




DrJake
Members
-
Joined
-
Last visited
Everything posted by DrJake
-
2 NICs were working before, eth1 was originally passed through to a Vm. Anyways, as suggested, I have unplugged eth1 (so there's only 1 active NIC on the Unraid server - eth0), and the drop count on eth0 is still ticking up.
-
eth0 and eth1 are connected to the same Ubiquiti router using 2 different cables. Looking at the drop counts, I doubt it's the cable. But where should I begin to investigate further? Like what can I check on the Unraid server?
-
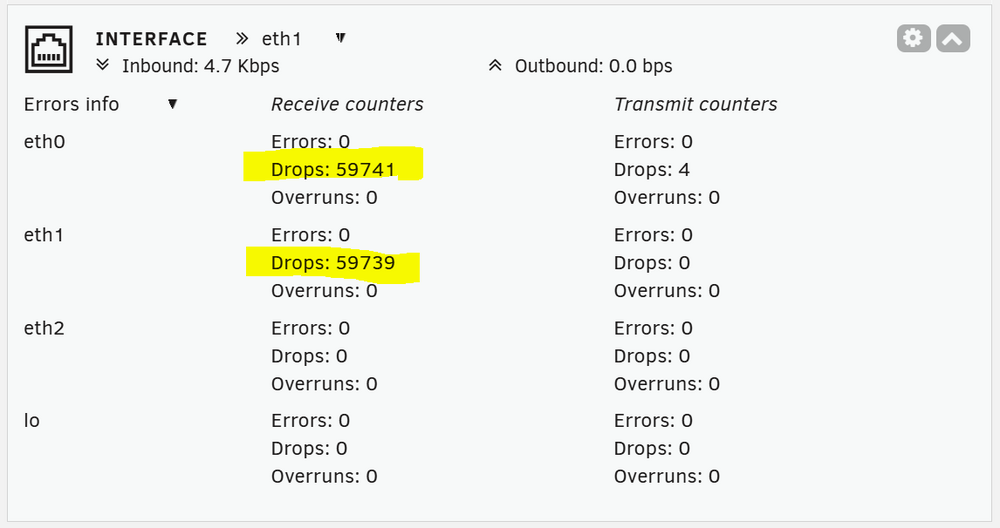
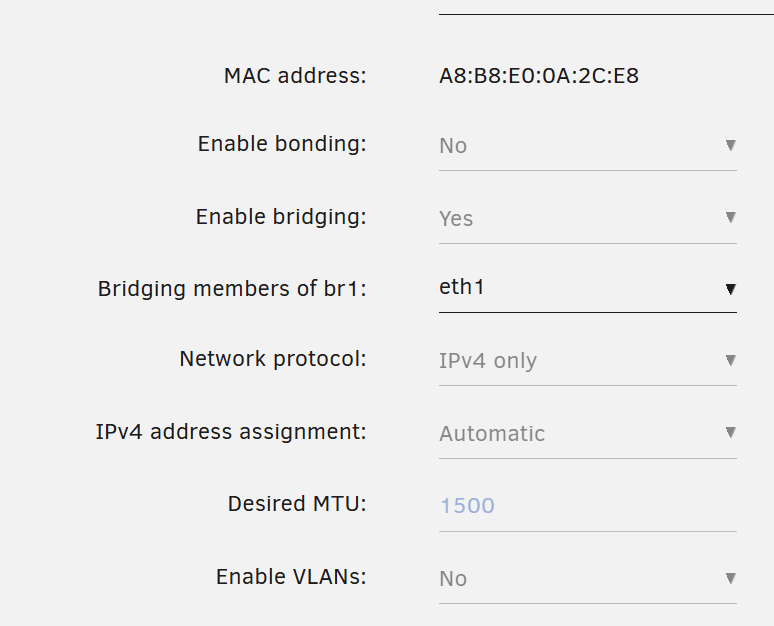
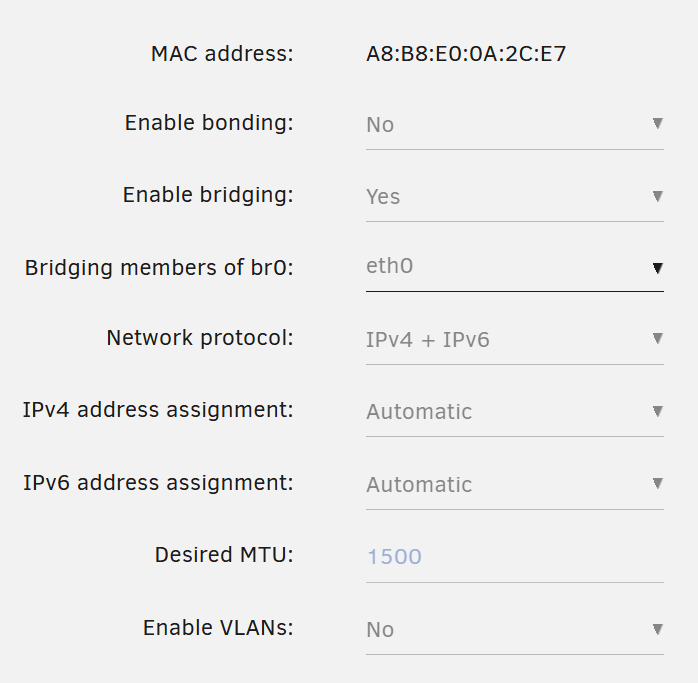
Hi all, I've been seeing a lots of "Drops" on the network interface and have no clue why. Below is the number of Drops recorded over 20 days (Unraid running time). The only problem I've experienced is that the torrent client in a VM often has error reading from the disk (Unassigned Device) containing the torrent file. Both eth0 and eth1 connect directly to an Ubiquity router. The sheer number of drops is a little troubling... Any leads to resolves this? Hardware wise, I'm running the N355 board which has 3 ethernet ports. eth0 and eth1 settings below. I can attach diagnostics if needed.
-
Hi all, just installed Immich and got it running no prob. I did a google search for Immich + iGPU and your post popped up. Stuck for an hour at Add the Extra Parameter: --device=/dev/dri. Read the instructions again, and noted that "Enable Advanced View in the top right corner" AFTER clicking "Edit docker", NOT the "Enable Advanced View in the top right corner" ON the Docker page.
-
