




hansolo77
Members
-
Joined
-
Last visited
Everything posted by hansolo77
-
My plugin has been working for a couple of years, but recently it's not been working right. I haven't made any changes to any of the settings. I don't know if something changed with an update, or if something happened with my dockers, but the last few backups the plugin has made ended up with lots of errors about the dockers not restarting. I came home from work today and had another dozen emails about the dockers not starting. HOWEVER, when I checked, all the dockers were started fine. Checking the logs and the debug logs, it appears they're starting, just not as fast as the plugin would like. Is there a way to set a longer delay before it gives up and throws an error?
-
Well shucks. I uninstalled the ca.mover.tuner app, rebooted, and tried to manually start the mover again. And wouldn't you know.. it's working now? Not sure what's going on. I'll try to let this go and if I see a problem (or not) I'll report it.
-
I'm not sure what I'm doing wrong. I've been using Unraid for serveral years now, and it's never really choked like this. My cache pool is completely full, and whenever I try to run the mover the log says "mover is running" but clearly it's not. When I watch my "MAIN" tab, I can see the activity on the pool, and there is no data being read or written on either the array or the cache pool. I was using a CA that added some mover tweaks. I disabled that app so I'm using just the default mover. I also enabled the mover log. It definitely reports that it's running but nothing is actually happening. I thought maybe I had some docker or VM that could be interfering so I stopped all that and disabled the docker/vm managers. Still same results. I then decided to try and just do a reboot, thinking maybe there is some stale file in use that's locked things up. When the system came back it wanted to do a parity check (odd also). I cancelled the parity check, attempted to run the mover manually again with the same results. That's when I decided to come here and post a thread seeking help. Any ideas? Attached is my complete diagnostics support package.kyber-diagnostics-20250116-1741.zip
-
I’ve been using nzbget for a couple of years. Never had any problems.
-
Well... i hate to jinx things, that's typically how things are for me... but... I let the memtest run all night and all day today till I got home from work. Successfully completed 4 passes with 0 errors, and was running for like 23.5 hours. I spent the afternoon putting the new motherboard back into the case. Tested memory again with the mobo all screwed in. Got to about 8% (past the dreaded 4% and onto test #3) and shut down. Then I transferred all the M.2 drives, connected all the expansion cards and fan headers, and put the lid on it. Booted up and let it run the memtest again for 1 complete pass. Then I booted into Unraid. So far, everything is going good. I updated all the plugins and dockers. I then shut down the docker and VM manager and started a parity check. Usually I run the check on the first of the month anyway but I missed it. Plus, it auto-started a parity check as soon as Unraid was loaded (remember, it was crashing whenever I started the preclear.. so I think the boot up parity check was just clearing the dirty bit). Once the parity check finishes, I'm going to reboot (so it's a clean shutdown and clean startup) and then (( FINGERS CROSSED )) try to run another preclear.
-
Yeah his videos are really helpful. Glad it worked for you and you're up and running.
-
Watch spaceinvader’s video on YouTube
-
I bought new RAM from Amazon on Thursday. Was supposed to be 2-day, delivery on Saturday. Never got it, said it was delayed, then delayed again then delayed AGAIN. I just now got it. It's running a memtest now but so far the entire set looks ok. It made it past the 4% mark at least. Been running about an hour and is up to 35% pass. Hope it's good. Gonna let it run all night and through tomorrow until I get home. Fingers crossed.
-
Heh. I know right? I'm baffled. I told my brother, if different RAM has the same problem.. I'm done. It's not worth continuing with this hardware design. My next build won't be "gamer" centered. I had envisioned one day building a VM that I could stream games from it onto a smaller SBC in a different room. As it is, I've not really been able to have a stable system running for more than a year, just hosting a PLEX server. The next time I build a server, I'm going back to server-grade parts. SuperMicro/ASRockRack board, Xeon or similar CPU, ECC RAM. It's just a lot to buy from scratch. But it's definitely something I should probably start researching if new RAM doesn't fix it. I can't afford to buy a replacement CPU.
