




mhn_10
Members
-
Joined
-
Last visited
-
I was able to update cache slots before stopping. Posting the new diagnostics. This seemed to have worked.unmhn-diagnostics-20241229-1215.zip
-
I don't exactly remember what I did while setting up the cache pool. But when I try to assign both devices to the pool, its only showing 1 slot. See screenshot. I followed all the other steps. Attaching diagnostics unmhn-diagnostics-20241229-1157.zip

-
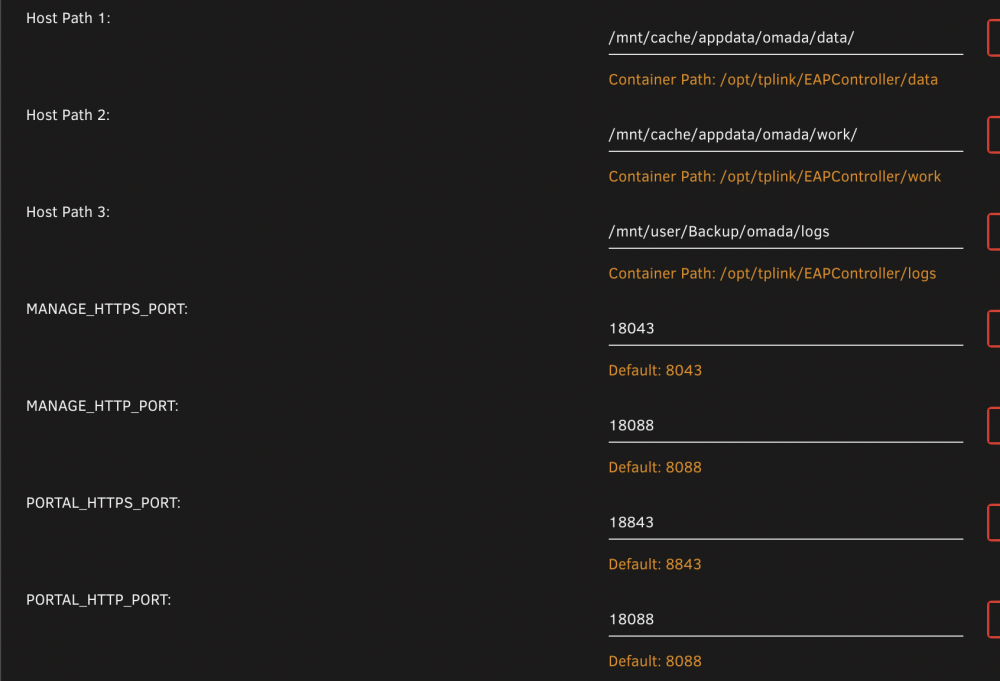
Upgraded unraid to 6.12.14 and I'm getting `Unmountable: Unsupported or no file system` I tried the steps outlined here by stopping the array, unassigning and starting it back, but that is not working. I also tried `btrfs rescue zero-log /dev/sdi1` but I keep getting `ERROR: /dev/sdi1 is currently mounted` Not sure how to proceed here. My appdata is in cache unmhn-diagnostics-20241227-1832.zipI'm trying to do a rebuild with this https://docs.unraid.net/unraid-os/manual/storage-management/#rebuilding-a-drive-onto-itselfI retried after reconnecting and did a repair with '-L'. But this time after stopping and starting the drive, no `Parity-Sync/Data-Rebuild` is shown. Drive is still disabled This was the output after '-L' Phase 1 - find and verify superblock... Phase 2 - using internal log - zero log... - scan filesystem freespace and inode maps... - found root inode chunk Phase 3 - for each AG... - scan and clear agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - agno = 8 - agno = 9 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 3 - agno = 1 - agno = 2 - agno = 6 - agno = 4 - agno = 5 - agno = 7 - agno = 8 - agno = 9 Phase 5 - rebuild AG headers and trees... - reset superblock... Phase 6 - check inode connectivity... - resetting contents of realtime bitmap and summary inodes - traversing filesystem ... - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify and correct link counts... Maximum metadata LSN (7:0) is ahead of log (1:2). Format log to cycle 10. doneNot sure what happened, but my disk 2 has gone back to being disabled and emulated. I'm not sure whether `Parity-Sync/Data-Rebuild in progress.` got complete. But now its showing as Read-check paused. unmhn-diagnostics-20231229-1754.zipThanks for the reference doc. I was following it. I successfully checked and repaired the drive. The following was the output After Checking Phase 1 - find and verify superblock... Phase 2 - using internal log - zero log... - scan filesystem freespace and inode maps... - found root inode chunk Phase 3 - for each AG... - scan (but don't clear) agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - agno = 8 - agno = 9 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 5 - agno = 1 - agno = 6 - agno = 2 - agno = 7 - agno = 4 - agno = 3 - agno = 8 - agno = 9 No modify flag set, skipping phase 5 Phase 6 - check inode connectivity... - traversing filesystem ... - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify link counts... No modify flag set, skipping filesystem flush and exiting. After repairing with `-L` option Phase 1 - find and verify superblock... Phase 2 - using internal log - zero log... - scan filesystem freespace and inode maps... - found root inode chunk Phase 3 - for each AG... - scan and clear agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - agno = 8 - agno = 9 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 6 - agno = 3 - agno = 4 - agno = 2 - agno = 5 - agno = 7 - agno = 1 - agno = 8 - agno = 9 Phase 5 - rebuild AG headers and trees... - reset superblock... Phase 6 - check inode connectivity... - resetting contents of realtime bitmap and summary inodes - traversing filesystem ... - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify and correct link counts... Maximum metadata LSN (1:2452269) is ahead of log (1:2). Format log to cycle 4. done Since I didn't see any errors, I stopped the array, and started in normal mode. Now its showing `Parity-Sync/Data-Rebuild in progress.` . I hope its the right thingI disconnected and reconnected all the cables. Seems to have solved the cache pool ssd issue. But 1 disk is unable to mount. unmhn-diagnostics-20231228-0003.zipServer was working perfectly fine. Now it shows 'Unmountable disk present'. I believe 1 cache disk and 1 data disk are having issues. Data disk 2 is showing as not installed. Have only tried reboot till now. Didn't want to break anything by trying other stuff unmhn-diagnostics-20231218-1645.zipINFO: Time zone set to 'America/Los_Angeles' INFO: Setting 'manage.http.port' to 18088 in omada.properties INFO: Setting 'manage.https.port' to 18043 in omada.properties INFO: Setting 'portal.http.port' to 18088 in omada.properties INFO: Setting 'portal.https.port' to 18843 in omada.properties INFO: Starting Omada Controller as user omada 01-07-2022 17:57:47.590 INFO [log4j-thread] [] c.t.s.o.c.o.a.b(32): success to load configuration omada.properties 01-07-2022 17:57:47.658 INFO [main] [] c.t.s.o.s.OmadaBootstrap(79): going to start local mongod. 01-07-2022 17:59:27.773 ERROR [main] [] c.t.s.f.c.FacadeUtils(68): facadeMsgEnable is not enable, msg: Fail to start mongo DB server 01-07-2022 17:59:27.774 WARN [main] [] c.t.s.o.s.s.b(145): Fail to start mongo DB server 01-07-2022 17:59:27.775 WARN [main] [] c.t.s.o.s.s.a(77): com.tplink.smb.omada.starter.b.a: Fail to start mongo DB server com.tplink.smb.omada.starter.b.a: Fail to start mongo DB server at com.tplink.smb.omada.starter.server.b.a(SourceFile:146) ~[local-starter-5.0.29.jar:5.0.29] at com.tplink.smb.omada.starter.server.a.e(SourceFile:74) [local-starter-5.0.29.jar:5.0.29] at com.tplink.smb.omada.starter.OmadaBootstrap.d(SourceFile:218) [local-starter-5.0.29.jar:5.0.29] at com.tplink.smb.omada.starter.OmadaBootstrap.q(SourceFile:290) [local-starter-5.0.29.jar:5.0.29] at com.tplink.smb.omada.starter.OmadaBootstrap.a(SourceFile:89) [local-starter-5.0.29.jar:5.0.29] at com.tplink.smb.omada.starter.OmadaBootstrap.e(SourceFile:245) [local-starter-5.0.29.jar:5.0.29] at com.tplink.smb.omada.starter.OmadaLinuxMain.a(SourceFile:84) [local-starter-5.0.29.jar:5.0.29] at com.tplink.smb.omada.starter.OmadaLinuxMain.main(SourceFile:36) [local-starter-5.0.29.jar:5.0.29] I tried re-downloading the docker by force update. But I still get the same error. Could it be some permission issue with my shares? Attaching my docker settings. My appdata is set to public, if that would help Not sure if this issue is related. https://github.com/mbentley/docker-omada-controller/issues/138 It looks similar, but not sure how to resolve it.
