




prytzen
Members
-
Joined
-
Last visited
Everything posted by prytzen
-
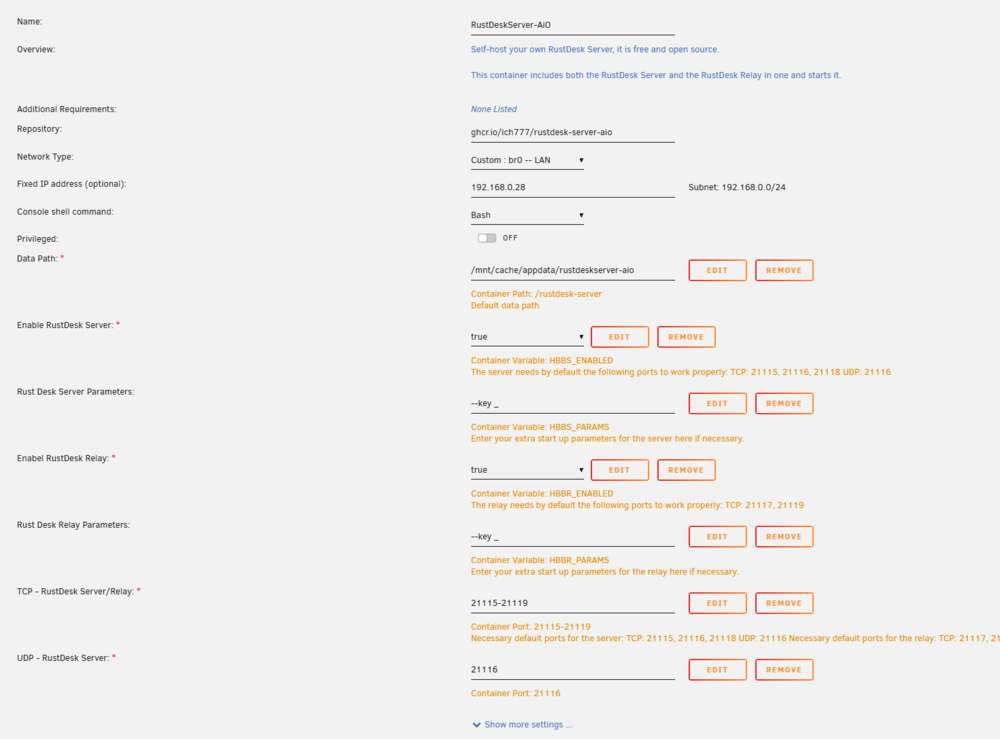
I believe i understand what you are saying. looking at my RustDesk container, it shows that there are Ports defined in the template, but nothing shows up on the Docker page. So I still think something is up and not displaying correctly. I do ultimately need to update to v7 so I can guess I can attempt that and see if the behavior changes at all.

-
Thanks. I believe i understand this portion of it. I have all of my Dockers setup with BR0 so I can keep them exposed on a specific VLAN and they have their own IP address. The port mappings are just 1:1 at that point, so nothing changes. The issue, and maybe I didn't make that clear, was that there is just no information showing up on the page about the IP address or port as my other docker containers do, like below

-
I have quite a few dockers and run them with a Bridge interface. Most of them are just fine, but recently - and i dont know why - when i add a container and put it on the bridge network, the port mappings just shows blank. The docker is still functioning fine and i can reach it on my assigned IP address, but i do not see the port mappings on the Docker page.