-
Well... good news / bad news time. Good News: Replacement motherboard arrived. Bad News: Might not have been the motherboard. Details: The motherboard arrived late last night so I couldn't play around with it until after I got off work today. I spent a couple of hours being really gentle with it. I kept it on the box on top of it's anti-static bag. I removed the CPU from the old motherboard and diligently cleaned off the old thermal paste. I also removed the paste from the heatsink. I ordered some new goop that arrived a week ago, and applied that. Hooked up the power, connected a video card AND... nothing. At least not at first. Prior to the swap (I still haven't screwed it in yet...) I did another test of each ram stick one by one and identified which ones were good and bad. The first thing I did was put just 1 stick in the designated SINGLE slot, and tried to boot. The motherboard has an LED indicator for various boot stages, and indicated immediately a problem with the DRAM. So I popped out the stick and put in the other one I designated as GOOD. THAT allowed me to boot. I went into the BIOS and updated it first thing (I remembered having a problem with the original BIOS not working well with the CPU when I first built my rig so I wanted to make sure I updated it. Once the update was done I went back into the BIOS and tweaked some settings, like making sure the fan speeds were all on FULL. This is a bare build still at this point. Nothing is connected except a usb keyboard/mouse dongle, the video card, cpu and ram. I plugged in the Unraid USB and went straight into Memtest. Within 10 seconds, it reached like 4% pass then FAILED. F^CK. I rebooted with one of the "bad" sticks, again LED indicated DRAM issue. So I tried the LAST stick, labeled BAD but surprisingly it's up to 37% PASS at this point. All the others are failing at around that 4% mark. I don't know what happened. Something took a bite out of my RAM though. Unless this kind of behavior is typical with a bad CPU? There does appear to be some weird oily/greasy like residue around the solder pins under the old motherboard where the RAM is. I checked and it's NOT on the new motherboard. Maybe I had a leak somewhere that jacked up the slots and then with it running 24/7 it damaged the sticks over time. In any case, I'm going to look and see if I can return/exchange the newer RAM I have. It's probably too late (3+ years) for the old RAM to get replaced. If I can't do an exchange with Amazon on the new RAM, I'm going to have to wait for Income Tax Refund to buy new. I'm tempted to get something else. I mean, I'm really good with computers and building; I doubt it had been running good for over a year then stopped working because of a compatibility thing. I'm not even overclocking these guys.. this is the base values (not even using the XMP setting). But, these are my first G.Skill sticks. Perhaps a replacement set should be a different brand? What are your thoughts? I know my friend @Idolwild built his server with essentially the same components and hasn't had any trouble. He has the same motherboard, CPU, and RAM. So should I tempt fate and buy another matching set of RAM that I've been using? Should I go with something else like Kingston or Corsair? I'm lost. Also.. is there a CPU tester like MEMTEST? I'd like to try and verify it's still ok, and the problem is actually with the RAM. Thanks!
-
Yeah I know.. I was generalizing. I have a RAID controller but it's not using any RAID settings, just straight JBOD. Even the BIOS detects and lists all the drives available for choosing for boot, although I'm not using it. As for the VMs, I think all I'm passing though is network, but even that might be something the VM manager does. Without having access to Unraid until my replacement motherboard arrives, I can't know for sure. If I can get Unraid to load with the new motherboard, I think I'll be good. It'll be upsetting if I have to rebuild my server data, but at least I know HOW. I was just wondering if it would all of sudden go to boot Unraid then halt at some issue due to hardware change. At first run, the only change would be the motherboard. The CPU and RAM and all the other stuff should be all the same.
-
Not expecting delivery for awhile (January 21st+). Curious.. with a new motherboard, even if it's the same model, would it interfere with Unraid? Would it be a simple drop-in plug and play, or is it going to require rebuilding Unraid from scratch again? I know the system runs off the flash drive, and it's thumbprinted... just curious if there are any complications with swapping out the motherboard. Also curious, though I don't see how, would it complicate things if I had to replace the CPU too? I'm not sure how it all works.
-
Is it going away? I still use it too.
-
I’ve been testing single sticks in each slot. So far I’ve got one that passes in slot 2 but in no others, and I’m on my last stick. I’ve gone ahead and ordered a replacement motherboard. I agree it’s very unlikely that all my RAM is bad and only 1 works in 1 slot. I’ll try this method first and if the ram still fails with the new board I guess I’ll try buying another set.
-
I'm not sure I can use a different slot. The manual says to use a specific slot for single sticks. I will try it though.
-
Yeah I'm not sure what my problem is now. The first ram stick (one of the newer ones) completed 1 pass cycle with no fails. Then I swapped in the 2nd new stick and it failed almost immediately again (around 4-5% complete). I then swapped in one of the old sticks, it made it up to like 20% then I stopped watching it so it could it's thing. The first stick took about an hour to complete. After about 45 minutes I went back to check on the 3rd stick, it was about 86% complete but had a whole bunch of fails. I stopped the check and swapped in the last stick. It, too, failed in about 4-5% completion. So.. only 1 good stick? I swapped the first one back in again and re-tested it. This time, it failed at like 5% too. Very flaky. 1 stick out of 4 passed but then failed it's 2nd time. Could this indicate then that the RAM slot might be bad...aka the motherboard needs replaced? I feel like the whole BIOS and CPU issue is resolved for the most part... I've been able to get solid reboots into MEMTEST fine ever since I reseated it. I never noticed before but maybe it came loose or moved during my move into the apartment. I just wish I knew what to save up and buy.
