




ThreeFN
Members
-
Joined
-
Last visited
-
I'm no expert on external triggers, but given that restarting the ZM docker DOESN'T fix the issue, and restarting the whole server DOES, which presumably restarts whatever is creating/starting the trigger, I would look more in depth at how/what is starting the trigger, it may not be 'stopping' appropriately or otherwise causing a conflict. My 2 cents, other opinions are available.
-
Any chance something in your memory allocation changed? Not enough memory allocated for your camera/frame buffer size is a common pitfall (granted you updated from working config), zmMemAttach sounds like may indicated a memory issue. Memory has certainly bit me enough times...
-
Small PSA on mocord and zmninja and notifications. If you run Mocord, by default you get recordings every 10 minutes. zmninja/eventserver ties notifications to the event ID, so that if multiple motion events trigger within the same 10 minute window, you will only receive the first notification and in the timeline you will only see the 10 minute chunks. The workaround I found here: You can find the aforementioned setting under CONFIG and the help section
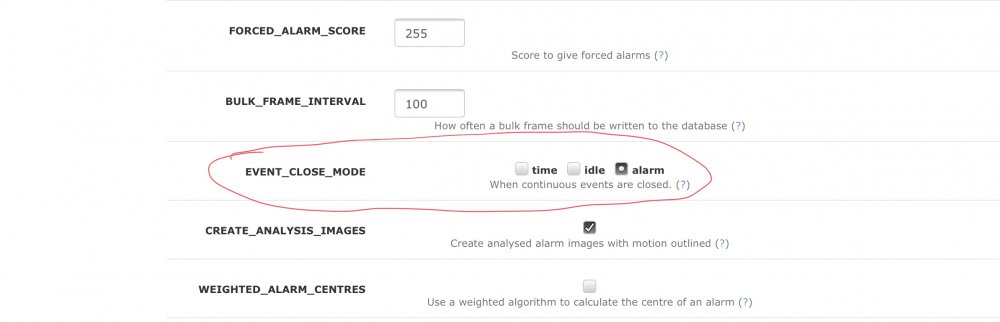
-
Unfortunately, this may be unifi controller type situation all over again, where 'a solution' (but not easy, fun, or making @dlandon's life any easier) is versioning so people can lock in a 'last working version', but that's an ugly matrix of versions, ZM ver + ES Ver + ?opencv? = exponential growth.
-
You need to go into your camera config and change how it records, read the ZM documentation for more details on what does what: Yah, there's a lot going on, I don't pretend to have found it all, mlapi isn't designed to be completely on a remote device just yet, reading between the lines it seems one reason for making the api was so that the ML models could stay in memory so they don't have to be loaded each time, which apparently they have to be loaded on each 'image check' for one reason or another? I'm not a code monkey to catch evverything, only know enough to be dangerous. Never doubted it was a octopus crossed with an ivy tressel of a project, probably never really capable nor intended to run this way. Put it on a resume for those that can begin to understand what all zm ml docker has to do. I'll be honest, I've always played with ML each time I refactored my 'server solutions' as I would get bored/annoyed with current solution, but would inevitably roll back to no ML and just ZM record 24/7, sometimes with this docker, sometimes a vm, sometimes freenas/truenas plugin (don't start me on that one). Lets be honest a cctv system is 'only good' if it A) records everything, and B) never misses anything and C) that in a pinch you could go back and find if you had to in case of breakin/theft etc. Everything else is sex appeal and gravy, as fantastic and valuable as it can be, and I can't fault anyone buying/building a race car when you only need a honda/toyota to get around . This last 'install' for me was probably the first time I had the confluence of knowledge, understanding, documentation, examples, code state, luck, and so on to get it all working and work in a way that wouldn't be an annoyance with zmninja/etc. And then it shutters (which I do not fault). But I probably owe you a few pints for the entertainment value, you're right. Again, the only real annoyance for me being told 'you're on your own' in the end is that docker, right now, is probably the 'easiest' way to share gpu power (caveat emptor) amongst home server tasks (plex,ml,tinkering,etc) but not as easy as spooling a VM from the development/deployment standpoint. I'll have to investigate this. I remember early days docker (for me) not understanding how docker is designed to be immutable, messing around inside docker, updating/upgrading it, and then wondering 'where did all the stuff I did go?' If this ends up being a solution one will have to be VERY careful not to accidentally kill this docker with an update/upgrade etc.
