




nationapn
Members
-
Joined
-
Last visited
-
@Tolete - thank you SO MUCH for these instructions. They were super helpful. This worked to update the row formats to DYNAMIC on all but one of my nextcloud tables. However, I received the following error on the table oc_filecache: MariaDB [nextcloud]> ALTER TABLE oc_filecache ROW_FORMAT=DYNAMIC; ERROR 1062 (23000): Duplicate entry '1-1bcb3b48154a5423ee962e961cdf6af9' for key 'fs_storage_path_hash' Any chance you know how I can fix this? Apologies, I'm a novice in SQL. @Tolete - thank you SO MUCH for these instructions. They were super helpful. This worked to update the row formats to DYNAMIC on all but one of my nextcloud tables. However, I received the following error on the table oc_filecache: MariaDB [nextcloud]> ALTER TABLE oc_filecache ROW_FORMAT=DYNAMIC; ERROR 1062 (23000): Duplicate entry '1-1bcb3b48154a5423ee962e961cdf6af9' for key 'fs_storage_path_hash' Any chance you know how I can fix this? Apologies, I'm a novice in SQL.
-
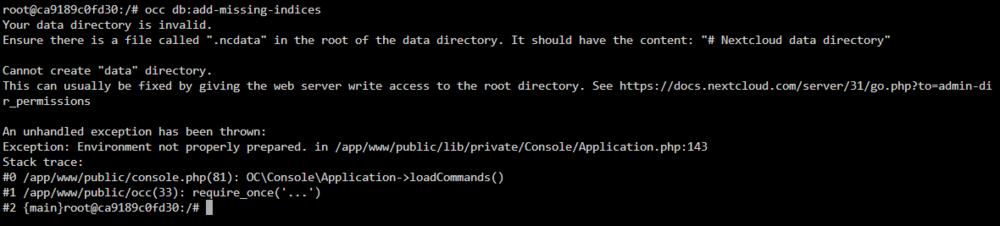
Seeking help updating my nextcloud database…I am trying to run occ commands to add missing indices and run maintenance repairs, but I can’t seem to run occ commands due to another error referring to a missing .ncdata file in my directory. Attached are screenshots of my nextcloud install errors and the console occ error. Thank you so much for any insights/solutions!

-
Perhaps someone can help me with a weird issue I am having with Ombi. I have it set up with a reverse proxy using LetsEncrypt (now Swag), and it works perfectly via the web or organizrr. The issue I am having has to do with the Ombi iPhone app. On a fresh start of the Ombi docker, the app works as advertised. However, after some period of time (maybe a few hours), the app has an issue with requesting content (takes a while, then gives a “The request timed out” message. The only way I can get it to work again is to restart the Ombi docker. Of course, my workaround is to run a user script that restarts the Ombi docker periodically, but this is a band-aid until I can actually solve the issue. Here is my Swag config: # first go into ombi settings, under the menu "Ombi" set the base url to /ombi and restart the ombi container location /ombi { return 301 $scheme://$host/ombi/; } location ^~ /ombi/ { # enable the next two lines for http auth #auth_basic "Restricted"; #auth_basic_user_file /config/nginx/.htpasswd; # enable the next two lines for ldap auth, also customize and enable ldap.conf in the default conf #auth_request /auth; #error_page 401 =200 /login; include /config/nginx/proxy.conf; resolver 127.0.0.11 valid=30s; set $upstream_ombi ombi; proxy_pass http://$upstream_ombi:3579; } # This allows access to the actual api location ^~ /ombi/api { include /config/nginx/proxy.conf; resolver 127.0.0.11 valid=30s; set $upstream_ombi ombi; proxy_pass http://$upstream_ombi:3579; } if ($http_referer ~* /ombi) { rewrite ^/api/(.*) /ombi/api/$1? redirect; } # This allows access to the documentation for the api location ^~ /ombi/swagger { include /config/nginx/proxy.conf; resolver 127.0.0.11 valid=30s; set $upstream_ombi ombi; proxy_pass http://$upstream_ombi:3579; } if ($http_referer ~* /ombi) { rewrite ^/swagger/(.*) /ombi/swagger/$1? redirect; } Appreciate any help/insight! Having to restart the docker really defeats the purpose of having the iPhone app for convenience...and hopefully this can help solve the problem for anyone else with this experience.

