




jdndm
Members
-
Joined
-
Last visited
Everything posted by jdndm
-
Thanks, I checked the link and I had one of the affected firmware versions. Firmware has been upgraded to M3CR046. I'll monitor for a few days, and if stable I will mark your answer as the solution.
-
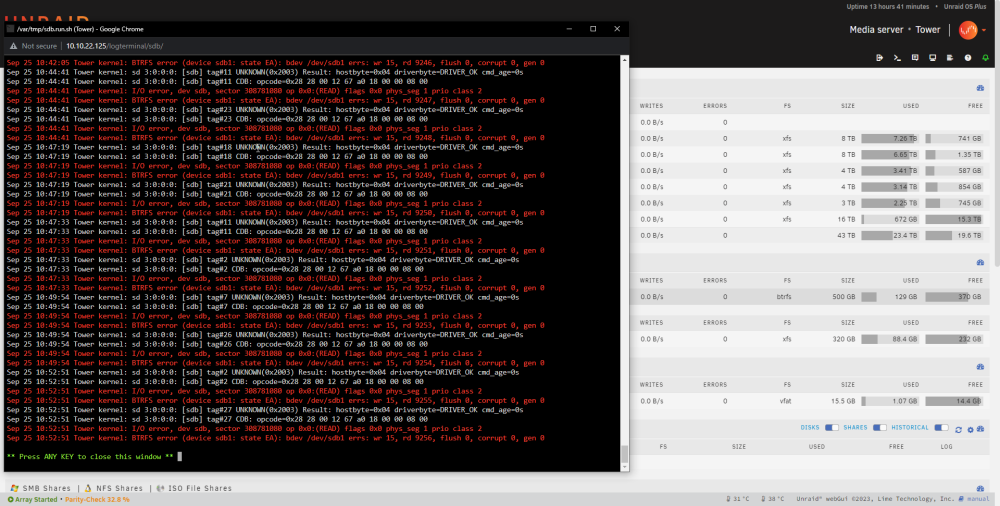
Just had another crash, diagnostics attached. The UI is still up, so if there's any further investigation I can do please let me know. tower-diagnostics-20230925-1040.zip
-
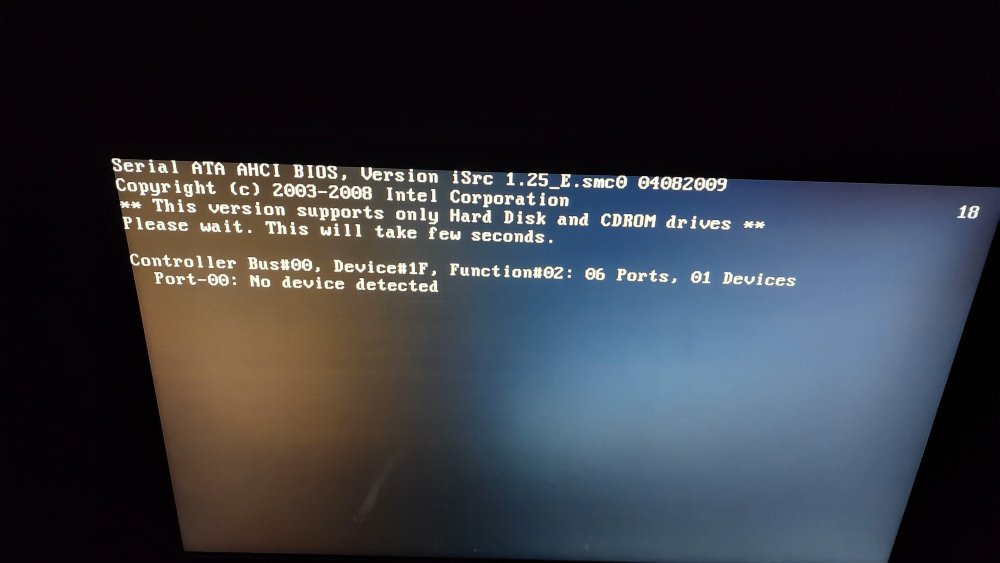
Hi, My unraid 6.12.3 server is crashing at random intervals. Sometimes it crashes and brings down the UI, but I've manage to catch the last couple of crashes to extract diagnostic files. I suspect that it is my cache drive that is causing the errors, but I'm really not sure. So far I have replaced power and sata cables, 2 different sata ports on the mobo, cache drive connected to HBA. I'm at a point where I'm sure something is failing and needs to be replaced but I'm not sure what it could be. I suspect it's the cache drive, HBA or onboard sata controller. Hardware: - Supermicro X8DTL - 8GB RAM - LSI SAS2008 HBA - 2 x 16TB Seagate Ironwolf - 2 x 8TB WD Red - 2 x 4TB WD Red - 1 x 3TB WD Green - 1 x 500GB MX500 (cache) - 1 x 320GB Seagate Momentus Here's a the section of the logs from when the server crashed Sep 23 06:29:59 Tower kernel: md: sync done. time=114533sec Sep 23 06:29:59 Tower kernel: md: recovery thread: exit status: 0 Sep 24 00:15:26 Tower kernel: ata2.00: exception Emask 0x0 SAct 0x41 SErr 0x0 action 0x6 frozen Sep 24 00:15:26 Tower kernel: ata2.00: failed command: READ FPDMA QUEUED Sep 24 00:15:26 Tower kernel: ata2.00: cmd 60/40:00:e0:1a:1f/00:00:00:00:00/40 tag 0 ncq dma 32768 in Sep 24 00:15:26 Tower kernel: res 40/00:01:00:00:00/00:00:00:00:00/00 Emask 0x4 (timeout) Sep 24 00:15:26 Tower kernel: ata2.00: status: { DRDY } Sep 24 00:15:26 Tower kernel: ata2.00: failed command: WRITE FPDMA QUEUED Sep 24 00:15:26 Tower kernel: ata2.00: cmd 61/40:30:40:48:51/00:00:00:00:00/40 tag 6 ncq dma 32768 out Sep 24 00:15:26 Tower kernel: res 40/00:01:00:00:00/00:00:00:00:00/00 Emask 