-
I've been playing around a bit, hoping and praying I don't have to buy a new setup. At first I wanted to try single sticks, but couldn't get the system to boot up. The DEBUG LED indicated a problem with CPU at first. So I pulled it off and checked it out. Everything looked great. Re-attached it and tried again. This time I was getting a number indicating "22", which isn't in manual. So I googled it and lots of people are saying "22" is related to RAM. Ok, so the CPU problem went away, back to RAM. I put all the sticks back in, and tried again. I could get it to boot to BIOS, but no further. After making some changes (down clocking the speed of the RAM) I saved and rebooted but it never fully rebooted...just sat there. I've speen the last hour or so trying to get the settings to save. All I've been able to do is get it to boot into BIOS after doign a CMOS reset. I might have figured something out though. By having just 1 stick in (and in the slot the manual says to use for just 1.. another problem I was having ^_^) I was able to get a different DEBUG LED code, that this time indicated a problem with the PCI. I had another "AH HA!" moment. Prior to moving, or around that time, I WAS attempting to solve a continuing problem I had where my Parity Drives always reported errors on their monthly checks. Turned out, the motherboard didn't like those drives connected to it's SATA headers. I now have them connected to the SAS backplane. Before I reached that conclusion, I had bought a separate SATA controller card, in an attempt to solve the problem so I wouldn't lose a hotswap bay. It didn't work, but I was still using the card to control an SSD drive I was using for Plex metadata. Since I got an error this time reporting something with PCI, I remembered that the expansion card WAS something new I had added. Maybe it's failing? I pulled the card out, and with the 1 stick of RAM still in, the system booted up just fine, with no issues or delays! I went ahead and started a MEMTEST with that 1 stick, and so far, it's up to 35% with no issues. Much better than the 5% then failures I had before. I'm going to go ahead and play it safe and let it complete at least 1 pass on this stick, then I'll swap it with another one and test all 4. Man I'm going to be so relieved if that's the problem... It could explain why the parity drives connected to it gave me issues too, if the card itself is bad. I don't think I ever connected the SSD I currently have on it to the motherboard directly, the only stuff I ever had on the motherboard was the parity drives. So if the RAM tests work out, I'll hold tight until I can get the new drive precleared and then work on the SSD. Hope I'm not jinxing myself. < fingers crossed >
-
NOO! Don't say that! That's even MORE money... Are there any tools or something I can do to determine if that's the case? Like a memtest for cpu?
-
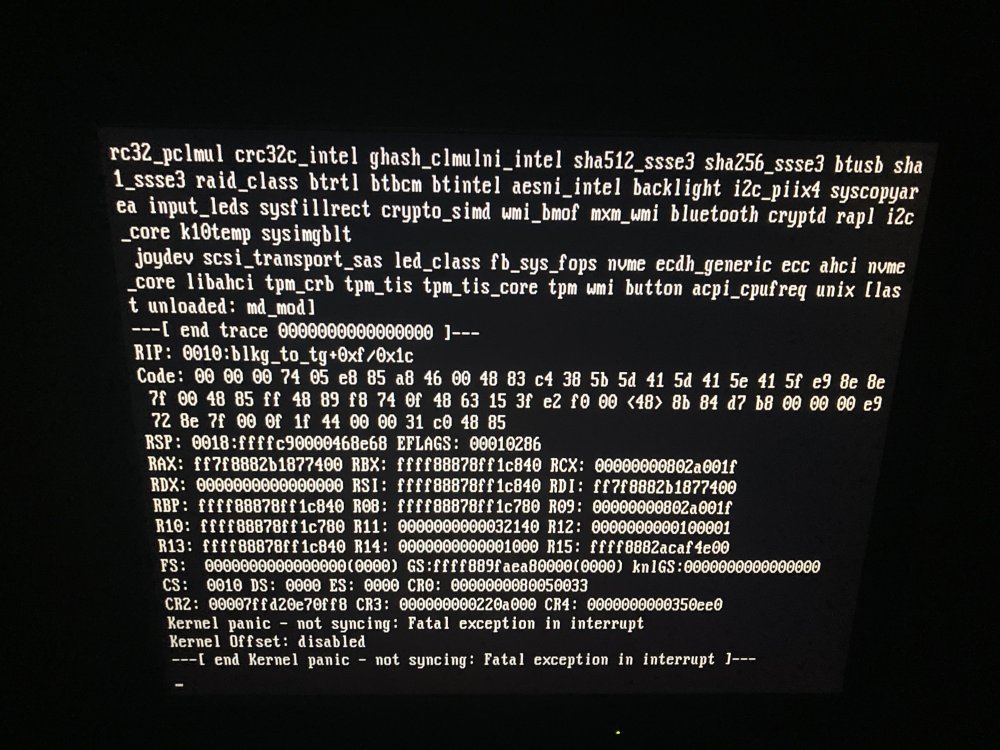