-
Unfortunately I spoke too soon. If I had read the FAQ with more comprehension, the current mlapi implementation still requires most if not all of the ML libraries be installed on the ZM install, so that isn't a solution just yet. The mlapi docker hasn't been updated in 7 months but you will probably have to setup/build the docker yourself because of the compile requirements of opencv so I don't think one click install app version of a ML docker is in the cards for most unraid users. A VM following the instructions would therefore be 'easier' for most users. And to continue to rain on the parade, it looks like the Google Coral TPU isn't really an interchangeable processor like Yolo and cpu/gpu, the coral runs different models and has a different performance profile (faster but less successful detections) and is more used as a separate suit of detectors, ,like object vs face vs alpr etc. I'm not entirely sure what all objects tpu can detect to be honest, it may or may not be the same list as the yolo list. So It's going to have to be a separate GPU and a VM for the foreseeable future if one wants 'max performance', at a TPU if you're curious, and wait for pliablepixels to continue development on the MLAPI advancing to a less kludgy (his words) implementation.
-
If it 'went back down' it would seem that it was temp files, perhaps package updates or something. Your database should be stashed in appdata so that shouldn't grow the image unless it's mirrored over for some reason. It does seem odd that your 1 day change originally was 'exactly' doubling in size, from 3.31GB to 6.62GB which seems more than coincidental. For reference I'm running 3.06GiB image for my 222GiB of video at the moment.
-
If it's still growing, My next best guess is that ZM config may have an error in it. Have you changed this? Does the rate of growth of the container match your expected rate of recorded video? Your config and run command looks correct to me. /mnt/disks/cctv/zoneminder has files in it, but does it have the LATEST files and ALL the files? If the cctv disk wasn't mounted at one point when the docker started some files might go into the image instead, I'm pretty sure I goofed and broke things that way one time.

-
Remind me again what's giving you this image/readout? I'm struggling today. EDIT: Oh FFS, 2 seconds after I post of course it comes to me, (Container Sizes) button on Docker page...(grumble grumble)
-
This is all the same problem. /EDIT (this sentence didn't leave my head) your ZM storage location needs to be corrected. /EDIT. /appdata/zoneminder/data is the default storage location for video/images that zoneminder stores. ZM will delete when (default 95%?) full, go to the filters tab in ZM and you can adjust. I highly recommend setting up a quota system to limit ZM's storage area, and recommend even more setting up an unassigned drive to be your video only storage. Unraid doesn't do quota's in the normal sense (this share shall be XXXGiB in size) so you'll have to do your own research on how to accomplish this. I use a separate unassigned drive for ZM storage (technically on another server). Keep in mind the 'until full' filter in ZM is just based on free space on your drive. If you add other stuff to the drive it will eat from your ZM storage. Again I don't recommend storing ZM footage on you main array, give it it's own drive/partition/etc to itself.
-
Are you trying to limit the RAM the container needs or the storage of video files on your array?
-
ES does support remote ML server as described here. Which if you go down the rabit hole, you get pliablepixels mlapi software, which does have a containerized version someone has made (and may have GPU support?). It may be possible even now to glue this all together. Obviously experimentation must ensue. The more I dig through stuff the more I tend to agree with dlandon that this container is doing a lot of 'init install' stuff that is more OS/VM behavior than docker pull/start behavior and I don't fault wanting to kick that to the curb. Having said that ZM is 'almost exclusively made useful' by ES's ML stuff for false positive rejection, so no ML = no ZM for me. So at the moment it looks like the options are spin up a VM and get a well supported installation (pliablepixels documentation), or investigate the aforementioned remote ML docker. My preference is for the latter because at the moment, containerization is about the only way in unraid to spread a GPU amongst multiple work loads (eg plex & ML) unless/until vGPU/SRIOV/etc support is added and VMs & docker can share. I guess the other solution would be to move ML processing to a Google Coral device, and give that device to the ZM VM. Or even go the route of a TPU & mlapi VM remoted to the ZM docker. The benchmarks seem to indicate the TPU is good but maybe hamstrung a bit by it's usb 2.0 (or slower) interface to get the data. Not sure if the M.2 versions would be any faster, if TPU can't saturate 2.0 that seem like the chip is the bottleneck and not it's interface... Hell of a device for the cost, size, and power draw though... Dlandon, I'm guessing you'll be dropping GPU support entirely from the docker? Like even for ffmpeg use directly by ZM and not for ML (h.264 decode etc)? Or is that something that doesn't require your direct support (give container gpu, ffmpeg sorts it out) and will work on its own?