0x4 (timeout) Sep 24 00:15:26 Tower kernel: ata2.00: status: { DRDY } Sep 24 00:15:26 Tower kernel: ata2: hard resetting link Sep 24 00:15:31 Tower kernel: ata2: link is slow to respond, please be patient (ready=0) Sep 24 00:15:36 Tower kernel: ata2: COMRESET failed (errno=-16) Sep 24 00:15:36 Tower kernel: ata2: hard resetting link Sep 24 00:15:41 Tower kernel: ata2: link is slow to respond, please be patient (ready=0) Sep 24 00:15:46 Tower kernel: ata2: COMRESET failed (errno=-16) Sep 24 00:15:46 Tower kernel: ata2: hard resetting link Sep 24 00:15:51 Tower kernel: ata2: link is slow to respond, please be patient (ready=0) Sep 24 00:16:21 Tower kernel: ata2: COMRESET failed (errno=-16) Sep 24 00:16:21 Tower kernel: ata2: limiting SATA link speed to 1.5 Gbps Sep 24 00:16:21 Tower kernel: ata2: hard resetting link Sep 24 00:16:26 Tower kernel: ata2: COMRESET failed (errno=-16) Sep 24 00:16:26 Tower kernel: ata2: reset failed, giving up Sep 24 00:16:26 Tower kernel: ata2.00: disable device Sep 24 00:16:26 Tower kernel: ata2: EH complete Sep 24 00:16:26 Tower kernel: sd 2:0:0:0: [sdb] tag#6 UNKNOWN(0x2003) Result: hostbyte=0x04 driverbyte=DRIVER_OK cmd_age=0s Sep 24 00:16:26 Tower kernel: sd 2:0:0:0: [sdb] tag#7 UNKNOWN(0x2003) Result: hostbyte=0x04 driverbyte=DRIVER_OK cmd_age=0s Sep 24 00:16:26 Tower kernel: sd 2:0:0:0: [sdb] tag#6 CDB: opcode=0x28 28 00 13 3f 37 60 00 00 08 00 Sep 24 00:16:26 Tower kernel: sd 2:0:0:0: [sdb] tag#7 CDB: opcode=0x28 28 00 13 41 ca 40 00 00 08 00 Sep 24 00:16:26 Tower kernel: sd 2:0:0:0: [sdb] tag#12 UNKNOWN(0x2003) Result: hostbyte=0x04 driverbyte=DRIVER_OK cmd_age=0s Sep 24 00:16:26 Tower kernel: I/O error, dev sdb, sector 322910048 op 0x0:(READ) flags 0x80700 phys_seg 1 prio class 2 Sep 24 00:16:26 Tower kernel: I/O error, dev sdb, sector 323078720 op 0x0:(READ) flags 0x80700 phys_seg 1 prio class 2 Sep 24 00:16:26 Tower kernel: sd 2:0:0:0: [sdb] tag#13 UNKNOWN(0x2003) Result: hostbyte=0x04 driverbyte=DRIVER_OK cmd_age=0s Sep 24 00:16:26 Tower kernel: sd 2:0:0:0: [sdb] tag#4 UNKNOWN(0x2003) Result: hostbyte=0x04 driverbyte=DRIVER_OK cmd_age=90s Sep 24 00:16:26 Tower kernel: sd 2:0:0:0: [sdb] tag#16 UNKNOWN(0x2003) Result: hostbyte=0x04 driverbyte=DRIVER_OK cmd_age=0s Sep 24 00:16:26 Tower kernel: sd 2:0:0:0: [sdb] tag#13 CDB: opcode=0x28 28 00 12 8b 3b 88 00 00 08 00 Sep 24 00:16:26 Tower kernel: sd 2:0:0:0: [sdb] tag#4 CDB: opcode=0x93 93 08 00 00 00 00 05 9f bb f8 00 00 f4 08 00 00 Sep 24 00:16:26 Tower kernel: sd 2:0:0:0: [sdb] tag#12 CDB: opcode=0x28 28 00 0f 3a 25 68 00 00 08 00 Sep 24 00:16:26 Tower kernel: I/O error, dev sdb, sector 94354424 op 0x3:(DISCARD) flags 0x800 phys_seg 1 prio class 2 Sep 24 00:16:26 Tower kernel: I/O error, dev sdb, sector 5326912 op 0x1:(WRITE) flags 0x1800 phys_seg 8 prio class 2 The first symptom that I've noticed a crash is that my docker containers are unavailable. I have found that I need to shutdown the server, and then power it back up to bring it online. If I attempt a reboot, I get this message on boot up (screenshot attached). Controller Bus#00, Device#1F, Function#02: 06 Ports, 01 Devices: Port-00: No device detected I haven't seen any of the drives reporting errors. Thanks in advance any light you might be able to shed on the situation. Cheers, jdndn tower-diagnostics-20230924-1845.zip
-
Well since that last shutdown I have been unable to get my system to boot up at all. I now have a "USB device overcurrent warning" and can't even load the BIOS. I've unplugged everything except a single stick of ram, CPU and 1 fan but still no luck. I'm suspect the motherboard has failed. Thanks for your help, but I'm going to have to leave it here for now and hope I have better luck with some different hardware.
-
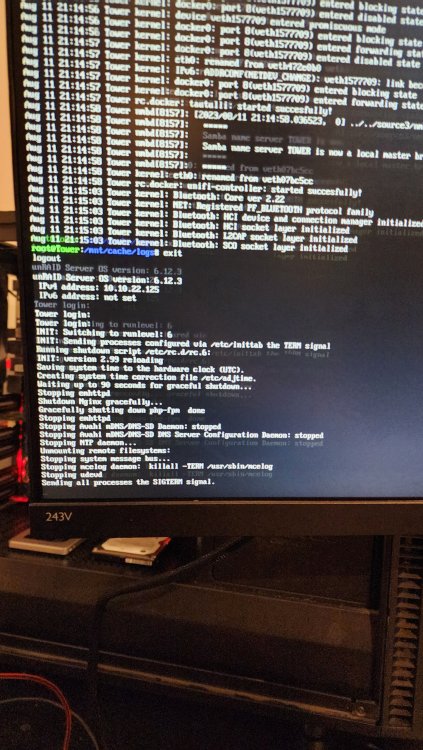
I think I just managed to catch it crashing from the console. Apologies for the crappy photo. I rushed to snap it. After this photo was taken, the server rebooted, the HBA loaded and discovered the attached drives. The BIOS failed to load after that, so nothing else booted. I'm stuck on a blank screen with a flashing cursor.
-
Ok red herring then, I'll ignore it. Would it be worth running a memory test to rule that out? I'm getting sick of rebooting the server so won't mind the downtime now!