Hi all, I've been running Unraid for a few years now, on a R7 3700x. The server runs 24/7 and has a few things going on, dockers (including deepstack), 3 VMs (1 for cctv, 1 for torrenting, and 1 for daily use), 6 HDD in the array and RAID 1 ssd cache. So my old philosophy was to get the Unraid server to handle as much as possible. Nowadays I find myself splitting the tasks out to other units, like I'm shutting down the daily use VM and now I use a normal win11 PC instead. I also plan to buy a NVR for dedicated cctv recordings and AI detection; So the Unraid server sits idle most of the time, but the idle power draw from the wall currently is around 80-100W. I've been eyeing NAS boards for a while, and I see some new boards (mini-ITX) have just came out. The new boards use N355 or R7 5825U processors; standard ATX-24PIN PSU connector; have 8 SATA connectors; and 2x M.2 NVMe slots. With TDP ~15W, these can potentially decrease my power consumption significantly. I haven't been following the Intel vs AMD closely, is one better than the other for running Unraid? A quick Google says that the R7 5825U would outperform the N355. I don't think I'd care about 15W vs 20W. Any Unraid/GPU compatibility or passthrough issues with either? Any input would be appreciated. Some links/images https://www.aliexpress.us/item/3256808910047961.html

-
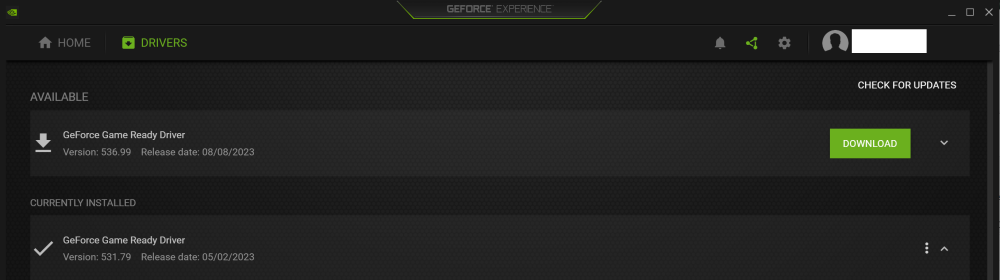
Hi all, I have a Gigabyte Gefore RTX3060 passed through to a win10 VM. It runs fine, no known performance issues. Since I installed the card, I've been unable to update the driver using the accompanying GeForce Experience software. I've attached a few screenshots below. It sees that new update is available (GPU1.png), and downloads it (GPU2.png), but nothing happens after download is complete. No error message, no install, nothing after restart, just nothing. So basically after the entire exercise it goes back to looking like GPU1.png. Is there any specific steps I need to follow to update the GPU driver?