-
I am utilizing the nzbget docker and am having some issues. Until recently everything was working fine, but now for some reason I cannot get my downloaders to talk to nzbget nor can I get the web interface to come up. I have verified the logs and everything looks ok to me, I don't see any errors in fact I see everything saying it is fine. What am I missing and what do I need to do to get this back in a functioning state. The latest log is below - I have redacted some information. Created by... ___. .__ .__ \_ |__ |__| ____ | |__ ____ ___ ___ | __ \| |/ \| | \_/ __ \\ \/ / | \_\ \ | | \ Y \ ___/ > < |___ /__|___| /___| /\___ >__/\_ \ \/ \/ \/ \/ \/ https://hub.docker.com/u/binhex/ 2024-09-24 08:52:46.966377 [info] Host is running unRAID 2024-09-24 08:52:46.979750 [info] System information Linux e1c8900cdf73 6.1.64-Unraid #1 SMP PREEMPT_DYNAMIC Wed Nov 29 12:48:16 PST 2023 x86_64 GNU/Linux 2024-09-24 08:52:47.008022 [info] OS_ARCH defined as 'x86-64' 2024-09-24 08:52:47.025277 [warn] PUID not defined (via -e PUID), defaulting to '99' 2024-09-24 08:52:48.959272 [warn] PGID not defined (via -e PGID), defaulting to '100' 2024-09-24 08:52:50.828624 [warn] UMASK not defined (via -e UMASK), defaulting to '000' 2024-09-24 08:52:50.844165 [info] Permissions already set for '/config' 2024-09-24 08:52:50.876647 [info] Deleting files in /tmp (non recursive)... 2024-09-24 08:52:50.898736 [info] VPN_ENABLED defined as 'yes' 2024-09-24 08:52:50.915896 [warn] VPN_CLIENT not defined (via -e VPN_CLIENT), defaulting to 'openvpn' 2024-09-24 08:52:50.931601 [info] VPN_PROV defined as 'pia' 2024-09-24 08:52:51.564830 [info] OpenVPN config file (ovpn extension) is located at /config/openvpn/mexico.ovpn 2024-09-24 08:52:51.617485 [info] VPN remote server(s) defined as 'mexico.privacy.network,' 2024-09-24 08:52:51.632153 [info] VPN remote port(s) defined as '1198,' 2024-09-24 08:52:51.646987 [info] VPN remote protcol(s) defined as 'udp,' 2024-09-24 08:52:51.663793 [info] VPN_DEVICE_TYPE defined as 'tun0' 2024-09-24 08:52:51.681479 [info] VPN_OPTIONS not defined (via -e VPN_OPTIONS) 2024-09-24 08:52:51.697934 [info] LAN_NETWORK defined as '192.168.0.0/24' 2024-09-24 08:52:51.714384 [info] NAME_SERVERS defined as '8.8.8.8,1.1.1.1' 2024-09-24 08:52:51.731640 [info] VPN_USER defined as '**********' 2024-09-24 08:52:51.747720 [info] VPN_PASS defined as '**********' 2024-09-24 08:52:51.764920 [warn] STRICT_PORT_FORWARD not defined (via -e STRICT_PORT_FORWARD), defaulting to 'yes' 2024-09-24 08:52:51.782292 [warn] ENABLE_PRIVOXY not defined (via -e ENABLE_PRIVOXY), defaulting to 'no' 2024-09-24 08:52:51.801546 [info] VPN_INPUT_PORTS not defined (via -e VPN_INPUT_PORTS), skipping allow for custom incoming ports 2024-09-24 08:52:51.819028 [info] VPN_OUTPUT_PORTS not defined (via -e VPN_OUTPUT_PORTS), skipping allow for custom outgoing ports 2024-09-24 08:52:51.837899 [info] Starting Supervisor... 2024-09-24 08:52:52,140 INFO Included extra file "/etc/supervisor/conf.d/nzbget.conf" during parsing 2024-09-24 08:52:52,140 INFO Set uid to user 0 succeeded 2024-09-24 08:52:52,141 INFO supervisord started with pid 7 2024-09-24 08:52:53,144 INFO spawned: 'shutdown-script' with pid 180 2024-09-24 08:52:53,145 INFO spawned: 'start-script' with pid 181 2024-09-24 08:52:53,146 INFO spawned: 'watchdog-script' with pid 182 2024-09-24 08:52:53,147 INFO reaped unknown pid 8 (exit status 0) 2024-09-24 08:52:53,150 DEBG 'start-script' stdout output: [info] VPN is enabled, beginning configuration of VPN 2024-09-24 08:52:53,150 INFO success: shutdown-script entered