-
I am seeing this in the logs that indicates an error with my HBA. I swapped the slots that my HBA is connected to and the error followed the device. Line 577: Aug 11 10:53:36 Tower kernel: mpt3sas 0000:02:00.0: invalid VPD tag 0x00 (size 0) at offset 0; assume missing optional EEPROM Line 1313: Aug 11 18:55:15 Tower kernel: mpt3sas 0000:01:00.0: invalid VPD tag 0x00 (size 0) at offset 0; assume missing optional EEPROM
-
Latest crash was around 19:54:43. I've attached a new diagnostics and syslog that is saved to the array. Below is the logs around the latest crash, I removed a bunch of `ACPI action...` logs that were flooding the logs. They were caused everytime I pressed an arrow key on the keyboard. I attempted to connect to the console after the crash to download diags / logs but no luck, so I don't think the logs are as complete as they could be.. Aug 11 18:44:45 Tower webGUI: Successful login user root from 10.10.22.110 Aug 11 18:46:24 Tower kernel: docker0: port 8(vethe89368e) entered blocking state Aug 11 18:46:24 Tower kernel: docker0: port 8(vethe89368e) entered disabled state Aug 11 18:46:24 Tower kernel: device vethe89368e entered promiscuous mode Aug 11 18:46:24 Tower kernel: docker0: port 8(vethe89368e) entered blocking state Aug 11 18:46:24 Tower kernel: docker0: port 8(vethe89368e) entered forwarding state Aug 11 18:46:24 Tower kernel: docker0: port 8(vethe89368e) entered disabled state Aug 11 18:46:24 Tower kernel: eth0: renamed from veth7fadde6 Aug 11 18:46:24 Tower kernel: IPv6: ADDRCONF(NETDEV_CHANGE): vethe89368e: link becomes ready Aug 11 18:46:24 Tower kernel: docker0: port 8(vethe89368e) entered blocking state Aug 11 18:46:24 Tower kernel: docker0: port 8(vethe89368e) entered forwarding state Aug 11 18:55:15 Tower kernel: mpt3sas 0000:01:00.0: invalid VPD tag 0x00 (size 0) at offset 0; assume missing optional EEPROM Aug 11 18:52:51 Tower root: ACPI action up is not defined Aug 11 18:55:27 Tower root: ACPI action down is not defined ... ... Aug 11 19:02:23 Tower root: ACPI action right is not defined Aug 11 19:12:40 Tower emhttpd: spinning down /dev/sde Aug 11 19:12:42 Tower emhttpd: spinning down /dev/sdh Aug 11 19:12:42 Tower emhttpd: spinning down /dev/sdg Aug 11 19:12:42 Tower emhttpd: spinning down /dev/sdd Aug 11 19:12:42 Tower emhttpd: spinning down /dev/sdf Aug 11 19:54:43 Tower emhttpd: spinning down /dev/sdb Aug 11 21:14:32 Tower root: Delaying execution of fix common problems scan for 10 minutes Aug 11 21:14:32 Tower unassigned.devices: Mounting 'Auto Mount' Devices... Aug 11 21:14:32 Tower emhttpd: Starting services... tower-diagnostics-20230811-2140.zip syslog-10.10.22.125.log
-
Hi, Please help if you can. I'm experiencing frequent server crashes, I suspect that it might be my cache drive (swapped SATA cable for a port on my HBA) as that has been giving errors in the past week. I can't see what has caused the crash this time. I have recently upgraded to 6.12.3 and installed new Mobo/CPU/RAM. Regretting doing all the upgrades at the same time now. Attached diagnostics and additional log files tower-diagnostics-20230811-1531.zip syslog-10.10.22.125.log
-
Thanks @aptalca got it working exactly how I wanted!
-
Where would I set the server name directive?
-
Hi, Hopefully someone can help me. I've got letsencrypt setup and working with various subdomains point at docker containers i.e. sonarr.mydomain.com but I want to do something a little different for some things that I only want to be accessible when I'm on my internal network i.e. internal.mydomain.com/nzbget or internal.mydomain.com/motioneyeos etc. I'm not sure how I should setup the proxy confs to point at the right location. I'm thinking something like this... location internal.mydomain.com/nzbget { # enable the next two lines for http auth #auth_basic "Restricted"; #auth_basic_user_file /config/nginx/.htpasswd; # enable the next two lines for ldap auth, also customize and enable ldap.conf in the default conf #auth_request /auth; #error_page 401 =200 /login; include /config/nginx/proxy.conf; resolver 127.0.0.11 valid=30s; set $upstream_app nzbget; set $upstream_port 6789; set $upstream_proto http; proxy_pass $upstream_proto://$upstream_app:$upstream_port; }