-
Hello, thought I'd check-in again. My Unraid server is still rebooting ever 3-4 weeks. Last reboot on 8/September, and the time before that was on 12/August, and 29/July. Been running a syslog server and recorded the last 3 resets (logs attached). The log entries below are there each time there was a reboot. Not sure if it happened before or after the reboot. The GPU for VM seems quite stable these days, even did stress testing without crashing. Could someone take a look and point me to the right direction? I'm running out of things to try here. Jul 29 21:35:20 Tower kernel: usb 3-2: reset full-speed USB device number 2 using xhci_hcd Jul 29 21:35:20 Tower kernel: usb 1-3: reset full-speed USB device number 2 using xhci_hcd Jul 29 21:35:24 Tower kernel: usb 3-2: reset full-speed USB device number 2 using xhci_hcd Jul 29 21:35:24 Tower kernel: usb 1-3: reset full-speed USB device number 2 using xhci_hcd Jul 29 21:37:55 Tower webGUI: Successful login user root from 192.168.11.7 Jul 29 21:38:01 Tower kernel: clocksource: timekeeping watchdog on CPU7: Marking clocksource 'tsc' as unstable because the skew is too large: Jul 29 21:38:01 Tower kernel: clocksource: 'hpet' wd_now: 71b477c4 wd_last: 7100a93b mask: ffffffff Jul 29 21:38:01 Tower kernel: clocksource: 'tsc' cs_now: ecc745390ca5c cs_last: ecc73ce4daf64 mask: ffffffffffffffff Jul 29 21:38:01 Tower kernel: tsc: Marking TSC unstable due to clocksource watchdog Jul 29 21:38:01 Tower kernel: TSC found unstable after boot, most likely due to broken BIOS. Use 'tsc=unstable'. Jul 29 21:38:01 Tower kernel: sched_clock: Marking unstable (1159212382806303, -10482851288)<-(1159202045772327, -145824138) Jul 29 21:38:02 Tower kernel: clocksource: Switched to clocksource hpet Aug 12 00:05:06 Tower kernel: usb 3-2: reset full-speed USB device number 2 using xhci_hcd Aug 12 00:05:06 Tower kernel: usb 1-3: reset full-speed USB device number 2 using xhci_hcd Aug 12 00:05:09 Tower kernel: usb 3-2: reset full-speed USB device number 2 using xhci_hcd Aug 12 00:05:10 Tower kernel: usb 1-3: reset full-speed USB device number 2 using xhci_hcd Aug 12 00:07:42 Tower kernel: clocksource: timekeeping watchdog on CPU15: Marking clocksource 'tsc' as unstable because the skew is too large: Aug 12 00:07:42 Tower kernel: clocksource: 'hpet' wd_now: 31b6948a wd_last: 313252fd mask: ffffffff Aug 12 00:07:42 Tower kernel: clocksource: 'tsc' cs_now: e710a7ac3d094 cs_last: e710a2445a3b4 mask: ffffffffffffffff Aug 12 00:07:42 Tower kernel: tsc: Marking TSC unstable due to clocksource watchdog Aug 12 00:07:42 Tower kernel: TSC found unstable after boot, most likely due to broken BIOS. Use 'tsc=unstable'. Aug 12 00:07:42 Tower kernel: sched_clock: Marking unstable (1131240282539958, -10214497034)<-(1131230211029576, -142991887) Aug 12 00:07:43 Tower kernel: clocksource: Switched to clocksource hpet Sep 8 17:35:55 Tower kernel: usb 3-2: reset full-speed USB device number 2 using xhci_hcd Sep 8 17:35:56 Tower kernel: usb 1-3: reset full-speed USB device number 2 using xhci_hcd Sep 8 17:35:59 Tower kernel: usb 3-2: reset full-speed USB device number 2 using xhci_hcd Sep 8 17:35:59 Tower kernel: usb 1-3: reset full-speed USB device number 2 using xhci_hcd Sep 8 17:38:34 Tower kernel: clocksource: timekeeping watchdog on CPU3: Marking clocksource 'tsc' as unstable because the skew is too large: Sep 8 17:38:34 Tower kernel: clocksource: 'hpet' wd_now: f5ae5efc wd_last: f4fdec69 mask: ffffffff Sep 8 17:38:34 Tower kernel: clocksource: 'tsc' cs_now: 1e2215fac635f8 cs_last: 1e221579001198 mask: ffffffffffffffff Sep 8 17:38:34 Tower kernel: tsc: Marking TSC unstable due to clocksource watchdog Sep 8 17:38:34 Tower kernel: TSC found unstable after boot, most likely due to broken BIOS. Use 'tsc=unstable'. Sep 8 17:38:34 Tower kernel: sched_clock: Marking unstable (2360442394677355, -18500752721)<-(2360424039483928, -145566028) Sep 8 17:38:34 Tower kernel: clocksource: Switched to clocksource hpet 20220908 unraid crash 1738.log 20220729 unraid crash 2130.log 20220812 double crash 0.00am and 9.40am.log
