /mnt/disk1 /mnt/disk2 /mnt/disk3 /mnt/disks /mnt/remotes /mnt/rootshare /mnt/user /mnt/user0 Apr 18 12:59:45 DataTower rc.local_shutdown: Active pids left on /dev/md* Apr 18 12:59:45 DataTower rc.local_shutdown: fuser -mv /dev/md1p1 /dev/md2p1 /dev/md3p1 Apr 18 12:59:45 DataTower rc.local_shutdown: Generating diagnostics... Apr 18 13:01:18 DataTower emhttpd: Stopping services... Apr 18 13:01:37 DataTower shfs: share cache full Apr 18 13:01:37 DataTower shfs: share cache full Apr 18 13:01:38 DataTower shfs: share cache full Apr 18 13:01:38 DataTower shfs: share cache full Apr 18 13:01:59 DataTower shfs: share cache full webui of various containers still online.
-
Hello! my wegGUI of Unraid isn't loading / ist stuck loading. i'm still on 7.0.0 i can reach most containers, looks like cache is close to full: root@DataTower:/var/log# df Filesystem 1K-blocks Used Available Use% Mounted on rootfs 7109792 249400 6860392 4% / tmpfs 131072 2000 129072 2% /run /dev/sda1 15000232 1270880 13729352 9% /boot overlay 7109792 249400 6860392 4% /usr overlay 7109792 249400 6860392 4% /lib tmpfs 131072 436 130636 1% /var/log devtmpfs 8192 0 8192 0% /dev tmpfs 7127764 0 7127764 0% /dev/shm tmpfs 1024 0 1024 0% /mnt/disks tmpfs 1024 0 1024 0% /mnt/remotes tmpfs 1024 0 1024 0% /mnt/addons tmpfs 1024 0 1024 0% /mnt/rootshare /dev/md1p1 7811939620 7156559028 655380592 92% /mnt/disk1 /dev/md2p1 7812595740 3549357176 4263238564 46% /mnt/disk2 /dev/md3p1 11716798412 6053375908 5663422504 52% /mnt/disk3 /dev/nvme0n1p1 976761560 973175712 582944 100% /mnt/cache shfs 27341333772 16759292120 10582041652 62% /mnt/user0 shfs 27341333772 16759292120 10582041652 62% /mnt/user /dev/loop2 31457280 25576184 4962312 84% /var/lib/docker tmpfs 1425552 0 1425552 0% /run/user/0 /var/log was also 100% full, deleted syslog.1, most of the entries said: DataTower shfs: share cache full i don't really understand why the gui is not responsive... edit: after loading for a while i got the nginx error 500 Internal Server Error what can i do? edit2: i was able to run diagnostics from console, but how can i get the file? can't access SMB shares and i can't connect with winSCP. best regards
-
Hello! today i noticed that my urbackup folder under appdata occupies a lot of space. urbackup.log was 6.5 gb (ERROR: Sending broadcast failed! (ipv6), hopefully i was able to fix this by setting BROADCAST_INTERFACES="eth0")! the other culprid is backup_server_files.db with 3.6 gb. seems excessive... or is this normal? best regards
-
hello! i switched form LMS to this container, thanks for the efforts! common problems told me that my docker space is getting crowded so i looked at the sizes of my various docker. LyrionMusicServer uses 1.18 GB, is that normal? best regards!
-
is there a way to verify? what is the share floor? the "Minimum free space" in the share settings? this is set to 97.7 GB for downloads share. at this moment there's more then enough space: i doubt that on april 4 chache was filled up to 900gb (again: can i verify that?).
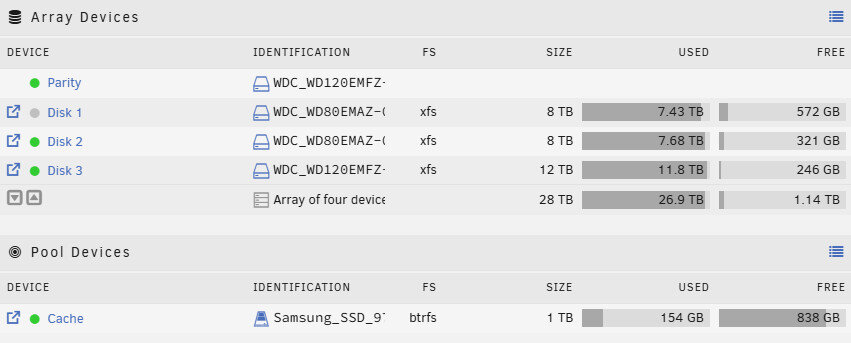
-
syslog.1 has 1832696 lines, 1831923 say [Timestamp] DataTower shfs: share cache full all between Apr 4 08:26:34 and Apr 4 13:21:44 from what i can see this is caused by downloads. but my dl share is set to primary > cache and secondary > array, so when cache is full it should write directly to array, no?