Just had another crash. I stopped the array and disabled Docker and VMs entirely. Everything was good for about 30 minutes so I tried to preclear again. I was able to see it happen with the open log window. Here's the entire crash. Jan 6 08:43:57 Kyber kernel: general protection fault, probably for non-canonical address 0xff7f88816d33d0b8: 0000 [#1] PREEMPT SMP NOPTI Jan 6 08:43:57 Kyber kernel: CPU: 15 PID: 0 Comm: swapper/15 Tainted: P O 6.1.64-Unraid #1 Jan 6 08:43:57 Kyber kernel: Hardware name: Micro-Star International Co., Ltd. MS-7C35/MEG X570 UNIFY (MS-7C35), BIOS A.F0 03/01/2023 Jan 6 08:43:57 Kyber kernel: RIP: 0010:blkg_to_tg+0xf/0x1c Jan 6 08:43:57 Kyber kernel: Code: 00 00 00 74 05 e8 85 a8 46 00 48 83 c4 38 5b 5d 41 5d 41 5e 41 5f e9 8e 8e 7f 00 48 85 ff 48 89 f8 74 0f 48 63 15 3f e2 f0 00 <48> 8b 84 d7 b8 00 00 00 e9 72 8e 7f 00 0f 1f 44 00 00 31 c0 48 85 Jan 6 08:43:57 Kyber kernel: RSP: 0018:ffffc9000056ce68 EFLAGS: 00010286 Jan 6 08:43:57 Kyber kernel: RAX: ff7f88816d33d000 RBX: ffff88878ff1c840 RCX: 00000000802a0014 Jan 6 08:43:57 Kyber kernel: RDX: 0000000000000000 RSI: ffff88878ff1c840 RDI: ff7f88816d33d000 Jan 6 08:43:57 Kyber kernel: RBP: ffff88878ff1c840 R08: ffff88878ff1c900 R09: 00000000802a0014 Jan 6 08:43:57 Kyber kernel: R10: ffff88878ff1c900 R11: 0000000000032140 R12: 0000000000100001 Jan 6 08:43:57 Kyber kernel: R13: ffff88878ff1c840 R14: 0000000000001000 R15: ffff888171cb2d00 Jan 6 08:43:57 Kyber kernel: FS: 0000000000000000(0000) GS:ffff889faebc0000(0000) knlGS:0000000000000000 Jan 6 08:43:57 Kyber kernel: CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 Jan 6 08:43:57 Kyber kernel: CR2: 000014975b7b6710 CR3: 000000000220a000 CR4: 0000000000350ee0 Jan 6 08:43:57 Kyber kernel: Call Trace: Jan 6 08:43:57 Kyber kernel: <IRQ> Jan 6 08:43:57 Kyber kernel: ? __die_body+0x1a/0x5c Jan 6 08:43:57 Kyber kernel: ? die_addr+0x38/0x51 Jan 6 08:43:57 Kyber kernel: ? exc_general_protection+0x30f/0x345 Jan 6 08:43:57 Kyber kernel: ? asm_exc_general_protection+0x22/0x30 Jan 6 08:43:57 Kyber kernel: ? blkg_to_tg+0xf/0x1c Jan 6 08:43:57 Kyber kernel: blk_throtl_bio_endio+0x28/0x154 Jan 6 08:43:57 Kyber kernel: bio_endio+0x10f/0x131 Jan 6 08:43:57 Kyber kernel: blk_update_request+0x22f/0x2e5 Jan 6 08:43:57 Kyber kernel: ? _base_process_reply_queue+0x138/0xedd [mpt3sas] Jan 6 08:43:57 Kyber kernel: scsi_end_request+0x27/0xf0 Jan 6 08:43:57 Kyber kernel: scsi_io_completion+0x156/0x457 Jan 6 08:43:57 Kyber kernel: blk_complete_reqs+0x41/0x4c Jan 6 08:43:57 Kyber kernel: __do_softirq+0x129/0x288 Jan 6 08:43:57 Kyber kernel: __irq_exit_rcu+0x5e/0xb8 Jan 6 08:43:57 Kyber kernel: common_interrupt+0x9b/0xc1 Jan 6 08:43:57 Kyber kernel: </IRQ> Jan 6 08:43:57 Kyber kernel: <TASK> Jan 6 08:43:57 Kyber kernel: asm_common_interrupt+0x22/0x40 Jan 6 08:43:57 Kyber kernel: RIP: 0010:native_safe_halt+0x7/0xc Jan 6 08:43:57 Kyber kernel: Code: 7c ff 85 c0 74 0b 65 81 25 1c d7 79 7e ff ff ff 7f 5b 5d e9 55 2c 38 00 e8 8e 88 7d ff f4 e9 4a 2c 38 00 e8 83 88 7d ff fb f4 <e9> 3e 2c 38 00 0f 1f 44 00 00 53 e8 61 4c ff ff 31 ff 89 c6 e8 fa Jan 6 08:43:57 Kyber kernel: RSP: 0018:ffffc900001cfe58 EFLAGS: 00000246 Jan 6 08:43:57 Kyber kernel: RAX: 0000000000004000 RBX: 0000000000000001 RCX: 000000000800f8c4 Jan 6 08:43:57 Kyber kernel: RDX: ffff889faebc0000 RSI: ffff8881016b1c00 RDI: ffff8881016b1c64 Jan 6 08:43:57 Kyber kernel: RBP: ffff8881016b1c64 R08: 000000000800f8c4 R09: 0000000000000002 Jan 6 08:43:57 Kyber kernel: R10: 0000000000000020 R11: 0000000000000187 R12: ffff88810935b400 Jan 6 08:43:57 Kyber kernel: R13: ffffffff823237a0 R14: ffffffff82323820 R15: 0000000000000000 Jan 6 08:43:57 Kyber