-
Hi again, Thought I'd give an update and close this thread. Thx again ChatNoir, I think it helped a lot with the RAM speed dialed back, resolving that instability issue. Since then, the Unraid server crash problem feels more like 2 separate issues compounded together. It was very telling when the GPU crashes, and the VM and the Unraid server remained operational. I found this thread, https://www.reddit.com/r/Amd/comments/pf4ebr/figured_out_a_fix_for_the_rx_580_intermittent/, it sounds like the RX580OC crashing is a common problem, and coincidentally also relates to the OC clock speed (similar to the RAM speed issue). So since my last post couple days ago, I went ahead and rebooted the server. I followed the instructions in that thread above, installed Adrenalin (the install required many reboots, and RX580 kept crashing, and install wouldn't progress unless it detects a valid GPU... so had to reboot the server quite a few times...). Anyhow, it's now installed, and I used it to manually tune the GPU clock to the base speed of 1257MHz, did a stress test, and nothing crashed, phew. So that's where I am now. Let's see how long the server can run this time without issues (I'm quite hopeful actually).
-
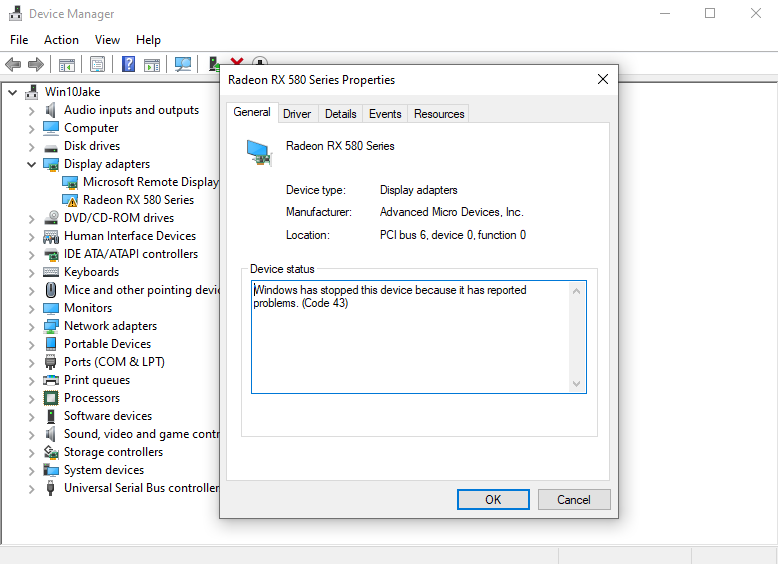
Hi again ChatNoir, since adjusting the RAM speed, my server uptime is ~29 days 14 hours now. ~2 days ago, the GPU passed through to a VM stopped working. I kinda suspected that my system crashes were related to the GPU (RX580) somehow, but cannot confirm. I've attached the syslog here, don't think there's anything about the GPU. So the current situation is that, the VM (with the GPU passed through) is still running, I can RDC into it and everything work, just that the screen attached to the Unraid server is not showing anything. But Win10 is reporting issues (see screenshot). In the past, I have used SpaceInvaderOne's script to reset the GPU, and more recently I tend to just shut down the server and restart it. I have left the server running for 2 days now since the GPU "crash", and it appears to be stable. Regarding the GPU, I followed SpaceInvaderOne's video on dumping vbios, and passing it through. I don't think there's much of an issue there, plus if I were to restart the server, the GPU would be working again. So my question is, what should I do to further diagnose the problem here? ~3-4 weeks seems to be the magical timeframe when the GPU experiences issues, and that's also the timeframe past unraid reboots have happened. Should I keep the server running for another month and see if it crashes? unraid syslog 20220715.log
-
Thank you ChatNoir, there's a lot of information to digest. Already acted on the fix common problems issues as suggested. Re: memory speed, I'm running AMD Ryzen 7 3700X 8-Core @ 3600 MHz, and 4 pieces of Corsair Vengeance LPX (4x16GB) DDR4 3200MHz C16 Desktop Gaming Memory Black. I'm pretty sure I set the memory speed at 3200MHz. According to your linked thread, for 3rd gen processor running dual 4/4 config the speed should be dialed back to 2667MHz? is that correct? I will check on the c-state once I get back.
