




gusgus
Members
-
Joined
-
Last visited
-
Hi I'm having a problem with SSL certs, on Firefox I'm getting SSL_ERROR_INTERNAL_ERROR_ALERT (with Chrome it's a ERR_SSL_PROTOCOL_ERROR) when navigating to my proxy host. Below are the setup steps I followed along with the troubleshooting I did. Short of testing the SSL cert on a webserver to verify that it is intact (please let me know if I should attempt this), I'm out of ideas. Any help is greatly appreciated. The setup steps I followed: Setup a subdomain haos.mydomain.com to redirect to my top-level domain, mydomain.com Verify that mydomain.com is currently pointed to my dynamic IP (via dynamic DNS). Follow this tutorial to setup NPM-Official, which is basically: https://www.youtube.com/watch?v=nhacNUxVcy4 Install NPM-Official container. Choose to have a fixed IP address. Forwarded ports 80 and 443 from my router to the NPM-Official IP address. Verify that I can access the NPM-Official welcome screen when navigating to http://myipaddress Setup mydomain.com and *.mydomain.com SSL Certs in the NPM webUI. I deviated from the tutorial by enabling DNS Challenge to allow wildcard cert generation. Create a Proxy Host. It's pointed to my HA OS virtual machine, so http and port 8123. It uses the *.mydomain.com SSL cert. Now I should be able to type in haos.mydomain.com via http or https and see the HA OS interface. But instead, what I see with http is 502 bad gateway, and with https SSL_ERROR_INTERNAL_ERROR_ALERT on Firefox and with Chrome it's a ERR_SSL_PROTOCOL_ERROR. Troubleshooting: nslookup says haos.mydomain.com is correctly pointed to my external IP address manually navigating to the HA OS IP address successfully shows me the HA web interface as expected NPM-Official log shows successful cert generation when I click on Renew: [7/5/2025] [8:40:19 PM] [SSL ] › info - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - Processing /etc/letsencrypt/renewal/npm-2.conf - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - Renewing an existing certificate for *.mydomain.com and mydomain.com - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - Congratulations, all renewals succeeded: /etc/letsencrypt/live/npm-2/fullchain.pem (success) - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - [7/5/2025] [8:40:19 PM] [Global ] › ⬤ debug CMD: openssl x509 -in /etc/letsencrypt/live/npm-2/fullchain.pem -subject -noout [7/5/2025] [8:40:19 PM] [Global ] › ⬤ debug CMD: openssl x509 -in /etc/letsencrypt/live/npm-2/fullchain.pem -issuer -noout [7/5/2025] [8:40:19 PM] [Global ] › ⬤ debug CMD: openssl x509 -in /etc/letsencrypt/live/npm-2/fullchain.pem -dates -noout
-
Yes this was it, I didn't configure the shares correctly! For future readers, the solution is: 1. Go to Shares tab 2. Click on each share and choose Array or Cache to indicate where they should reside. 3. Once done, go to Main, scroll to the bottom, and click on Move. The folders will move between /mnt/disk1 and /mnt/cache but will universally be available at /mnt/user no matter where they are.