-
I think I may have figured it out for some (most?) people having these problems, maybe? A) dlandon is right, you really need to go into the configs (specifically objectconfig.ini) and understand (at least somewhat) what is going on in there. Everyone's config is a little different (Yolo v3 or v4? tiny or not? cpu, gpu, or tpu?, etc) and will need to be setup for what hardware/software you're using. B) the default [object] section looks like this: [object] # If you are using legacy format (use_sequence=no) then these parameters will # be used during ML inferencing object_detection_pattern=(person|car|motorbike|bus|truck|boat) object_min_confidence=0.3 object_framework=coral_edgetpu object_processor=tpu object_weights={{base_data_path}}/models/coral_edgetpu/ssd_mobilenet_v2_coco_quant_postprocess_edgetpu.tflite object_labels={{base_data_path}}/models/coral_edgetpu/coco_indexed.names # If you are using the new ml_sequence format (use_sequence=yes) then # you can fiddle with these parameters and look at ml_sequence later # Note that these can be named anything. You can add custom variables, ad-infinitum # Google Coral tpu_object_weights={{base_data_path}}/models/coral_edgetpu/ssd_mobilenet_v2_coco_quant_postprocess_edgetpu.tflite tpu_object_labels={{base_data_path}}/models/coral_edgetpu/coco_indexed.names tpu_object_framework=coral_edgetpu tpu_object_processor=tpu tpu_min_confidence=0.6 # Yolo v4 on GPU (falls back to CPU if no GPU) yolo4_object_weights={{base_data_path}}/models/yolov4/yolov4.weights yolo4_object_labels={{base_data_path}}/models/yolov4/coco.names yolo4_object_config={{base_data_path}}/models/yolov4/yolov4.cfg yolo4_object_framework=opencv yolo4_object_processor=gpu # Yolo v3 on GPU (falls back to CPU if no GPU) yolo3_object_weights={{base_data_path}}/models/yolov3/yolov3.weights yolo3_object_labels={{base_data_path}}/models/yolov3/coco.names yolo3_object_config={{base_data_path}}/models/yolov3/yolov3.cfg yolo3_object_framework=opencv yolo3_object_processor=gpu # Tiny Yolo V4 on GPU (falls back to CPU if no GPU) tinyyolo_object_config={{base_data_path}}/models/tinyyolov4/yolov4-tiny.cfg tinyyolo_object_weights={{base_data_path}}/models/tinyyolov4/yolov4-tiny.weights tinyyolo_object_labels={{base_data_path}}/models/tinyyolov4/coco.names tinyyolo_object_framework=opencv tinyyolo_object_processor=gpu these are basically configs for each of the different setups you might have with Yolo, cpu, gpu, tpu, etc. And looking at the default ML_SEQUENCE: ml_sequence= { 'general': { 'model_sequence': 'object,face,alpr', 'disable_locks': '{{disable_locks}}', }, 'object': { 'general':{ 'pattern':'{{object_detection_pattern}}', 'same_model_sequence_strategy': 'first' # also 'most', 'most_unique's }, 'sequence': [{ #First run on TPU with higher confidence 'object_weights':'{{tpu_object_weights}}', 'object_labels': '{{tpu_object_labels}}', 'object_min_confidence': {{tpu_min_confidence}}, 'object_framework':'{{tpu_object_framework}}', 'tpu_max_processes': {{tpu_max_processes}}, 'tpu_max_lock_wait': {{tpu_max_lock_wait}}, 'max_detection_size':'{{max_detection_size}}' }, { # YoloV4 on GPU if TPU fails (because sequence strategy is 'first') 'object_config':'{{yolo4_object_config}}', 'object_weights':'{{yolo4_object_weights}}', 'object_labels': '{{yolo4_object_labels}}', 'object_min_confidence': {{object_min_confidence}}, 'object_framework':'{{yolo4_object_framework}}', 'object_processor': '{{yolo4_object_processor}}', 'gpu_max_processes': {{gpu_max_processes}}, 'gpu_max_lock_wait': {{gpu_max_lock_wait}}, 'cpu_max_processes': {{cpu_max_processes}}, 'cpu_max_lock_wait': {{cpu_max_lock_wait}}, 'max_detection_size':'{{max_detection_size}}' }] }, 'face': { 'general':{ 'pattern': '{{face_detection_pattern}}', 'same_model_sequence_strategy': 'first' }, 'sequence': [{ 