codearoni
-
Posts
37 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by codearoni
-

Fix Common Problems - Parity has read errors
codearoni replied to WannabeMKII's topic in General Support
Hey! Another WD Red user! See my thread from a couple of weeks ago. The extended SMART results mean different things for different brands of drives. I'll let someone more knowledgeable than me confirm, but your drive might need replacement. -
No worries trurl, I imagine you're managing thousands of threads on this board lol. I've begun a rebuild but it'll take 12 hours. Probably tomorrow I'll pop on and update the OP with a summary of steps taken for these particular drives (WD Red Plus).
-
Right on, ty itimpi! So as a general rule of thumbs: adding multiple data drives at once = fine. Adding data + parity drives = not (do them as separate tasks). Makes sense. I'm just a new user and don't want to make any assumptions as to how unraid operates.
-
Thanks trurl. Just to be clear: I'll be moving from 1x Parity and 3x Data drives to 2x Parity and 4x Data drives. Sounds like adding a 2nd parity will require a rebuild on Parity #1...so I might be better off doing #1, just adding the replacement data disk and rebuilding the array. Then afterwards, spinning down the array, and adding Parity #2 and Data #4?
-
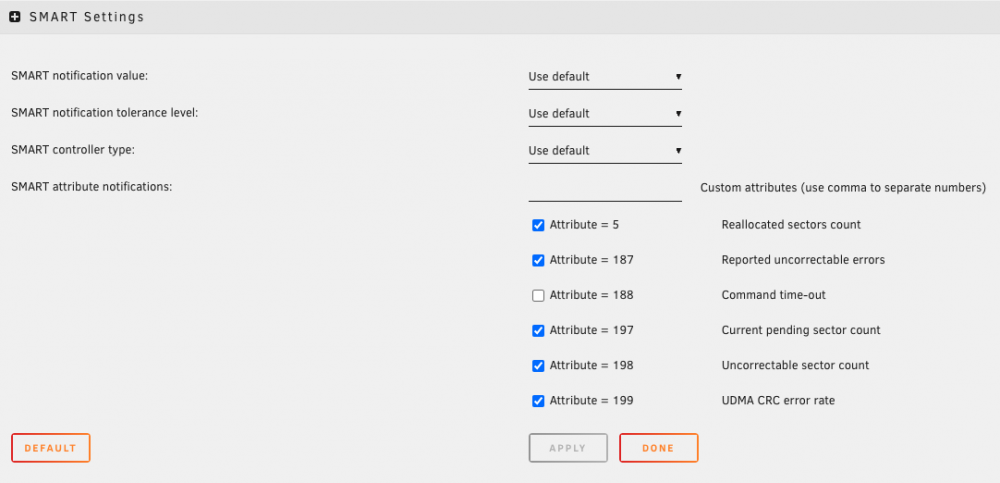
Thanks trurl. Looks good now. I was making it more complicated than it needed to be. (i.e. "Attribute = 0" trying to match the checkboxes below). Final question: I'll be rebuilding the array soon. I am adding a 2nd parity drive and one more storage drive. Should I: 1) spin up the array with the replacement disk ONLY, and rebuild FIRST - followed by spinning down the array, and adding the new drives. or 2) spin up the array with the replacement disk, plus the new drives, and rebuild all together. Couldn't find any documentation on this particular scenario in the wiki. I would prefer to do #2 as I imagine it'll be faster, but am obviously interested in doing this correctly moreso than quickly.
-
Hi trurl! While I've been waiting on my RMA'd disk, I've been looking into setting up Unraid to monitor said attribute for my WD Red drives. I've looked at the wiki plus these forums, but am unsure how to add monitoring as discussed above. I assume I go to the disk page, and enter a custom attribute (screenshot of what I'm talking about attached)? Is this correct? What would the syntax for this custom attribute look like?
-
Just an update: I spun down the array and removed the disk. It's currently in RMA. After I get the replacement I'll start a rebuild. When it's all said and done, I'll update the OP with my steps used to triage this issue. Hoping it'll help future WD Red owners.
-
Roger. Thank you so much Trurl! Just for my own notes and knowledge: can you briefly describe what you're seeing. Would a healthy disc have "000" for all of those fields?
-
Attached is my smart report for disk1. The text below the report download says "Completed without error" alexandria-smart-20201117-0817.zip
-
Just posting an update: extended SMART is still at 40%. Might not have results ready until tomorrow. Thanks again for meandering this issue with me trurl
-
Attaching. Thank you trurl! alexandria-diagnostics-20201116-1414.zip
-
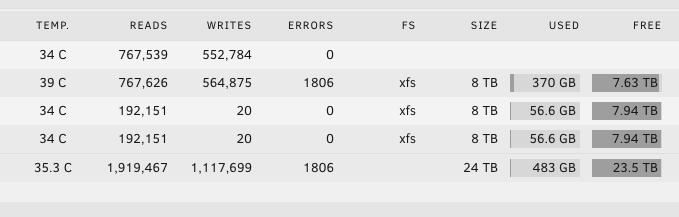
Solution: If you own WD Red Plus drives, and you're experiencing Errors - perform the following steps: 1) Run an Extended SMART test on the drive that is error'ing. 2) Download the SMART results when it's complete and check Raw_Read_Error_Rate in the .txt file 3) Raw_Read_Error_Rate should be zero for WD Red Plus drives specifically (this statement is not true for all HDD's, ask for help if you're using a different type of drive)! 4) If the Raw_Read_Error_Rate is not zero, your Red Plus drive will need replacing. RMA it if under warranty. 5) For extra certainty, run an Extended SMART test on the replacement drive to ensure it's working as expected. 6) Add "1,200" (no quotes) to the Smart Attribute Notifications of your WD Red Plus drives (textbox next to "Custom Attributes") OP Below: Hi all! New Unraid user here. Everything has been working swimmingly up until my first mover job (cache dumping contents onto spinny plates). My disk1 is receiving a crazy mount of errors, screenshot: This system, including all the drives are brand new. I downloaded my diagnostics, and found thousands of these in the syslog.txt Nov 16 10:08:58 Alexandria kernel: md: disk1 read error, sector=15032479712 Nov 16 10:08:58 Alexandria kernel: md: disk1 read error, sector=15032479720 Nov 16 10:08:58 Alexandria kernel: md: disk1 read error, sector=15032479728 Nov 16 10:08:58 Alexandria kernel: md: disk1 read error, sector=15032479736 Nov 16 10:08:58 Alexandria kernel: md: disk1 read error, sector=15032479744 Nov 16 10:08:58 Alexandria kernel: md: disk1 read error, sector=15032479752 I'm currently running the SMART extended self-test on disk1. Results TBD. My question is: Is disk1 bunk? Given the fact that all the drives are fresh off the press, so to speak, I would expect zero errors. Could there be a software reason for all these errors, outside of a bad disk? Looking for help here before moving forward with an RMA. Cheers!