-
Hi all, For reasons unknown, my Unraid sever reboots itself every 3-4 weeks, during this period, there doesn't seem to be any issues with the server. It has happened for 6 months+ now, and has recently caught my attention. I kinda discarded it as something I did to crash it in the early days. Anyhow, I have followed the instructions and installed "mcelog via the NerdPack plugin", the system diagnostics is attached, hope there is something in the log before the latest self-reboot (~6 hours ago). tower-diagnostics-20220605-1022.zip
-
Thank you again Jorge, can mark this one as resolved. Lucky I encountered this issue without actually losing the cache data
-
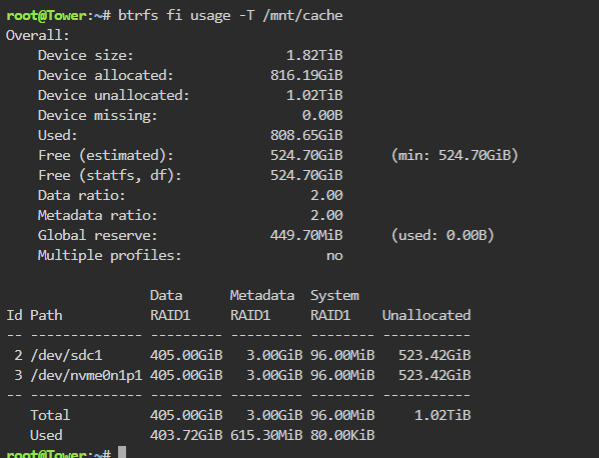
Thx for getting back to me Jorge, I suspected it was an issue with the cache pool, something is still bugging out. So I ended up taking the long way around. 1. transferred all the cache data back to the array (for peace of mind as well) 2. deleted the cache pool 3. rebooted the server 4. recreated the cache pool (at some point I needed to use the "btrfs-select-super -s 1 /dev/nvme1n1p1" command again, because the system was preventing me from mounting the drive as an unassigned device) 5. now I think everything is in working order, the mover is still moving data from the array back onto the new cache pool. So just to confirm, this means the cache pool is working in RAID1 config right? Does the ID number matter as to which drive data will be read/written from/to? because 1 is SATA and 1 is NVMe.
