




Unrayed
Members
-
Joined
-
Last visited
-
The solution to this lied with the fact that SWAG no longer respects that root/cron file without the cron docker-mod installed. Info and solution here, confirmed as working as required now - https://github.com/linuxserver/docker-mods/tree/universal-cron
-
Just on this, I don't seem to have a le-renew.sh file in my Swag files anywhere in appdata/swag....is this normal or has something maybe been lost from my installation?
-
I'm having an issue whereby my certs are no longer auto-renewing. I had the cron set for 20:30 each night to check and renew if necessary, but for whatever reason, it recently stopped using the specified cron time and is now using the default 2:08am time (a time that my server is powered off.) Appdata/swag/crontabs/root: 30 20 * * * /app/le-renew.sh >> /config/log/letsencrypt/letsencrypt.log 2>&1 cronjob running on Mon Nov 20 20:30:00 GMT 2023 Running certbot renew Saving debug log to /var/log/letsencrypt/letsencrypt.log - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - Processing /etc/letsencrypt/renewal/mydomain.conf - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - Certificate not yet due for renewal - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - The following certificates are not due for renewal yet: /etc/letsencrypt/live/mydomain/fullchain.pem expires on 2024-01-14 (skipped) No renewals were attempted. - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - <-------------------------------------------------> <-------------------------------------------------> cronjob running on Tue Jan 2 02:08:00 GMT 2024 Running certbot renew Saving debug log to /var/log/letsencrypt/letsencrypt.log - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - Processing /etc/letsencrypt/renewal/mydomain.conf - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - Certificate not yet due for renewal - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - The following certificates are not due for renewal yet: /etc/letsencrypt/live/mydomain/fullchain.pem expires on 2024-03-26 (skipped) No renewals were attempted. - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - ^^^ You can see here that things USED to run normally for me at 20:30, but more recently it's back to 02:08 and the cron time specified above isn't being used. Has anyone ANY idea how to fix this? I really don't want to wait for cert expiry reminder emails and then have to manually renew them with certbot. Would appreciate any help, thanks
-
Perfect, leave it with me for a while and I'll try grab a small ssd from somewhere. Thanks for all your help with this
-
I'll have to find something. How would I go about this, in terms of my current cache being a dual drive btrfs pool and a theoretical replacement/test drive likely being much smaller in capacity and only being a single drive?
-
Ok tried disabling each of the drives and performing an SMB transfer of a 5GB file from W10 to Unraid. With the 870 disabled, the file transferred at an inconsistent ~50/70MB/s. With the 860 disabled, the exact same file began transferring at full 113MB/s, but after about 2GB of it, the speed dropped down into the same low/fluctuating range as before.
-
Thanks for the suggestion, I'll definitely try this. Will the pool function as normal for the purposes of testing with one of its drives removed yes?
-
Apologies, I forgot to attach the server-diagnostics.zip file in the opening post....here it is now.... server-diagnostics-20221016-1307.zip
-
Thanks for the reply Jorge, No the cache pool isn't old - the 870 EVO was bought this year and has ~500 hours logged (total lbas written = 1152436200), and the 860 EVO was bought maybe 2 years ago and has ~6000 hours on it (total lbas written = 22846605052). Neither have any reallocated sectors, and appear in perfect health. Both drives also report as 1MiB alligned. Trimming is scheduled for a daily run @ 16:30, using Unraid's own Trim tool (settings, scheduler, trim).
-
Hi all, Wondering if anyone can advise me. I've had a long enough standing issue, persistent through multiple Unraid releases, thereby I can't saturate write speeds to my cache drive. 95% of the time, anything I transfer across the LAN here will fluctuate between 50-70MB/s when transferring from my PC (Windows 10) to my Unraid Server (using x2 SSD cache drives in a BTRFS pool.) If I bypass the SSD Cache Pool, and transfer directly to the array, I'll saturate the LAN speed (~112MB/s), which rules out any type of hardware/network issue. So it's actually slower for me to use my SSD write cache, which is frustrating. The Cache pool is made up of a Samsung 870 EVO 1TB, and a Samsung 860 EVO 1TB, so not exactly bargain bin drives. I've read a fair bit on this issue, it's not uncommon, but seemingly quite individual at times. The most recent thing I tried was adding... server min protocol = SMB3_11 client min protocol = SMB3_11 ...to my Samba Extra Configuration settings in Unraid, but to no avail. When I originally set up Unraid, I think one of the 6.7 or 6.8 releases, I had no such issues with transfer speeds, and could saturate the write cache without problem. I'm at my wits end now and unsure how to diagnose the issue. This happens for large single files, and not only for large amounts of small files where you'd expect to see this behavior. Speeds are erratic, and hugely inconsistent. The very odd day though, it might not happen and I'll see ~114MB/s across the lan to the write cache, but it never lasts, and the next day I'll be right back to fluctuating/slower speeds.