RUNNING state, process has stayed up for > than 0 seconds (startsecs) 2024-09-24 08:52:53,150 INFO success: start-script entered RUNNING state, process has stayed up for > than 0 seconds (startsecs) 2024-09-24 08:52:53,151 INFO success: watchdog-script entered RUNNING state, process has stayed up for > than 0 seconds (startsecs) 2024-09-24 08:52:53,193 DEBG 'start-script' stdout output: [info] Adding 8.8.8.8 to /etc/resolv.conf 2024-09-24 08:52:53,196 DEBG 'start-script' stdout output: [info] Adding 1.1.1.1 to /etc/resolv.conf 2024-09-24 08:52:53,368 DEBG 'start-script' stdout output: [info] Default route for container is 192.168.0.254 2024-09-24 08:52:53,378 DEBG 'start-script' stdout output: [info] Docker network defined as 192.168.0.0/24 2024-09-24 08:52:53,381 DEBG 'start-script' stdout output: [info] Adding 192.168.0.0/24 as route via docker eth0 2024-09-24 08:52:53,382 DEBG 'start-script' stderr output: RTNETLINK answers: File exists 2024-09-24 08:52:53,382 DEBG 'start-script' stdout output: [info] ip route defined as follows... -------------------- 2024-09-24 08:52:53,382 DEBG 'start-script' stdout output: default via 192.168.0.254 dev eth0 192.168.0.0/24 dev eth0 proto kernel scope link src 192.168.0.13 2024-09-24 08:52:53,383 DEBG 'start-script' stdout output: -------------------- 2024-09-24 08:52:53,386 DEBG 'start-script' stdout output: iptable_mangle 16384 1 ip_tables 28672 3 iptable_filter,iptable_nat,iptable_mangle x_tables 45056 16 ip6table_filter,xt_conntrack,iptable_filter,ip6table_nat,xt_tcpudp,xt_addrtype,xt_CHECKSUM,xt_nat,ip6_tables,ipt_REJECT,ip_tables,iptable_nat,ip6table_mangle,xt_MASQUERADE,iptable_mangle,xt_mark 2024-09-24 08:52:53,386 DEBG 'start-script' stdout output: [info] iptable_mangle support detected, adding fwmark for tables 2024-09-24 08:52:53,516 DEBG 'start-script' stdout output: [info] iptables defined as follows... -------------------- 2024-09-24 08:52:53,517 DEBG 'start-script' stdout output: -P INPUT DROP -P FORWARD DROP -P OUTPUT DROP -A INPUT -s 192.168.0.0/24 -d 192.168.0.0/24 -j ACCEPT -A INPUT -i eth0 -p tcp -m tcp --sport 1198 -j ACCEPT -A INPUT -i eth0 -p udp -m udp --sport 1198 -j ACCEPT -A INPUT -i eth0 -p tcp -m tcp --dport 6789 -j ACCEPT -A INPUT -i eth0 -p tcp -m tcp --sport 6789 -j ACCEPT -A INPUT -p icmp -m icmp --icmp-type 0 -j ACCEPT -A INPUT -i lo -j ACCEPT -A INPUT -i tun0 -j ACCEPT -A OUTPUT -s 192.168.0.0/24 -d 192.168.0.0/24 -j ACCEPT -A OUTPUT -o eth0 -p tcp -m tcp --dport 1198 -j ACCEPT -A OUTPUT -o eth0 -p udp -m udp --dport 1198 -j ACCEPT -A OUTPUT -o eth0 -p tcp -m tcp --dport 6789 -j ACCEPT -A OUTPUT -o eth0 -p tcp -m tcp --sport 6789 -j ACCEPT -A OUTPUT -p icmp -m icmp --icmp-type 8 -j ACCEPT -A OUTPUT -o lo -j ACCEPT -A OUTPUT -o tun0 -j ACCEPT 2024-09-24 08:52:53,518 DEBG 'start-script' stdout output: -------------------- 2024-09-24 08:52:53,519 DEBG 'start-script' stdout output: [info] Starting OpenVPN (non daemonised)... 2024-09-24 08:52:53,650 DEBG 'start-script' stdout output: 2024-09-24 08:52:53 DEPRECATED OPTION: --cipher set to 'aes-128-cbc' but missing in --data-ciphers (AES-256-GCM:AES-128-GCM). Future OpenVPN version will ignore --cipher for cipher negotiations. Add 'aes-128-cbc' to --data-ciphers or change --cipher 'aes-128-cbc' to --data-ciphers-fallback 'aes-128-cbc' to silence this warning. 