kernel: ? native_safe_halt+0x5/0xc Jan 6 08:43:57 Kyber kernel: arch_safe_halt+0x5/0xb Jan 6 08:43:57 Kyber kernel: acpi_idle_do_entry+0x2a/0x43 Jan 6 08:43:57 Kyber kernel: acpi_idle_enter+0xbc/0xd0 Jan 6 08:43:57 Kyber kernel: cpuidle_enter_state+0xc9/0x202 Jan 6 08:43:57 Kyber kernel: cpuidle_enter+0x2a/0x38 Jan 6 08:43:57 Kyber kernel: do_idle+0x18d/0x1fb Jan 6 08:43:57 Kyber kernel: cpu_startup_entry+0x2a/0x2c Jan 6 08:43:57 Kyber kernel: start_secondary+0x101/0x101 Jan 6 08:43:57 Kyber kernel: secondary_startup_64_no_verify+0xce/0xdb Jan 6 08:43:57 Kyber kernel: </TASK> Jan 6 08:43:57 Kyber kernel: Modules linked in: md_mod xt_nat veth nvidia_uvm(PO) xt_CHECKSUM ipt_REJECT nf_reject_ipv4 xt_tcpudp ip6table_mangle ip6table_nat iptable_mangle vhost_iotlb xt_conntrack xt_MASQUERADE nf_conntrack_netlink nfnetlink xfrm_user xfrm_algo iptable_nat nf_nat nf_conntrack nf_defrag_ipv6 nf_defrag_ipv4 xt_addrtype br_netfilter xfs zfs(PO) zunicode(PO) zzstd(O) zlua(O) zavl(PO) icp(PO) zcommon(PO) znvpair(PO) spl(O) tcp_diag inet_diag nct6775 nct6775_core hwmon_vid ip6table_filter ip6_tables iptable_filter ip_tables x_tables bridge stp llc qlcnic r8169 realtek nvidia_drm(PO) nvidia_modeset(PO) nvidia(PO) edac_mce_amd edac_core intel_rapl_msr intel_rapl_common iosf_mbi video drm_kms_helper drm crct10dif_pclmul crc32_pclmul crc32c_intel ghash_clmulni_intel sha512_ssse3 mpt3sas sha256_ssse3 btusb sha1_ssse3 btrtl btbcm aesni_intel btintel i2c_piix4 backlight crypto_simd syscopyarea cryptd wmi_bmof mxm_wmi bluetooth rapl sysfillrect raid_class i2c_core k10temp nvme sysimgblt joydev ----------------------------------------- Ok I have discovered a new problem. I can't get the preclear to run with the array off or on, dockers and vms off or on. So I went back to the beginning as you suggested and started a MEMTEST. Turns out, it gets about 5% complete then starts throwing up red errors indicating failure. I have 4 matching sticks (although they are 2 sets of 2 with different manufacturing dates). I removed 2 matching date sticks (newer) and tested with the old RAM. They failed at the same point. Removed those and swapped in the newer sticks. They failed at the same point too and actually threw up a banner I had to clear before I could continue. So the problem might stem from the vey root of the system, starting with the RAM. Unfortunately this is a major set back for me since I don't have a lot of free cash. Income tax season is coming, I might have to wait to get this fixed. But I pretty much know at this point that bad RAM needs fixed before further troubleshooting can be done. Just for gits and shiggles I did alcohol wipe the contacts on the RAM sticks, and blew dust out of the slots, it made no different. <sigh>
-
Just had another crash. I stopped the array and disabled Docker and VMs entirely. Everything was good for about 30 minutes so I tried to preclear again. I was able to see it happen with the open log window. Here's the entire crash. Jan 6 08:43:57 Kyber kernel: general protection fault, probably for non-canonical address 0xff7f88816d33d0b8: 0000 [#1] PREEMPT SMP NOPTI Jan 6 08:43:57 Kyber kernel: CPU: 15 PID: 0 Comm: swapper/15 Tainted: P O 6.1.64-Unraid #1 Jan 6 08:43:57 Kyber kernel: Hardware name: Micro-Star International