-
I'm currently trying to move the data myself with rsync: rsync -rltgoDhUHX --remove-source-files --info=progress2 --verbose /mnt/cache/ /mnt/disk1/
-
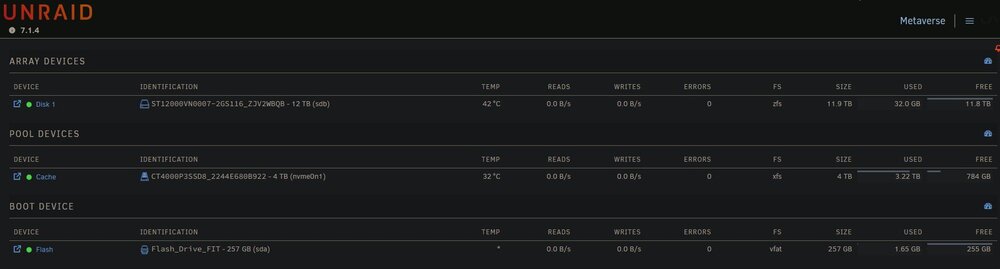
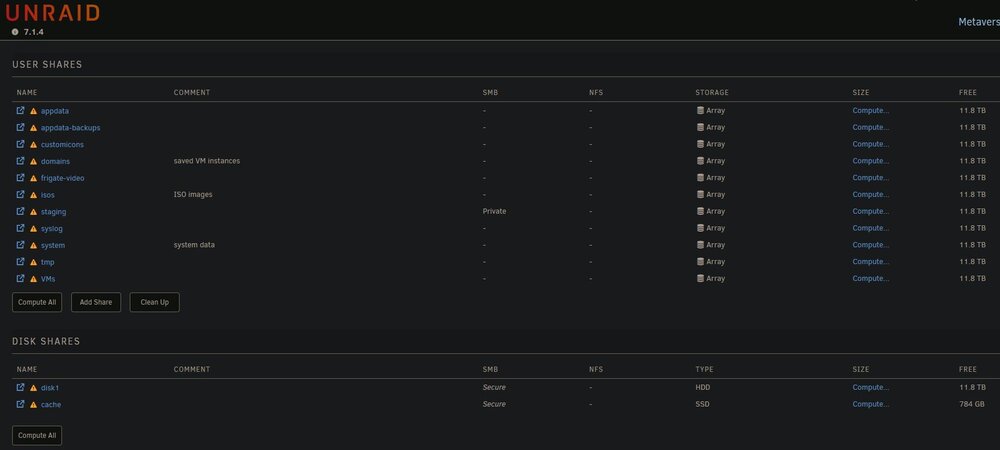
I've read all the posts I can find about mover not moving from Cache (pool) to Array, none helped. I have Cache as a SSD Pool and Array as 1 HDD. I'm trying to move all of my data from Cache to Array so I can reformat the Cache as zfs (taking advantage of a lull in user demand). However it moved only 32 GB (the ISOs user share) of the 3.22 TB of data and then stopped. VM and Docker services are both disabled. I have invoked manual Move (Main > Move button) 3 time since but no change. All shares in User Shares are set to Array (high-water). I've attached screenshots of Shares and Main screens and the diagnostics file. What possible problems could crop up if I move these shares myself via command line? Is it possible that the manual mover isn't doing anything because the move schedule is for 3:30 am and it's currently daytime? I didn't see anything about this in known issues for 7.1.x. The array drive has some SMART errors - Unraid doesn't have logic that prevents the mover from moving to a drive with SMART errors right? This is a calculated risk and have made this decision based on how much I care about the data. I'll be replacing the Array drive soon enough. metaverse-diagnostics-20250621-0924.zip
-
I upgraded from 6.12.10 to 6.12.14 when it was released some time ago. For the first time since then, I'm trying to ssh into the box and can't authenticate using publickey method, which is the method that I have been using for years from multiple clients, and now it won't work from any client. It appears that sshd is ignoring my /root/.ssh/authorized_keys file. My keys are both present and correct in both /root/.ssh/authorized_keys and /boot/config/ssh/authorized_keys. The usual location for sshd auth.log does not appear to be present. Any ideas before I blow this system away and reinstall? Permissions of my /root/.ssh/authorized_keys file: root@box:~# ls -al /root/.ssh/authorized_keys -rw------- 1 root root 332 Jan 26 09:38 /root/.ssh/authorized_keys Permissions of my sshd_config file: root@box:~# ls -al /etc/ssh/sshd_config -rw------- 1 root root 1522 Feb 3 07:37 /etc/ssh/sshd_config Contents of my /etc/ssh/sshd_config file, which are the same contents as my /boot/config/ssh/sshd_config file, note that I only have password as an AuthenticationMethods entry for troubleshooting, normally this is publickey only: # Supported HostKey algorithms by order of preference. HostKey /etc/ssh/ssh_host_ed25519_key HostKey /etc/ssh/ssh_host_rsa_key HostKey /etc/ssh/ssh_host_ecdsa_key KexAlgorithms [email protected],ecdh-sha2-nistp521,ecdh-sha2-nistp384,ecdh-sha2-nistp256,diffie-hellman-group-exchange-sha256 Ciphers [email protected],[email protected],[email protected],aes256-ctr,aes192-ctr,aes128-ctr MACs [email protected],[email protected],[email protected],hmac-sha2-512,hmac-sha2-256,[email protected] # Password based logins are disabled - only public key based logins are allowed. AuthenticationMethods publickey password # LogLevel VERBOSE logs user's key fingerprint on login. Needed to have a clear audit track of which key was using to log in. LogLevel VERBOSE # Log sftp level file access (read/write/etc.) that would not be easily logged otherwise. Subsystem sftp /usr/lib/ssh/sftp-server -f AUTHPRIV -l INFO # Root login is not allowed for auditing reasons. This is because it's difficult to track which process belongs to which root user: # # On Linux, user sessions are tracking using a kernel-side session id, however, this session id is not recorded by OpenSSH. # Additionally, only tools such as systemd and auditd record the process session id. # On other OSes, the user session id is not necessarily recorded at all kernel-side. # Using regular users in combination with /bin/su or /usr/bin/sudo ensure a clear audit track. PermitRootLogin Yes
-
Solved. All this time I assumed that the OOM error was not actually unRAID running out of memory, because I miscalculated the amount of RAM that should be allocated to each VM to prevent an OOM condition. I reset the memory allocation for each VM (correctly this time) and the system no longer crashes.