2024-09-24 08:52:53,650 DEBG 'start-script' stdout output: 2024-09-24 08:52:53 WARNING: file 'credentials.conf' is group or others accessible 2024-09-24 08:52:53 OpenVPN 2.5.4 [git:makepkg/3f7a85b9aebe7be0+] x86_64-pc-linux-gnu [SSL (OpenSSL)] [LZO] [LZ4] [EPOLL] [PKCS11] [MH/PKTINFO] [AEAD] built on Oct 5 2021 2024-09-24 08:52:53 library versions: OpenSSL 1.1.1l 24 Aug 2021, LZO 2.10 2024-09-24 08:52:53,650 DEBG 'start-script' stdout output: 2024-09-24 08:52:53 NOTE: the current --script-security setting may allow this configuration to call user-defined scripts 2024-09-24 08:52:53,651 DEBG 'start-script' stdout output: 2024-09-24 08:52:53 CRL: loaded 1 CRLs from file -----BEGIN X509 CRL----- XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX -----END X509 CRL----- 2024-09-24 08:52:53,651 DEBG 'start-script' stdout output: 2024-09-24 08:52:53 TCP/UDP: Preserving recently used remote address: [AF_INET]*.*.*.89:1198 2024-09-24 08:52:53 UDP link local: (not bound) 2024-09-24 08:52:53 UDP link remote: [AF_INET]*.*.*.89:1198 2024-09-24 08:52:53,910 DEBG 'start-script' stdout output: 2024-09-24 08:52:53 [mexico408] Peer Connection Initiated with [AF_INET]*.*.*.89:1198 2024-09-24 08:52:53,980 DEBG 'start-script' stdout output: 2024-09-24 08:52:53 TUN/TAP device tun0 opened 2024-09-24 08:52:53 net_iface_mtu_set: mtu 1500 for tun0 2024-09-24 08:52:53 net_iface_up: set tun0 up 2024-09-24 08:52:53,981 DEBG 'start-script' stdout output: 2024-09-24 08:52:53 net_addr_v4_add: 10.14.112.45/24 dev tun0 2024-09-24 08:52:53 /root/openvpnup.sh tun0 1500 1553 10.14.112.45 255.255.255.0 init 2024-09-24 08:52:53,982 DEBG 'start-script' stdout output: 2024-09-24 08:52:53 Initialization Sequence Completed 2024-09-24 08:53:01,102 DEBG 'start-script' stdout output: [info] Attempting to get external IP using 'http://checkip.amazonaws.com'... 2024-09-24 08:53:01,428 DEBG 'start-script' stdout output: [info] Successfully retrieved external IP address *.*.*.89 2024-09-24 08:53:01,428 DEBG 'start-script' stdout output: [info] Script started to assign incoming port 2024-09-24 08:53:01,428 DEBG 'start-script' stdout output: [info] Port forwarding is enabled [info] Checking endpoint 'mexico.privacy.network' is port forward enabled... 2024-09-24 08:53:02,385 DEBG 'start-script' stdout output: [info] PIA endpoint 'mexico.privacy.network' is in the list of endpoints that support port forwarding 2024-09-24 08:53:02,385 DEBG 'start-script' stdout output: [info] List of PIA endpoints that support port forwarding:- 2024-09-24 08:53:02,386 DEBG 'start-script' stdout output: [info] ua.privacy.network [info] slovenia.privacy.network [info] za.privacy.network [info] mk.privacy.network [info] dz.privacy.network [info] mongolia.privacy.network [info] ca-montreal.privacy.network [info] morocco.privacy.network [info] sweden.privacy.network [info] saudiarabia.privacy.network [info] au-sydney.privacy.network [info] yerevan.privacy.network [info] aus-melbourne.privacy.network [info] au-adelaide-pf.privacy.network [info] es-valencia.privacy.network 2024-09-24 08:53:02,386 DEBG 'start-script' stdout output: [info] panama.privacy.network [info] malta.privacy.network [info] de-germany-so.privacy.network [info] sweden-2.privacy.network [info] ae.privacy.network [info] ca-vancouver.privacy.network [info] aus-perth.privacy.network [info] sg.privacy.network [info] japan.privacy.network [info] ca-toronto.privacy.network [info] br.privacy.network [info] ireland.privacy.network [info] italy-2.privacy.network [info] man.privacy.network [info] brussels.privacy.network [info] lt.privacy.network [info] uk-2.privacy.network [info] uk-southampton.privacy.network [info] sofia.privacy.network [info] santiago.privacy.network [info] al.privacy.network [info] france.privacy.network [info] gt-guatemala-pf.privacy.network [info] pt.privacy.network [info] montenegro.privacy.network [info] ar.privacy.network [info] israel.privacy.network [info] ro.privacy.network [info] taiwan.privacy.network [info] vietnam.privacy.network [info] kualalumpur.privacy.network [info] swiss.privacy.network [info] kazakhstan.privacy.network [info] de-frankfurt.privacy.network [info] fi.privacy.network [info] jakarta.privacy.network [info] uy-uruguay-pf.privacy.network [info] hk.privacy.network 2024-09-24 08:53:02,386 DEBG 'start-script' stdout output: [info] ad.privacy.network [info] ca-ontario.privacy.network [info] qatar.privacy.network [info] poland.privacy.network [info] liechtenstein.privacy.network [info] mexico.privacy.network [info] italy.privacy.network [info] ba.privacy.network [info] kr-south-korea-pf.privacy.network [info] au-australia-so.privacy.network [info] georgia.privacy.network [info] bahamas.privacy.network [info] spain.privacy.network [info] egypt.privacy.network [info] de-berlin.privacy.network [info] bangladesh.privacy.network [info] no.privacy.network [info] srilanka.privacy.network [info] denmark.privacy.network [info] au-brisbane-pf.privacy.network [info] gr.privacy.network [info] greenland.privacy.network [info] fi-2.privacy.network [info] macau.privacy.network [info] sk.privacy.network [info] venezuela.privacy.network [info] nl-netherlands-so.privacy.network [info] ca-ontario-so.privacy.network [info] cyprus.privacy.network [info] cambodia.privacy.network [info] ee.privacy.network [info] philippines.privacy.network [info] is.privacy.network [info] sanjose.privacy.network [info] bo-bolivia-pf.privacy.network 2024-09-24 08:53:02,386 DEBG 'start-script' stdout output: [info] np-nepal-pf.privacy.network [info] japan-2.privacy.network [info] uk-manchester.privacy.network [info] hungary.privacy.network [info] ec-ecuador-pf.privacy.network [info] rs.privacy.network [info] denmark-2.privacy.network [info] china.privacy.network [info] bogota.privacy.network [info] tr.privacy.network [info] uk-london.privacy.network [info] austria.privacy.network [info] nigeria.privacy.network [info] in.privacy.network [info] nz.privacy.network [info] lv.privacy.network [info] pe-peru-pf.privacy.network [info] monaco.privacy.network [info] zagreb.privacy.network [info] nl-amsterdam.privacy.network [info] lu.privacy.network [info] czech.privacy.network [info] md.privacy.network 2024-09-24 08:53:04,783 DEBG 'start-script' stdout output: [info] Successfully assigned and bound incoming port '27425' 2024-09-24 08:53:05,194 DEBG 'watchdog-script' stdout output: [info] nzbget not running 2024-09-24 08:53:05,195 DEBG 'watchdog-script' stdout output: [info] Nzbget config file already exists, skipping copy 2024-09-24 08:53:05,215 DEBG 'watchdog-script' stdout output: [info] Attempting to start nzbget... 2024-09-24 08:53:05,276 DEBG 'watchdog-script' stdout output: [info] Nzbget process started [info] Waiting for Nzbget process to start listening on port 6789... 2024-09-24 08:53:05,279 DEBG 'watchdog-script' stdout output: [info] Nzbget process is listening on port 6789
-
So it appears that my ISP is to blame. There were some changes around that April timeline and it appears they are now blocking Port 80 inbound on residential connections (oddly everything else they seem to be fine with). But that means that i cannot use HTTP as the method of certificate authentication. I use Dreamhost as my registrar and hosting platform. Is there a way to use DNS as the authentication? I know that they have an API, but am not sure how to make it work with the SWAG container.