-
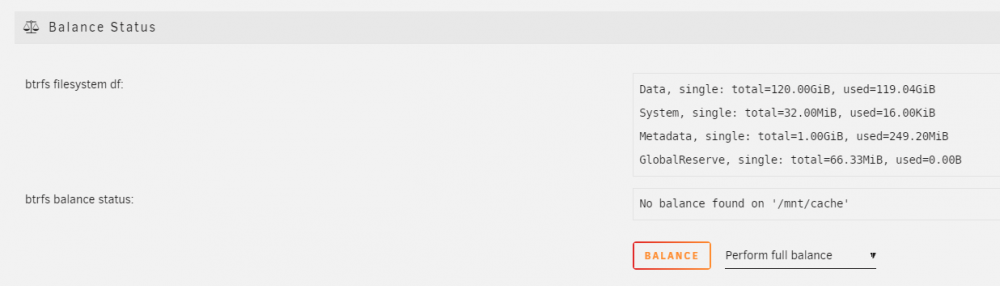
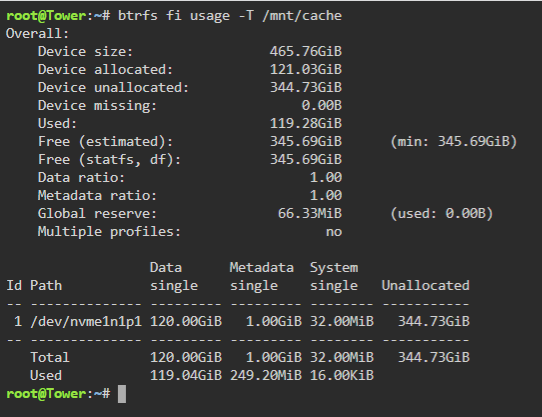
Hi Jorge, something is not right. I'm only at step 1, but dont think the device was correctly added to the pool (for reasons unknown to me). It says the 1TB sata ssd is "part of a pool". I tried to do "balance" in the GUI of Cache (nvme1n1), twice, each time completed without complaint. FYI it would not allow me to "convert to raid1 mode" here. Afterwards, using "btrfs fi usage -T /mnt/cache" I get this, doesn't even look like the device is in the pool... Tried to run "btrfs balance start -mconvert=raid1 /mnt/cache" posted on the other thread, and got error syslog says Dec 30 11:48:38 Tower kernel: BTRFS error (device nvme1n1p1): balance: invalid convert metadata profile raid1 P.S. I tried stopping the array and adding the 2nd cache device twice, same issues. syslog and new diagnostics attached. syslog.txt tower-diagnostics-20211230-1151.zip


-
oh wow, thank you thank you so much Jorge. the server back to life now, with VMs and Dockers all working fine. You've saved me a lot of time reconfiguring my VMs and security cameras... So back to what I was trying to do in the beginning. I'm trying to swap out the 500GB NVMe where the cache data is on at the moment, and replace it with a 1TB NVMe (currently has data, and used as an unassigned device) pooled with a 1TB SATA ssd. Following what I originally was planning to do, I guess: 1. add the 1TB SATA ssd to the cache pool (resulting in the redundant cache pool I should have had at the beginning) 2. remove the 500GB NVMe from the cache pool (the 1TB SATA ssd should still function, right?) 3. do my data transfer, so the 1TB NVMe is free 4. add the 1TB NVMe to the cache pool Is there a better way? I'm a bit worried about step 2 and 4, because what I just went through Would the 1TB SATA ssd be a functional cache drive by itself after step 2?
-
So I guess I'm just trying to recover the data on my cache drive at this point. The 2 pooled drives were setup as raid1 in case 1 of them failed. But at the moment, I can't seem to figure out/find information about how to recover the data. I just saw this thread, and think I might be one of these cases... cant remember when I setup the redundancy, but I recall it was the Unraid version when the pooled cache feature was first introduced. I believe I have not done anything irreversible, (have not formatted any of the drives, have not rebooted the server). But think I need some expert help... tower-diagnostics-20211229-1432.zip
-
Hi all, I currently have 2 drives assigned to the cache pool: 1TB SATA ssd 500GB NVMe ssd (intend to remove from the pool I read the FAQ on removing the cache drive, but I'm encountering issues I'm not sure how to proceed. I'm running Unraid 6.9.2, followed the instructions to the letter. 1. stop the array 2. unassign pool disk to remove 3. did not do any re-ordering 4. start the array (after checking the "I'm sure" box next to the start array button) The system is asking me if I want to format the cache2 drive, which is the one I intend to keep in the pool. The drive that was removed from the pool could not be mounted as an unassigned device. I planned on doing this later after the cache pool is sorted... Having encountered this problem, I didn't really want to deal with a server problem during the holidays... I tried to add the drive I removed back into the pool, but seems like I cannot anymore... I read on the forum about physically removing the drive, but that was an older version of Unraid, so I wanted to check with the pros before I shut down the server n all... Help... what are my options at this stage?