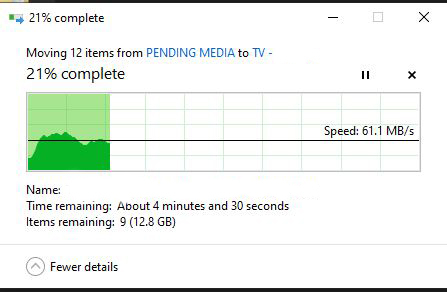
-
Wondering can anyone help/advise me here, I'm having a very intermittent problem with a "Docker Image Disk Utilization of 100%" error popping up for me. I'm on Unraid 6.11.1 (though this has happened to me on previous release versions too), and running the latest Emby as of writing (4.7.8.0, though again, previous releases threw this error up too.) Last night I got an alert about this error, and then ~5 mins later another alert to state the utilization had returned to normal levels, so I wasn't able to check anything really. I feel it's a transcoding issue, and something screwed up with my directory config perhaps? My cache pool is x2 1TB SSD's in a BTRFS pool. I do share parts of my Emby library with select family members, and looking at Emby when the error popped up last night, there was indeed a family member logged in a consuming media. My setup is as follows: Folder on cache pool for Emby transcoding is - "/mnt/cache/appdata/EmbyServer/transcode/transcoding-temp" My Emby server is then configured to use the container path of "/Transcoding" which is pointed to the host path of "/mnt/cache/appdata/EmbyServer/transcode" If I then play media on my LAN and select a low quality version, I can see the "/mnt/cache/appdata/EmbyServer/transcode/transcoding-temp" starts to become populated with files/folders....so I THINK Emby is correctly transcoding onto my SSD pool, and NOT within the docker image itself? Can anyone help/advise?
-
Sorted there on Windows 10, I changed the attached setting to display as shown. It was set to "Use NTLMv2 Security Session if needed", and I vaguely remember changing this setting ages ago to help with slow SMB speeds, so maybe that's the issue? Unfortunately though, I'm still seeing fluctuating/slow smb transfers to my cache drive (980 Evo x2 in BTRFS)
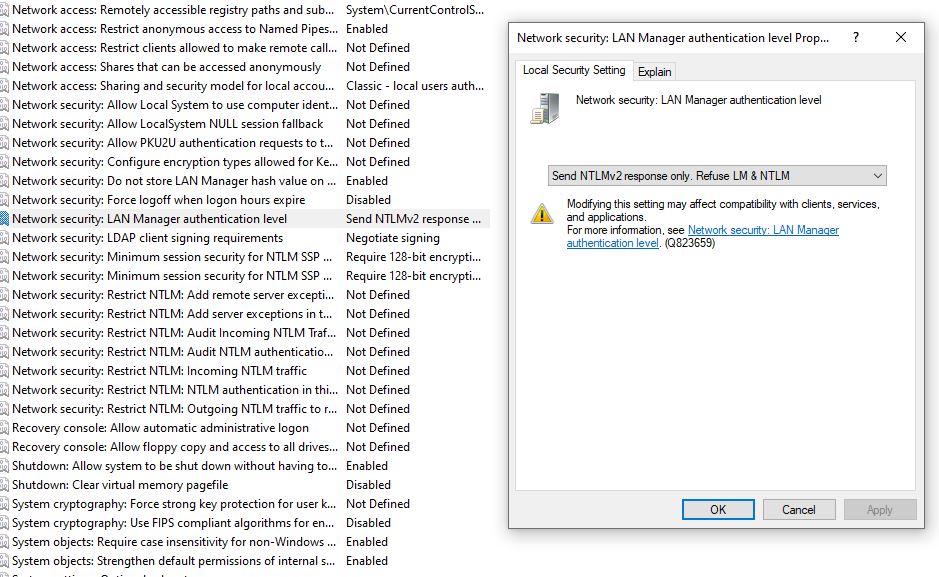
-
Same thing happened to me there, updating from 6.10.3 to 6.11 - no smb access to any of my exported shares, credential errors. I reverted back to 6.10.3 and all is good again.
-
Using cronguru, it seemed to me that "30 20 1 * *" appears to translate to the 1st of every month, whereas "30 20 * * *" translates to a trigger of half past eight pm every single day - or have I misunderstood?
-
@saarg many thanks for your help. I've edited and uploaded the file to the server now. I've changed the cron expression to "30 20 1 * *" which I believe is the first of every month. Hopefully that'll sort things not autorenewing