-
I am having issues with my SWAG install and it not updating certificates. Seems as though the last time it updated was back in April some time and has failed ever since. It was working fine before then and i cannot find anything that has changed. The errors that it keeps throwing are about timeouts and port 80 not being available, but i have verified that i am forwarding Port 80 to the container like always. I have a Unifi Security Gateway Pro and have forwarded port 80 on the outside to the appropriate IP address and port 80 on the inside (the IP and Port of the SWAG container). This automatically sets up a firewall rule allowing that traffic, but for some reason either this is not working, or the container is not responding to those HTTP requests. Any Ideas? Certbot output (anonymized domain and IP address) - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - Processing /etc/letsencrypt/renewal/plex.domain.tld.conf - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - Renewing an existing certificate for plex.domain.tld and 4 more domains Certbot failed to authenticate some domains (authenticator: standalone). The Certificate Authority reported these problems: Domain: homeassistant.domain.tld Type: connection Detail: aa.bb.cc.dd: Fetching http://homeassistant.domain.tld/.well-known/acme-challenge/yh5SakI-iluZRukPZrhi7DAzwPVnN09r6q-S4OwIO7c: Timeout during connect (likely firewall problem) Domain: nextcloud.domain.tld Type: connection Detail: aa.bb.cc.dd: Fetching http://nextcloud.domain.tld/.well-known/acme-challenge/kq8c_9WqjEfhmmixjCJnMLShXxp1I21T42Nv3Sou1gM: Timeout during connect (likely firewall problem) Domain: ombi.domain.tld Type: connection Detail: aa.bb.cc.dd: Fetching http://ombi.domain.tld/.well-known/acme-challenge/cOCO5wmZM8N-WcLYwUjUjvDJh2cGbMh66s2VePAJ0fs: Timeout during connect (likely firewall problem) Domain: plex.domain.tld Type: connection Detail: aa.bb.cc.dd: Fetching http://plex.domain.tld/.well-known/acme-challenge/a8xsYJhw1CRGMyUwPhDQ4opxJRXr4AfGvbm2vqmHhC8: Timeout during connect (likely firewall problem) Domain: unifi.domain.tld Type: connection Detail: aa.bb.cc.dd: Fetching http://unifi.domain.tld/.well-known/acme-challenge/jU2jB7sLax3NxOcVBHdygQ1f-PJLWH1UJjXvKSq7KbM: Timeout during connect (likely firewall problem) Hint: The Certificate Authority failed to download the challenge files from the temporary standalone webserver started by Certbot on port 80. Ensure that the listed domains point to this machine and that it can accept inbound connections from the internet. Failed to renew certificate plex.domain.tld with error: Some challenges have failed. - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - All renewals failed. The following certificates could not be renewed: /etc/letsencrypt/live/plex.domain.tld/fullchain.pem (failure) - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - 1 renew failure(s), 0 parse failure(s) Ask for help or search for solutions at https://community.letsencrypt.org. See the logfile /var/log/letsencrypt/letsencrypt.log or re-run Certbot with -v for more details.
-
I had to rebuild my boot disk and replace my CACHE drive and am trying to get things back working again. thankfully i have a backup of my appdata with CA BAckup/Restore, but i guess i am not using it right. I have Restored the backup, but none of my docker containers show under the docker tab. what am i doing wrong or what am i missing?