-
Additional info: I found in the VM logs the following line at the time of each crash (with different timestamps of course): 2024-03-24 17:41:47.443+0000: shutting down, reason=crashed So it would appear that qemu recognizes a problem and recovers long enough to write to the log. This is the only line after each crash.
-
Hello all I am getting reproducible out of memory crashes under very specific circumstances, and it appears to be triggered by one VM. I've not run into this on a KVM system before so I'm not sure what to do. Details below, any help is appreciated. I'd be happy to provide further troubleshooting information if anyone could provide a little guidance. EDIT: I have not tried doing this on another VM which I could do if you think it's useful. I expect that this is a problem with unRAID, not a VM. System Setup Hardware specs Dell Optiplex 5080 32 GB RAM Network settings All VMs have network source set to br0 Only one NIC port is a member of br0 All other NIC ports are unused and not a member of br0 (no bonding) Plugins installed Community Applications Fix Common Problems GPU Statistics docker.patch2 Intel GPU TOP Intel GVT-g iSCSI Initiator Nvidia Driver Unassigned Devices Unassigned Devices Plus Unassigned Devices Preclear Offending VM build OS: Linux Mint 20.3 xfce Memory assignment: 20 GB See the attached XML file "OffendingVM.xml" for the VM configuration. This is after the below (minor) changes were made. How the problem has manifested and what I tried I first noticed that the problem appeared to happen during high network usage, what would happen is I would try to copy a 70 GB file from remote SMB share to the local storage and it would crash about 3.5 GB in. I changed the Network Model for the VM from e1000 to virtio. No change in crash behavior. The crash had the following characteristics: VM immediately dropped my SSH connections and would no longer respond to connection attempts unRAID webUI was completely unresponsive and my web browser acted as if the website was down unRAID LAN interface IP address responded correctly to pings as if there was no issue unRAID physical console appeared to work correctly and gave no indication of a problem unRAID behaved normally again after a reboot via either the physical button or the physical console I changed the Network Model for the VM from virtio to virtio-net after reading that virtio-net is most stable. No change in crash behavior. I suspected an issue with the onboard 1 Gb NIC or its driver so I replaced it with a Intel X550 10 Gb PCIe card. A change in crash behavior here. After the swap I was able to copy the file as fast as the remote SMB server could manage (140-500 MBps) without triggering a crash. Now being able to copy files over the network at full speed without a crash, I moved on to computing sha512sum hashes using the linux command "sha512sum". This is a single threaded workload. After 1-2 minutes of this the following happened. Now my working theory is that the NIC swap improved the issue because the new NIC offloads calculations differently, and this was a OOM issue all along. VM dropped my SSH connections unRAID webUI became unresponsive 5-10 minutes later, the webUI suddenly became responsive again. I was able to see that the VM had been shut down. I got a notification from the Fix Common Problems plugin of "Out Of Memory errors detected on your server" It's worth noting that I was running htop in a SSH window from the VM at the time of the crash. htop clearly shows that the sha512sum command became a dead process (it had not finished executing) right before the crash and the memory usage of the VM was no more than 280 MB of 19.5 GB. metaverse-diagnostics-20240324-1101.zip OffendingVM.xml
-
Please also add how to recover from a working VM booting into EFI Interactive Shell, and the EFI shell not listing the VM disk as a boot device (via map -r). One solution is here, not sure if there are multiple solutions to be listed:


