MAM59
Members
-
Joined
-
Last visited
-
Zwischenbericht nach 3 Tagen (ohne Startupgruppen): Platte 4 geht immer noch ordnungsgemäß in Standby :-) Warten wir nochmal 3 Tage, dann kann man wohl mit an Sicherheit grenzender Wahrscheinlichkeit sagen, dass der Bug irgendwo in den Startupgruppen liegt...
-
Basically you have two configs that are fighting constantly who will be honored first. ETH0 and tailscale. both claim the rights to modify /etc/resolv.conf, so dnsmasq restarts every minute. turn off tailscale (for whatever it is good for???) and you should be done with the problem.
-
Ach DU warst das !!!🤣 (Scherz) Na ja, mit dem Alter schwinden Augen und Ohren, deshalb spar ich mir Atmos, die 5.1 Anlage ist abgeschaltet, ne schnöde Soundbar reicht nun. Die Nachbarn (nächstes Haus) haben die 2*300W Sinus Subwoofer nicht vermisst :-) Die Boxen hängen zwar noch im Wohnzimmer unter der Decke und in den Ecken, aber sind nicht mehr angeschlossen. Und "scharf" war eh gestern, meine Augen sehen keinen Unterschied zwischen 2k und 4k mehr. Also hab ich pragmatisch abgerüstet.
-
Na ja, Jellyfin streamt und hat die lokale Kontrolle über die benutzten Daten. Mein Kodi ist autonom und greift über SMB auf die einzelnen Shares zu. Ich bin kein Freund von Streaming, erstmal leidet die Qualität u.U. dramatisch, zweitens wird reichlich Energie beim Encoden verbraten. Ich encode einmal in ein geräteübergreifendes "MAM-Format" (*) (das sich im Laufe der Jahre schon mal ändern kann), welches ALLE Player abspielen können. Somit kein Bedarf an dauerndem Umkodieren. (Ausserdem ist der Platzbedarf um den Faktor 2-3 geringer :-) ) Nur vierstellig? Du Glücklicher :-) ich bin bei Filmen 5 stellig, bei Serienepisoden schon fast im 6 stelligen Bereich... Eben "70 Jahre Jäger & Sammler" :-) (*) = derzeit 1920x1080x25 H265 mit Dolby Digital 5.1 oder AAC Stereo. Ausnahmen sind in 4k, ältere HD Filme in 720p (werden ausgetauscht mit der Zeit), ein paar SD Leichen finden sich bestimmt auch noch irgendwo, aber wenn entdeckt, wird getauscht
-
Na ja, da sind verteilt Filme, Serien, Actor Pics usw drauf. Es ist etwas nervig, wenn man im Mediaplayer (Kodi) rumscrollt und dauernd bleibt er hängen, weil die jeweilige Platte erst hochfahren muß. Besonders die Akzeptanz von FRAUEN leidet darunter enorm. Also, alle auf einmal anwerfen, FRAU erziehen zu "beim Start kann es zu einer Pause von bis zu 30s kommen" und RUHE haben :-)
-
ich auch, wobei es nun deutlich schwieriger ist, das Problem zu erkennen, da man ja nie sagen kann, wann eine Platte im Schlafmodus sein sollte. Das fiel nur auf mit der Spinup Gruppe, da alle aus waren, nur die nicht.
-
Hmm, gute Frage, ich kann die Gruppe ja mal löschen und rebooten... dann dauerts wieder ein paar Tage und wir werden sehen. Oder soll ich den jetzigen Zustand erstmal beibehalten? Meine Hoffnung war ja, dass der fehlerhafte Status ein zufälliges Ereignis war und dass man dann später mit hdparm manuell (nach einmaligem Fehler probiert UNRAID es ja nie wieder) erzwingen kann. Aber, wie man sieht, trotz "OK" fährt die Platte nicht runter :-( Ist ja kein Beinbruch, im Notfall kann ich damit leben. Update: Dank fortgeschrittenem Alter ist die verbleibende Lebenszeit zu wichtig, um sie mit Warten zu verschwenden :-) Ich hab also die Startupgruppen deaktiviert und die Kiste neue gebootet (nun mit spindown auf 15min). Mal sehen, was passiert und wenn ja, wann...