Co., Ltd. MS-7C35/MEG X570 UNIFY (MS-7C35), BIOS A.F0 03/01/2023 Jan 6 08:43:57 Kyber kernel: RIP: 0010:blkg_to_tg+0xf/0x1c Jan 6 08:43:57 Kyber kernel: Code: 00 00 00 74 05 e8 85 a8 46 00 48 83 c4 38 5b 5d 41 5d 41 5e 41 5f e9 8e 8e 7f 00 48 85 ff 48 89 f8 74 0f 48 63 15 3f e2 f0 00 <48> 8b 84 d7 b8 00 00 00 e9 72 8e 7f 00 0f 1f 44 00 00 31 c0 48 85 Jan 6 08:43:57 Kyber kernel: RSP: 0018:ffffc9000056ce68 EFLAGS: 00010286 Jan 6 08:43:57 Kyber kernel: RAX: ff7f88816d33d000 RBX: ffff88878ff1c840 RCX: 00000000802a0014 Jan 6 08:43:57 Kyber kernel: RDX: 0000000000000000 RSI: ffff88878ff1c840 RDI: ff7f88816d33d000 Jan 6 08:43:57 Kyber kernel: RBP: ffff88878ff1c840 R08: ffff88878ff1c900 R09: 00000000802a0014 Jan 6 08:43:57 Kyber kernel: R10: ffff88878ff1c900 R11: 0000000000032140 R12: 0000000000100001 Jan 6 08:43:57 Kyber kernel: R13: ffff88878ff1c840 R14: 0000000000001000 R15: ffff888171cb2d00 Jan 6 08:43:57 Kyber kernel: FS: 0000000000000000(0000) GS:ffff889faebc0000(0000) knlGS:0000000000000000 Jan 6 08:43:57 Kyber kernel: CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 Jan 6 08:43:57 Kyber kernel: CR2: 000014975b7b6710 CR3: 000000000220a000 CR4: 0000000000350ee0 Jan 6 08:43:57 Kyber kernel: Call Trace: Jan 6 08:43:57 Kyber kernel: <IRQ> Jan 6 08:43:57 Kyber kernel: ? __die_body+0x1a/0x5c Jan 6 08:43:57 Kyber kernel: ? die_addr+0x38/0x51 Jan 6 08:43:57 Kyber kernel: ? exc_general_protection+0x30f/0x345 Jan 6 08:43:57 Kyber kernel: ? asm_exc_general_protection+0x22/0x30 Jan 6 08:43:57 Kyber kernel: ? blkg_to_tg+0xf/0x1c Jan 6 08:43:57 Kyber kernel: blk_throtl_bio_endio+0x28/0x154 Jan 6 08:43:57 Kyber kernel: bio_endio+0x10f/0x131 Jan 6 08:43:57 Kyber kernel: blk_update_request+0x22f/0x2e5 Jan 6 08:43:57 Kyber kernel: ? _base_process_reply_queue+0x138/0xedd [mpt3sas] Jan 6 08:43:57 Kyber kernel: scsi_end_request+0x27/0xf0 Jan 6 08:43:57 Kyber kernel: scsi_io_completion+0x156/0x457 Jan 6 08:43:57 Kyber kernel: blk_complete_reqs+0x41/0x4c Jan 6 08:43:57 Kyber kernel: __do_softirq+0x129/0x288 Jan 6 08:43:57 Kyber kernel: __irq_exit_rcu+0x5e/0xb8 Jan 6 08:43:57 Kyber kernel: common_interrupt+0x9b/0xc1 Jan 6 08:43:57 Kyber kernel: </IRQ> Jan 6 08:43:57 Kyber kernel: <TASK> Jan 6 08:43:57 Kyber kernel: asm_common_interrupt+0x22/0x40 Jan 6 08:43:57 Kyber kernel: RIP: 0010:native_safe_halt+0x7/0xc Jan 6 08:43:57 Kyber kernel: Code: 7c ff 85 c0 74 0b 65 81 25 1c d7 79 7e ff ff ff 7f 5b 5d e9 55 2c 38 00 e8 8e 88 7d ff f4 e9 4a 2c 38 00 e8 83 88 7d ff fb f4 <e9> 3e 2c 38 00 0f 1f 44 00 00 53 e8 61 4c ff ff 31 ff 89 c6 e8 fa Jan 6 08:43:57 Kyber kernel: RSP: 0018:ffffc900001cfe58 EFLAGS: 00000246 Jan 6 08:43:57 Kyber kernel: RAX: 0000000000004000 RBX: 0000000000000001 RCX: 000000000800f8c4 Jan 6 08:43:57 Kyber kernel: RDX: ffff889faebc0000 RSI: ffff8881016b1c00 RDI: ffff8881016b1c64 Jan 6 08:43:57 Kyber kernel: RBP: ffff8881016b1c64 R08: 000000000800f8c4 R09: 0000000000000002 Jan 6 08:43:57 Kyber kernel: R10: 0000000000000020 R11: 0000000000000187 R12: ffff88810935b400 Jan 6 08:43:57 Kyber kernel: R13: ffffffff823237a0 R14: ffffffff82323820 R15: 0000000000000000 Jan 6 08:43:57 Kyber kernel: ? native_safe_halt+0x5/0xc Jan 6 08:43:57 Kyber kernel: arch_safe_halt+0x5/0xb Jan 6 08:43:57 Kyber kernel: acpi_idle_do_entry+0x2a/0x43 Jan 6 08:43:57 Kyber kernel: acpi_idle_enter+0xbc/0xd0 Jan 6 08:43:57 Kyber kernel: cpuidle_enter_state+0xc9/0x202 Jan 6 08:43:57 Kyber kernel: cpuidle_enter+0x2a/0x38 Jan 6 08:43:57 Kyber kernel: do_idle+0x18d/0x1fb Jan 6 08:43:57 Kyber kernel: cpu_startup_entry+0x2a/0x2c Jan 6 08:43:57 Kyber kernel: start_secondary+0x101/0x101 Jan 6 08:43:57 Kyber kernel: secondary_startup_64_no_verify+0xce/0xdb Jan 6 08:43:57 Kyber kernel: </TASK> Jan 6 08:43:57 Kyber kernel: Modules linked in: md_mod xt_nat veth nvidia_uvm(PO) xt_CHECKSUM ipt_REJECT nf_reject_ipv4 xt_tcpudp ip6table_mangle ip6table_nat iptable_mangle vhost_iotlb xt_conntrack xt_MASQUERADE nf_conntrack_netlink nfnetlink xfrm_user xfrm_algo iptable_nat nf_nat nf_conntrack nf_defrag_ipv6 nf_defrag_ipv4 xt_addrtype br_netfilter xfs zfs(PO) zunicode(PO) zzstd(O) zlua(O) zavl(PO) icp(PO) zcommon(PO) znvpair(PO) spl(O) tcp_diag inet_diag nct6775 nct6775_core hwmon_vid ip6table_filter ip6_tables iptable_filter ip_tables x_tables bridge stp llc qlcnic r8169 realtek nvidia_drm(PO) nvidia_modeset(PO) nvidia(PO) edac_mce_amd edac_core intel_rapl_msr intel_rapl_common iosf_mbi video drm_kms_helper drm crct10dif_pclmul crc32_pclmul crc32c_intel ghash_clmulni_intel sha512_ssse3 mpt3sas sha256_ssse3 btusb sha1_ssse3 btrtl btbcm aesni_intel btintel i2c_piix4 backlight crypto_simd syscopyarea cryptd wmi_bmof mxm_wmi bluetooth rapl sysfillrect raid_class i2c_core k10temp nvme sysimgblt joydev
-
Yea it crashed again last night. I have previously enabled the syslog to save locally on the array. I opened the log and it doesn't indicate any errors when it crashed. It shows what I saw at the timestamps from when I went to bed, then it stopped logging when the crash happened. The log then updated and showed the boot process when I rebooted it this morning. I updated the syslog server settings to also write to FLASH. Before rebooting, I did grab a picture of the screen with my phone. Not really a lot to go by. As for the cache SSD's... while the array was offline yesterday I did run a Short and Extended self test on both drives and they came back with no issues.
-
I appreciate your input and have no problem testing the various things you suggested. However, even though I posted issues in the past, I feel this problem is new. The only change in hardware is a new drive. The system has been very stable for a long time. I moved into my own apartment back in June and haven’t had a single issue. Since making this thread, I’ve gone ahead and kept the array offline. It’s been over 6 hours now and hasn’t had any issues in the Unraid log terminal. I connected the new drive about 2 hours ago and started a preclear cycle again, watching it off and on. So far it’s running fine with no issues. I’m about to go to bed for the night. If I wake up tomorrow and the system has crashed again, how can I recover a log? I can take a picture with my phone of the monitor showing the last error, but that’s about it. Fingers crossed it will work fine. Something else I had noticed in the logs was that the btrfs file system my cache drive pool is using was noticing a lot of checksum errors. These are nvme drives. Could the errors be caused by the drives starting to fail from usage? And then in turn, could failing cache drives be causing an unrecoverable system crash?
