Kreavan
Members
-
Joined
-
Last visited
Everything posted by Kreavan
-
I got the same error. Not sure what to do.
-
I've heard that reverting to the previous 1.30.0 version fixes the issue. Just not sure how to do that.
-
I've had this docker running flawless for 5 months. I haven't changed anything, but now it is giving the following error: Raising maximum file descriptor to 65535 failed. This may cause problems with many clients. (errno=1) Raising nice-ceiling to 35 failed. (errno=1) Not sure what this is, or how to fix it.
-
Since I didn't really have anything on that drive needing to be recovered, I wiped the partion, re-formatted, and it's back up and running again. Still unsure what happened, but all good now. Thanks for the help folks!

-
I went in and disabled "Passthrough" in order to re-enable the option to "Mount." When I tried, it immediately fails. Checked the log and this is what is showing.
-
Yes
-
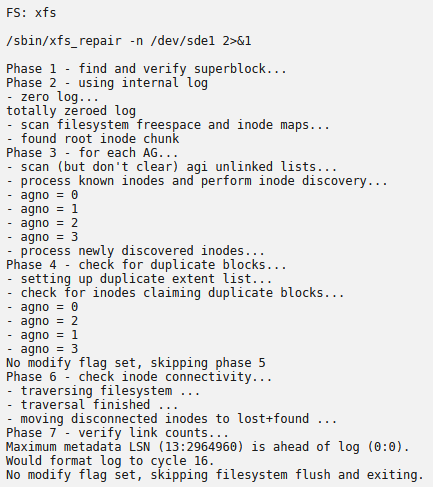
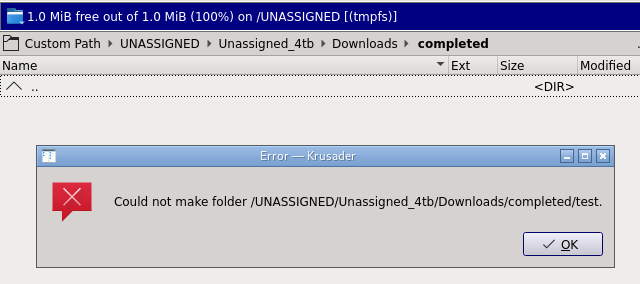
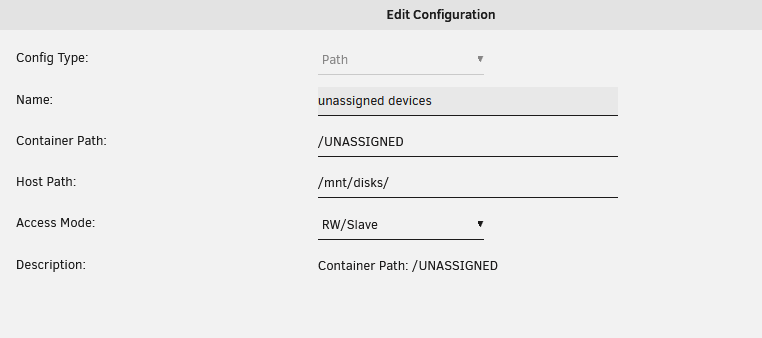
Not sure what happened, but all of a sudden my share is only showing 1mb in size. Yet, the drive in unassigned devices is showing 4tb. Uninstalling/reinstalling the plugin did nothing. Tried restoring Appdata from a previous backup (No change either). I've been using the drive as a location for downloads and transcodes. Ran a SMART test and everything passed. This is what is showing currently: File System Check results: when I navigate to the share in VNC, it is showing 1mb in size and I can go into the folder(s). However, I can no longer create anything in there. It is acting like the share is corrupt, but not sure how I can recreate it.