




MarlinJones
Members
-
Joined
-
Last visited
Everything posted by MarlinJones
-
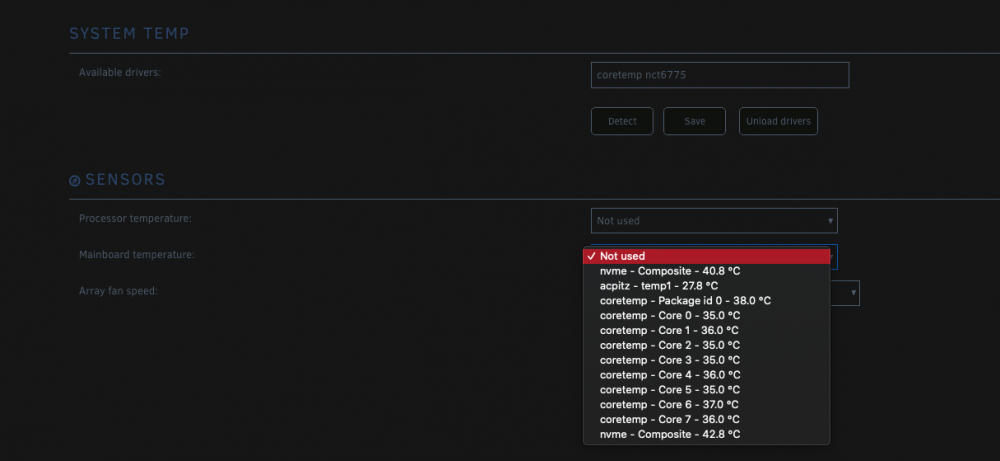
I read through a bunch of these posts but still couldnt find a solution for the behavior I am seeing... sensors-detect is able to find `coretemp` and `nct6775` right away on my ASUS Prime Z490-Plus board. I am also able to find those drivers using "Detect" in the SYSTEM TEMP section of the plugin... However, it appears to me that none of the nct6775 sensors are actually populating... From command line, i can run `modprobe nct6775` without error, and it appears to me that the driver is loading properly. Is there something I am missing to ensure that nct6775 loads correctly? I also edited /boot/config/go to include: `modprobe coretemp` `modprobe nct6775` `/usr/bin/sensors -s` Heres what I see at the plugin:
-
OS Version: 6.9.0-beta30 Processor: AMD Ryzen 7 PRO 4750G Motherboard: MSI MAG B550 MORTAR This is a bit of a duplicate post. I've been diagnosing some crashing behavior in another thread here. More recent developments seem to point at the rtl8125 driver and I thought that it might be best to bring that information here since I believe rtl8125 is a relatively new addition. I am seeing some syslog exception behavior followed by network messages in syslog. I think that the failures sometimes result in kernel panics that crash the whole system, but other times it seems to recover. Here is a log when it recovers: Oct 13 20:48:36 Athena kernel: WARNING: CPU: 14 PID: 14184 at drivers/iommu/iova.c:814 iova_magazine_free_pfns.part.0+0x37/0x5e Oct 13 20:48:36 Athena kernel: Modules linked in: xt_CHECKSUM ipt_REJECT ip6table_mangle ip6table_nat iptable_mangle ip6table_filter ip6_tables vhost_net tun vhost vhost_iotlb tap veth xt_nat xt_MASQUERADE iptable_filter iptable_nat nf_nat ip_tables xfs nfsd lockd grace sunrpc md_mod bonding edac_mce_amd kvm_amd kvm crct10dif_pclmul crc32_pclmul crc32c_intel ghash_clmulni_intel aesni_intel crypto_simd cryptd glue_helper wmi_bmof mpt3sas ahci i2c_piix4 raid_class rapl r8125(O) ccp nvme i2c_core libahci video scsi_transport_sas k10temp r8169 realtek backlight nvme_core acpi_cpufreq wmi button Oct 13 20:48:36 Athena kernel: CPU: 14 PID: 14184 Comm: kworker/14:1 Tainted: G W O 5.8.13-Unraid #1 Oct 13 20:48:36 Athena kernel: Hardware name: Micro-Star International Co., Ltd. MS-7C94/MAG B550M MORTAR (MS-7C94), BIOS 1.44 09/29/2020 Oct 13 20:48:36 Athena kernel: Workqueue: events rtl8125_reset_task [r8125] Oct 13 20:48:36 Athena kernel: RIP: 0010:iova_magazine_free_pfns.part.0+0x37/0x5e Oct 13 20:48:36 Athena kernel: Code: 89 fb 48 89 f7 e8 45 ec 29 00 49 89 c4 49 63 c5 48 3b 03 73 23 48 8b 74 c3 08 48 89 ef e8 6e fb ff ff 48 85 c0 48 89 c6 75 04 <0f> 0b eb 05 e8 4c ff ff ff 41 ff c5 eb d5 4c 89 e6 48 89 ef e8 a7 Oct 13 20:48:36 Athena kernel: RSP: 0018:ffffc900016afd20 EFLAGS: 00010046 Oct 13 20:48:36 Athena kernel: RAX: 0000000000000000 RBX: ffff888167624000 RCX: 000000008040003d Oct 13 20:48:36 Athena kernel: RDX: 0000000000000001 RSI: 0000000000000000 RDI: ffff8883fb4e9008 Oct 13 20:48:36 Athena kernel: RBP: ffff8883fb4e9008 R08: 0000000000000001 R09: ffffffff8141efc9 Oct 13 20:48:36 Athena kernel: R10: ffff8883fb38a6c0 R11: ffff8883fb38a6c0 R12: 0000000000000046 Oct 13 20:48:36 Athena kernel: R13: 0000000000000040 R14: ffff8883fb4e9008 R15: ffff8883fb4e9088 Oct 13 20:48:36 Athena kernel: FS: 0000000000000000(0000) GS:ffff8883ff380000(0000) knlGS:0000000000000000 Oct 13 20:48:36 Athena kernel: CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 Oct 13 20:48:36 Athena kernel: CR2: 000014e1d4f0c000 CR3: 000000035adec000 CR4: 0000000000340ee0 Oct 13 20:48:36 Athena kernel: Call Trace: Oct 13 20:48:36 Athena kernel: free_iova_fast+0x167/0x186 Oct 13 20:48:36 Athena kernel: fq_ring_free+0x74/0x92 Oct 13 20:48:36 Athena kernel: queue_iova+0x74/0x104 Oct 13 20:48:36 Athena kernel: __iommu_dma_unmap+0xc6/0xe8 Oct 13 20:48:36 Athena kernel: rtl8125_rx_clear+0x4b/0x85 [r8125] Oct 13 20:48:36 Athena kernel: rtl8125_reset_task+0x9d/0x114 [r8125] Oct 13 20:48:36 Athena kernel: process_one_work+0x13c/0x1d5 Oct 13 20:48:36 Athena kernel: worker_thread+0x18b/0x22f Oct 13 20:48:36 Athena kernel: ? process_scheduled_works+0x27/0x27 Oct 13 20:48:36 Athena kernel: kthread+0xe5/0xea Oct 13 20:48:36 Athena kernel: ? kthread_unpark+0x52/0x52 Oct 13 20:48:36 Athena kernel: ret_from_fork+0x22/0x30 Oct 13 20:48:36 Athena kernel: ---[ end trace 2e5dccb3ecd7d581 ]--- Oct 13 20:48:36 Athena dhcpcd[1891]: br0: carrier acquired Oct 13 20:48:36 Athena dhcpcd[1891]: br0: rebinding lease of 192.168.1.2 Oct 13 20:48:37 Athena kernel: r8125: eth0: link down Oct 13 20:48:37 Athena kernel: bond0: (slave eth0): link status definitely down, disabling slave Oct 13 20:48:37 Athena kernel: device eth0 left promiscuous mode Oct 13 20:48:37 Athena kernel: bond0: now running without any active interface! Oct 13 20:48:37 Athena kernel: br0: port 1(bond0) entered disabled state Oct 13 20:48:38 Athena dhcpcd[1891]: br0: carrier lost Oct 13 20:48:40 Athena kernel: r8125: eth0: link up Oct 13 20:48:40 Athena dhcpcd[1891]: br0: carrier acquired Oct 13 20:48:40 Athena kernel: bond0: (slave eth0): link status definitely up, 1000 Mbps full duplex Oct 13 20:48:40 Athena kernel: bond0: (slave eth0): making interface the new active one Oct 13 20:48:40 Athena kernel: device eth0 entered promiscuous mode Oct 13 20:48:40 Athena kernel: bond0: active interface up! Oct 13 20:48:40 Athena kernel: br0: port 1(bond0) entered blocking state Oct 13 20:48:40 Athena kernel: br0: port 1(bond0) entered forwarding state Oct 13 20:48:40 Athena dhcpcd[1891]: br0: rebinding lease of 192.168.1.2 Oct 13 20:48:41 Athena dhcpcd[1891]: br0: probing address 192.168.1.2/24 Oct 13 20:48:47 Athena dhcpcd[1891]: br0: leased 192.168.1.2 for 86400 seconds Oct 13 20:48:47 Athena dhcpcd[1891]: br0: adding route to 192.168.1.0/24 Oct 13 20:48:47 Athena dhcpcd[1891]: br0: adding default route via 192.168.1.1 Oct 13 20:48:48 Athena ntpd[1952]: Listen normally on 14 br0 192.168.1.2:123 I noticed that my server is occasionally doing a sort of "hiccup" behavior where it will stop responding to pings and the webUI entirely for somewhere between 10 and 30s.... Usually when I notice this, I assume the server has fully crashed since that is the error I am trying to diagnose. Sometimes the connection returns again without crashing. I've attached my diags as well. athena-diagnostics-20201013-2053.zip