-
Guys, I'm in a whole lotta hurt. I don't know what's going on with my server. Typical thread starting sentence lol.. Since around Thanksgiving, I've had these intermittent cases where I come home from work and can't access my server. I typically access it remotely (locally) with another device (computer or tablet) on my LAN network, and utilize the web interface. When it's not working, I check the active log display on the server by connecting a monitor to the server and see what's what. Sometimes, it's usually easy enough to diagnose like the power went out and it's sitting at the BIOS screen (failsafe I have set up so it doesn't auto restart into Unraid). Other times, it will be sitting on a screen indicating something literally crashed, and Unraid is stuck, resulting in me having to force a power off. I really don't like doing that. The frequency of the "crashing" is happening more and more frequently, and now it's a daily thing. I bought a new hard drive for Christmas and have been trying to have it preclear before adding it to the array. Simple enough process, I have 24 drives and have done this PLENTY of times. The most recent crashing issues seemed to be when I stop the array to do the drive swap. I'll sit there and wait, and nothing seems to happen, then the computer will indicate it's accessing Unraid "Off-Line". Sure enough, the system has panic crashed again. This is my 3rd day now dealing with this issue. I can get it up and running, start the preclear, go to bed, get up the next morning and it's crashed. I don't know what it's doing. Yesterday I had an "ah ha!" moment. I tried to access one of my dockers and I couldn't connect to it. I compared settings with my brother who uses the same system/dockers. The settings were all good, and the files in /appdata were all there, but the docker wouldn't load. I discovered I could see the log of the docker when launching it, and it's crashing due to a corrupted database. Hmm, so I go into the files and see I have backups for a month (4 total). Turns out, every single backup had a corrupted database too. So this issue with the docker had been on going for a while. I remember having an issue in the past where the dockers weren't shutting down when the array shuts down. So I thought "That's it!", the dockers aren't shutting down again when the array shuts down, and it's locking up or something and crashing. So I disabled that specific docker and checked all my others to be safe. All good. I tempted fate and shut down the array. All good, no crashing. Restarted the array, all good again. I shut the server down, waited like 5 minutes, rebooted, array started fine. Stopped and restarted the array a few more times and rebooted again. All is great. So did I fix the problem? I went ahead and restarted the "broken" docker with a blank database to essentially start over. Stopped the array, and restarted, all is good. Yes! Docker problem causing the crash seems to be gone. So I started the preclear process on the new drive again and went to bed. I expected everything was working good now. But just out of curiosity I switched on the monitor connected to the server to check the status before going to work. And..... crashed. WTF. I don't know what's going on at this point. Something somewhere is messed up. I don't know much about the inner workings of Unraid/Linux to troubleshoot this much. I'm learning, and I'm getting a lot better, but I need some help. Current conditions - New drive is out of the case, uncleared, Array is updated to show the old drive is missing and is waiting for replacements. I've also re-disabled the troublesome docker for safe measure. kyber-diagnostics-20240105-1449.zip
-
Ahh, that makes sense. Thanks for the response. It's good to know that if something is corrupted, Unraid just won't load. I know I actively keep backups of the OS on the website, so if anything ever DOES happen, I can always restore. Now I'm just bugged about that message with the Mover missing, and I wish I knew what caused the panic crash when I was rebooting. Oh well, guess I'll just have to be more diligent and remember to take a screenshot next time I see it. Thanks again!
-
Hey guys! I just had an interesting situation crop up. I started having some issues with accessing my shares over the network, and issues with my dockers not working right. Everything was up-to-date and had been working fine (no changes in settings and/or hardware). But, I was having these issues. So I decided to do a reboot. Well, that caused an issue. I waited about 5 minutes for my server to shutdown and restart but the screen never reloaded. So I connected a monitor and looked at the "live log". It showed it experienced a fatal crash in something. I wish I grabbed a photo of it, but I was negligent and just did a forced poweroff with the button. Upon rebooting, one of the last lines I saw in the "live log" before the login prompt was an error about not finding the Mover binary. Very strange. This has got me thinking... Is there a way to do a system file integrity check? Kinda like the Windows command line [sfc /scannow] that does a system file check and replaced corrupted files. I would be curious to know if maybe my flash drive is going bad and causing some bit corruption somewhere and my system is becoming unstable. Seeing as how this is the first forced reboot in MONTHS, I'm going ahead and letting it do the array's parity check. Better safe than sorry. But yea, in response to my question.. does Unraid offer such a thing?