'save_unknown_faces':'{{save_unknown_faces}}', 'save_unknown_faces_leeway_pixels':{{save_unknown_faces_leeway_pixels}}, 'face_detection_framework': '{{face_detection_framework}}', 'known_images_path': '{{known_images_path}}', 'unknown_images_path': '{{unknown_images_path}}', 'face_model': '{{face_model}}', 'face_train_model': '{{face_train_model}}', 'face_recog_dist_threshold': '{{face_recog_dist_threshold}}', 'face_num_jitters': '{{face_num_jitters}}', 'face_upsample_times':'{{face_upsample_times}}', 'gpu_max_processes': {{gpu_max_processes}}, 'gpu_max_lock_wait': {{gpu_max_lock_wait}}, 'cpu_max_processes': {{cpu_max_processes}}, 'cpu_max_lock_wait': {{cpu_max_lock_wait}}, 'max_size':800 }] }, 'alpr': { 'general':{ 'same_model_sequence_strategy': 'first', 'pre_existing_labels':['car', 'motorbike', 'bus', 'truck', 'boat'], 'pattern': '{{alpr_detection_pattern}}' }, 'sequence': [{ 'alpr_api_type': '{{alpr_api_type}}', 'alpr_service': '{{alpr_service}}', 'alpr_key': '{{alpr_key}}', 'platrec_stats': '{{platerec_stats}}', 'platerec_min_dscore': {{platerec_min_dscore}}, 'platerec_min_score': {{platerec_min_score}}, 'max_size':1600 }] } } you see that the sequence sets things up to use the TPU first, then to try the yolo v4 on gpu. If TPU fails (it will in many cases cause I don't see a lot about people using Google Coral) it tries the next in the sequence which is yolo v4, so on and so forth. I assume I know why pliablepixels is doing it this way, he's trying to make the configs more robust so they work without modification; eg imagine a config that is 'try whatever processor the user may have in order of processing speed' (TPU > GPU > CPU) and one will work and successfully detect of what hardware the user is running. It also adds growth for more dectection methods other than object, face, alpr, etc in the future. This extensibility and multiple dectors may be conflicting with the container, which certainly in my case, I have setup to only compile one model (yolo v4 full) for CPU (waiting on 6.9 stable before I try GPU). Keep in mind ES doc etc is written for a OS install and not a container. I think that when the config says: # Yolo v4 on GPU (falls back to CPU if no GPU) It isn't strictly true, either opencv doesn't compile code to allow this to happen or something similar maybe. I changed: yolo4_object_processor=cpu And simplified ml_sequence to ml_sequence= { 'general': { #'model_sequence': 'object,face,alpr', 'model_sequence': 'object', 'disable_locks': '{{disable_locks}}', }, 'object':{ 'general':{ 'pattern':'{{object_detection_pattern}}', 'same_model_sequence_strategy': 'first' # also 'most', 'most_unique's }, 'sequence': [ { # YoloV4 on CPU only 'object_config':'{{yolo4_object_config}}', 'object_weights':'{{yolo4_object_weights}}', 'object_labels': '{{yolo4_object_labels}}', 'object_min_confidence': {{object_min_confidence}}, 'object_framework':'{{yolo4_object_framework}}', 'object_processor': '{{yolo4_object_processor}}', 'gpu_max_processes': {{gpu_max_processes}}, 'gpu_max_lock_wait': {{gpu_max_lock_wait}}, 'cpu_max_processes': {{cpu_max_processes}}, 'cpu_max_lock_wait': {{cpu_max_lock_wait}}, 'max_detection_size':'{{max_detection_size}}' }] } } And things started behaving. Yes technically the gpu_max could probably go as well but I was being small and deliberate in changes to make sure I didn't goof. Anyways these are my findings so far.
-
Ah, good to know, thanks for that, completely missed it. Then yes it's probably good it's gone as it frees up space a reduces confusion in the extra parameters field.
-
All of them are still applicable, they're docker parameters (you can have a google about them if you like). Unless I completely forgot that I added them myself, I thought that they were originally in the template but had fallen off for whatever reason.