-
looks like syslogs take up all the space: root@DataTower:~# du -h /var/log/ 0 /var/log/libvirt/ch 0 /var/log/libvirt/qemu 0 /var/log/libvirt 0 /var/log/nfsd 4.0K /var/log/nginx 28K /var/log/pkgtools/removed_packages 16K /var/log/pkgtools/removed_scripts 0 /var/log/pkgtools/removed_uninstall_scripts 44K /var/log/pkgtools 0 /var/log/plugins 0 /var/log/sa 0 /var/log/samba/cores/smbd 0 /var/log/samba/cores/nmbd 0 /var/log/samba/cores/winbindd 0 /var/log/samba/cores/samba-dcerpcd 0 /var/log/samba/cores/rpcd_lsad 0 /var/log/samba/cores/rpcd_classic 0 /var/log/samba/cores/rpcd_winreg 0 /var/log/samba/cores 4.0K /var/log/samba 0 /var/log/swtpm/libvirt/qemu 0 /var/log/swtpm/libvirt 0 /var/log/swtpm 0 /var/log/preclear 0 /var/log/pwfail 88M /var/log/ root@DataTower:~# ls -l /var/log total 89256 -rw------- 1 root root 0 Jan 9 23:13 btmp -rw-r--r-- 1 root root 0 Apr 28 2021 cron -rw-r--r-- 1 root root 0 Apr 28 2021 debug -rw-r--r-- 1 root root 63273 Feb 3 21:44 dmesg -rw-r--r-- 1 root root 184384 Apr 9 00:03 docker.log -rw-r--r-- 1 root root 0 Dec 5 22:48 faillog -rw-r--r-- 1 root root 292 Apr 9 17:31 lastlog drwxr-xr-x 4 root root 80 Sep 28 2024 libvirt/ -rw-r--r-- 1 root root 0 Apr 28 2021 maillog -rw-r--r-- 1 root root 0 Apr 28 2021 messages drwxr-xr-x 2 root root 40 Dec 11 19:44 nfsd/ drwxr-x--- 2 nobody root 60 Feb 3 21:45 nginx/ lrwxrwxrwx 1 root root 24 Jan 9 23:11 packages -> ../lib/pkgtools/packages/ drwxr-xr-x 5 root root 100 Feb 3 21:45 pkgtools/ drwxr-xr-x 2 root root 400 Mar 28 00:00 plugins/ drwxr-xr-x 2 root root 60 Feb 3 21:45 preclear/ drwxr-xr-x 2 root root 40 Apr 9 12:08 pwfail/ lrwxrwxrwx 1 root root 25 Jan 9 23:13 removed_packages -> pkgtools/removed_packages/ lrwxrwxrwx 1 root root 24 Jan 9 23:13 removed_scripts -> pkgtools/removed_scripts/ lrwxrwxrwx 1 root root 34 Feb 3 21:45 removed_uninstall_scripts -> pkgtools/removed_uninstall_scripts/ drwxr-xr-x 2 root root 40 Jul 3 2024 sa/ drwxr-xr-x 3 root root 320 Feb 3 21:44 samba/ lrwxrwxrwx 1 root root 23 Jan 9 23:11 scripts -> ../lib/pkgtools/scripts/ -rw-r--r-- 1 root root 0 Apr 28 2021 secure lrwxrwxrwx 1 root root 21 Jan 9 23:11 setup -> ../lib/pkgtools/setup/ -rw-r--r-- 1 root root 0 Apr 28 2021 spooler drwxr-xr-x 3 root root 60 Sep 28 2024 swtpm/ -rw-r--r-- 1 root root 169975 Apr 9 17:31 syslog -rw-r--r-- 1 root root 89829376 Apr 5 04:40 syslog.1 -rw-r--r-- 1 root root 1117857 Mar 26 04:40 syslog.2 -rw------- 1 root root 941 Feb 26 00:00 unbalanced.log -rw-r--r-- 1 root root 0 Feb 3 21:44 vfio-pci -rw-r--r-- 1 root root 0 Feb 3 21:44 vfio-pci-errors -rw-r--r-- 1 root root 670 Feb 3 21:44 wg-quick.log -rw-rw-r-- 1 root utmp 8832 Apr 9 17:31 wtmp best regards
-
Hi there! according to common problems my logs are increasing on size way too fast: so here i am, with diagnostics attached! i've had this some time ago but i didn't have diagnotics that time (becaue i had to reboot). any help appreciated! best regards datatower-diagnostics-20250409-1212.zip