-
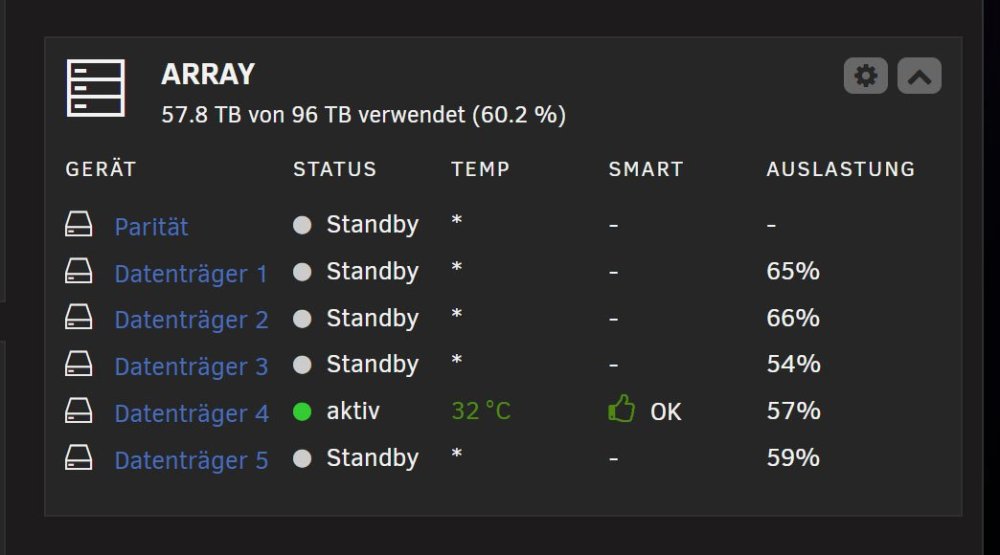
So, nach 5 Tagen war es wieder so weit, disk 4 "klemmt" :-( Here we are again, after 5 days the drive is "stuck" again :-( Ich hab versucht, die spindown befehle von Hand zu geben, sie werden alle kommentarlos akzeptiert, aber die Platte fährt nicht runter. I have tried the spindown commands manually. All return 0 exit status, the drive does not spindown. root@F:~# /usr/sbin/hdparm -C /dev/sdf /dev/sdf: drive state is: idle root@F:~# /usr/sbin/hdparm -y /dev/sdf /dev/sdf: issuing standby command root@F:~# echo $? 0 root@F:~# /usr/sbin/hdparm -C /dev/sdf /dev/sdf: drive state is: standby root@F:~# echo $? 0 root@F:~# /usr/sbin/hdparm -S0 /dev/sdf /dev/sdf: setting standby to 0 (off) root@F:~# echo $? 0 root@F:~# Was nun? What to do next?
-
After running it monthly for a year or so, I have set it to quarterly now since 3 yrs. No errors until now. Having 2 parity drives in an array is too much I think. Disk failures today are luckily unfrequent statistically so having one fallback drive is usually enough. Maybe if you have 20+ drives in your array, 2 parity drives would be a good idea though still not needed.
-
I don't like "AI assisted development" too, even it is hip these days. AI may help you to find certain functions or structures to use, but I never would let it write full code for me. It would take longer to check it than to write it myself. And I have seen a lot of "AI-generated-mistakes" already. So, if the community rules are "no AI", don't complain, just obey. (And yes, "30 years" is nothing, you youngster 🤣 I did not count really, but I guess, I am over 50yrs now already... or maybe a little less...)
-
Maybe a wrong descion, it will depend on my test soon to come (after the drive is locked again soon)
-
It is even more wierd. The disk "works" for some hours, even days obeying spinup and spindown commands. But suddenly it reports back status 1 (not supported). From then on, UNRAID does not even try anymore to spin it up or down. THAT is the main problem, it is locked until reboot. When it happens next time I will try manually the hdparm commands for spinning up and down and see, if status 1 keeps on, or if it was as wrong reading somehow.
-
Also ich bin nun etwas weiter: nach einem Reboot kann man die Platte 4 wieder "runterfahren" aber irgendwann kommt dann bei sdspin der returnwert 1 und ab da ist die Platte "blockiert" Es geht also ein paar Stunden/Tage gut, danach klemmt die Platte. Die Frage ist: "Was is returnwert 1 bei SDSPIN?" Fazit: sobald einmal 1 kam, wird die Platte nie wieder angefasst von sdspin. Das muss also irgendwo gespeichert werden bis zum Reboot Da SDSPIN nur ein Skript ist, war die Lösung einfach: "1" bedeutet "unterstützt wahrscheinlich kein standby". Das ist aber in diesem Falle ein Fehler. Ich warte mal ab, bis es wieder passiert, und probiere dann mit hdparms direkt. Vielleicht kommen da sinnvollere Hinweise bei heraus
-
Son Hexenwerk gibts hier nicht, alles schnödes SATA. Ach ja, ich sollte was anhängen, wobei, da findet sich kein Hinweis auf eine mögliche Ursache... Wobei, selbst wenn man manuell versucht, diese Platte runterzufahren, /dev/sdf taucht noch nichtmals in der Versuchsliste im Syslog auf :-( f-diagnostics-20260715-1803.zip Wobei, bei genauerer Durchsicht fällt mir folgende Zeile auf: Jul 8 12:00:22 F emhttpd: sdspin /dev/sdf up: 1 Vorher hat er noch sdf erfolgreich runtergefahren, danach irgendwann wieder hochgefahren, und als Ergebnis kam obiger Eintrag. Was immer das bedeuten mag (für andere Laufwerke finde ich solche Zeilen nicht)
-
Mein Problem existiert schon ewig, aber bislang hat niemand eine sinnvolle Idee geschweige denn Abhilfe geschaffen :-( Also starten wir nochmal einen Versuch: alle Array Platten sind in der Startup Gruppe "Array" mit einem Timeout von 30min. Nach 30min Inaktivität fahren auch alle brav herunter und sparen Strom. Alle? Nein, EINE Platte bleibt standhaft und läuft weiter: Aus unerfindlichen Gründen mag Platte 4 nicht schlafen gehen, auch von Hand kann man sie nicht dazu bewegen. Ja, ich weis, "da wird irgendein Task eine Datei blockieren", die Standardantwort. Aber, da ist nix besonderes drauf: Und "Openfiles" zeigt auch nichts auf Disk4 Egal was ich mache, Disk4 bleibt immer an :-( SNIEF! (wenn man die Startdup Gruppen deaktiviert, KANN man Disk4 runterfahren !) Also, da ist echt der Wurm drin, wo ist der Siegfried, der diesem Lindwurm den Garaus macht???