-
Hi CS, no, I didn't. After diagnosing the Plex library indexing thing, I monitored the unraid server occasionally, and the disks are sleeping most of the time. So I haven't bothered with the *.tmp files. If you figure it out, please do post
-
Hi all, Thx for all the input. I think this thread can be marked as (resolved now). I still get the odd temp file created and also get some odd opening of selected files on the Plex server at ~2.30am... when i know for sure nobody is accessing the plex server. Anyhow, these don't occur frequently, and don't matter much, as my HDD sleep timer is set a 3h, and these don't cause additional spin ups when mover does its thing. Overall, I found the fileactivity plugin very helpful in isolating the issues.
-
I ended up moving the ISOs folder to cache, only took up like 15Gb of space, which is quite tolerable for me. I've been monitoring the fileactivity for a few days since last reporting here, it has been working very well, I think the disks only needs to spin up when I watch Plex, and at 3.40am for the movers. Regarding the syncthing problem, I still don't really know how it works, but in my current setup it appears to be not scanning much. In the fileactivity log, I see the following (I don't think it happens daily, as I haven't noticed it before), does anyone know what is creating the .tmp files? if it'll cause the drives to spin up, and how to avoid it? Jan 10 04:30:13 CREATE => /mnt/disk1/2041296744.tmp Jan 10 04:30:13 OPEN => /mnt/disk1/2041296744.tmp Jan 10 04:30:13 OPEN => /mnt/disk1/2041296744.tmp Jan 10 04:30:13 DELETE => /mnt/disk1/2041296744.tmp Jan 10 04:30:13 CREATE => /mnt/disk2/1694051432.tmp Jan 10 04:30:13 OPEN => /mnt/disk2/1694051432.tmp Jan 10 04:30:13 OPEN => /mnt/disk2/1694051432.tmp Jan 10 04:30:13 DELETE => /mnt/disk2/1694051432.tmp Jan 10 04:30:13 CREATE => /mnt/disk3/2030880645.tmp Jan 10 04:30:13 OPEN => /mnt/disk3/2030880645.tmp Jan 10 04:30:13 DELETE => /mnt/disk3/2030880645.tmp
-
Yes you are correct. It was quite revealing after installing the FileActivity plugin. Couple things I've learned: The ISOs folder is opened whenever I start a VM (that was quite contrary to what I thought actually, as the ISO just contains the installation image and the virtio). So think I will have to move this to the cache as well. Most of the file activity before was from the Plex docker. It scanned the entire library periodically. This was turned off in the plex settings. I think the above points resolves most of the issue. I've yet to gather enough data on the syncthing docker as I've only recently started using it. Most of the devices in the household (phones, tablets) I think are only syncing at night. But I think the docker itself does keep scanning the folders for updates (not so much applicable for phone backup, but more for shared folders across multiple computers), not sure what the best way is for that.
-
woah. more plugins! thx for pointing me in the right direction. Installed the first 2, they seem to fit the bill. Will report back in a few days
-
happy new year all, any thought on this?
-
here you go sir tower-diagnostics-20201222-1601.zip
-
Hi can't think of a good title thats spot on the issue. So here it goes. I see many people have their unraid setup in such a way that uses SSDs for either cache and/or unassigned devices (UD), as this can greatly increase the perceived speed of the system. There is also an abundant discussion about whether to leave the HDD always spinning, and I believe the consensus is that it is bad to spin up and down too often. So what I would like to do is to work off SSD almost entirely, and have the mechanical drives in the array sleep for most of the day. Then have the mover do its thing daily. So in theory this would only cause the mechanical HDDs to spin up once/twice a day at most. I presume someone has done this before, any comments or suggestions would be appreciated. I do however, have a problem. One of my drives keeps spinning up for some reason. I would like to know what is causing them to spin up. I have 2 always on VMs, 1 running from cache (/domains), 1 running from (UD), and bunch of dockers. The appdata, domains, and system shares are all set to cache=prefer. I've been monitoring the drive that spins up from the dashboard, it gets very few reads/writes, like less than 100 counts/day, it also triggers write to the parity drive as well. The drive has on it the following folders: isos (has VM images) Media (the entire Plex library) Photos ( Share (default folder?) Other personal folders My understanding is that the isos folder are not getting written to. I can also confirm that nobody was watching Plex. Does anyone know what's causing the array drive to spin up?
