 I'm facing an issue with webui not loading. The container starts in docker tab, but when I check logs, I see the below error 2022-01-05 18:44:26 [main] [WARN]-[SourceFile:367] - Mongo Client connect error while init Jetty.com.mongodb.MongoTimeoutException: Timed out after 30000 ms while waiting to connect. Client view of cluster state is {type=UNKNOWN, servers=[{address=127.0.0.1:27217, type=UNKNOWN, state=CONNECTING, exception={com.mongodb.MongoSocketOpenException: Exception opening socket}, caused by {java.net.ConnectException: Connection refused (Connection refused)}}] 2022-01-05 18:45:07 [mongo-check-thread] [WARN]-[SourceFile:151] - Fail to start mongo DB server 2022-01-05 18:45:07 [mongo-check-thread] [WARN]-[SourceFile:78] - com.tplink.omada.start.a.a: Fail to start mongo DB server com.tplink.omada.start.a.a: Fail to start mongo DB server at com.tplink.omada.start.b.d.a(SourceFile:152) ~[omada-start.jar:?] at com.tplink.omada.start.b.b.e(SourceFile:75) ~[omada-start.jar:?] at com.tplink.omada.start.OmadaBootstrap.d(SourceFile:224) ~[omada-start.jar:?] at com.tplink.omada.start.OmadaBootstrap.n(SourceFile:217) ~[omada-start.jar:?] at com.tplink.omada.start.OmadaBootstrap.x(SourceFile:335) ~[omada-start.jar:?] at java.lang.Thread.run(Thread.java:748) [?:1.8.0_312] Any suggestion on what I can doAn unknown error occurred (4294967283) Error code: 4294967283 Getting the above error all of a sudden. Running Plex Version 1.21.0.3711 and unraid 6.8.3. Any ideas why this is happeningrtorrent was working fine, but suddenly getting the following errors (attached screenshot) What could be the issue. 2020-07-06 20:45:05,333 DEBG 'rutorrent-script' stderr output: 2020/07/06 20:45:05 [error] 713#713: *65 connect() failed (111: Connection refused) while connecting to upstream, client: 172.17.0.1, server: localhost, request: "POST /RPC2 HTTP/1.1", upstream: "scgi://127.0.0.1:5000", host: "192.168.1.106:9080" unmhn-diagnostics-20200706-2042.zip rtorrentlogs.txt
I'm facing an issue with webui not loading. The container starts in docker tab, but when I check logs, I see the below error 2022-01-05 18:44:26 [main] [WARN]-[SourceFile:367] - Mongo Client connect error while init Jetty.com.mongodb.MongoTimeoutException: Timed out after 30000 ms while waiting to connect. Client view of cluster state is {type=UNKNOWN, servers=[{address=127.0.0.1:27217, type=UNKNOWN, state=CONNECTING, exception={com.mongodb.MongoSocketOpenException: Exception opening socket}, caused by {java.net.ConnectException: Connection refused (Connection refused)}}] 2022-01-05 18:45:07 [mongo-check-thread] [WARN]-[SourceFile:151] - Fail to start mongo DB server 2022-01-05 18:45:07 [mongo-check-thread] [WARN]-[SourceFile:78] - com.tplink.omada.start.a.a: Fail to start mongo DB server com.tplink.omada.start.a.a: Fail to start mongo DB server at com.tplink.omada.start.b.d.a(SourceFile:152) ~[omada-start.jar:?] at com.tplink.omada.start.b.b.e(SourceFile:75) ~[omada-start.jar:?] at com.tplink.omada.start.OmadaBootstrap.d(SourceFile:224) ~[omada-start.jar:?] at com.tplink.omada.start.OmadaBootstrap.n(SourceFile:217) ~[omada-start.jar:?] at com.tplink.omada.start.OmadaBootstrap.x(SourceFile:335) ~[omada-start.jar:?] at java.lang.Thread.run(Thread.java:748) [?:1.8.0_312] Any suggestion on what I can doAn unknown error occurred (4294967283) Error code: 4294967283 Getting the above error all of a sudden. Running Plex Version 1.21.0.3711 and unraid 6.8.3. Any ideas why this is happeningrtorrent was working fine, but suddenly getting the following errors (attached screenshot) What could be the issue. 2020-07-06 20:45:05,333 DEBG 'rutorrent-script' stderr output: 2020/07/06 20:45:05 [error] 713#713: *65 connect() failed (111: Connection refused) while connecting to upstream, client: 172.17.0.1, server: localhost, request: "POST /RPC2 HTTP/1.1", upstream: "scgi://127.0.0.1:5000", host: "192.168.1.106:9080" unmhn-diagnostics-20200706-2042.zip rtorrentlogs.txt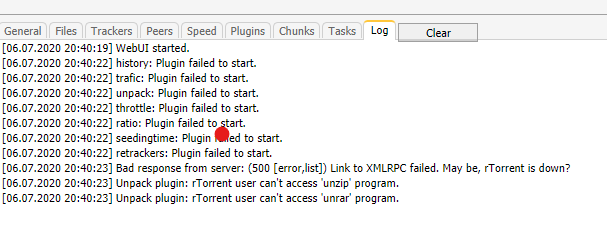 No I haven't done it. The field is left empty.
No I haven't done it. The field is left empty.



