




ThreeFN
Members
-
Joined
-
Last visited
Everything posted by ThreeFN
-
I'm no expert on external triggers, but given that restarting the ZM docker DOESN'T fix the issue, and restarting the whole server DOES, which presumably restarts whatever is creating/starting the trigger, I would look more in depth at how/what is starting the trigger, it may not be 'stopping' appropriately or otherwise causing a conflict. My 2 cents, other opinions are available.
-
Any chance something in your memory allocation changed? Not enough memory allocated for your camera/frame buffer size is a common pitfall (granted you updated from working config), zmMemAttach sounds like may indicated a memory issue. Memory has certainly bit me enough times...
-
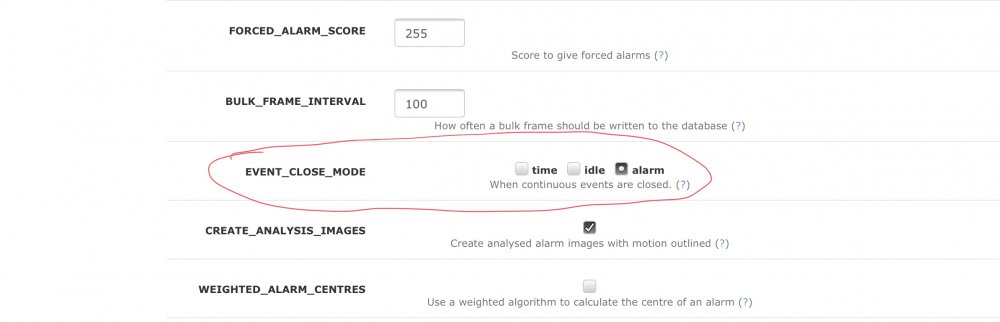
Small PSA on mocord and zmninja and notifications. If you run Mocord, by default you get recordings every 10 minutes. zmninja/eventserver ties notifications to the event ID, so that if multiple motion events trigger within the same 10 minute window, you will only receive the first notification and in the timeline you will only see the 10 minute chunks. The workaround I found here: You can find the aforementioned setting under CONFIG and the help section
-
Unfortunately, this may be unifi controller type situation all over again, where 'a solution' (but not easy, fun, or making @dlandon's life any easier) is versioning so people can lock in a 'last working version', but that's an ugly matrix of versions, ZM ver + ES Ver + ?opencv? = exponential growth.
-
You need to go into your camera config and change how it records, read the ZM documentation for more details on what does what: Yah, there's a lot going on, I don't pretend to have found it all, mlapi isn't designed to be completely on a remote device just yet, reading between the lines it seems one reason for making the api was so that the ML models could stay in memory so they don't have to be loaded each time, which apparently they have to be loaded on each 'image check' for one reason or another? I'm not a code monkey to catch evverything, only know enough to be dangerous. Never doubted it was a octopus crossed with an ivy tressel of a project, probably never really capable nor intended to run this way. Put it on a resume for those that can begin to understand what all zm ml docker has to do. I'll be honest, I've always played with ML each time I refactored my 'server solutions' as I would get bored/annoyed with current solution, but would inevitably roll back to no ML and just ZM record 24/7, sometimes with this docker, sometimes a vm, sometimes freenas/truenas plugin (don't start me on that one). Lets be honest a cctv system is 'only good' if it A) records everything, and B) never misses anything and C) that in a pinch you could go back and find if you had to in case of breakin/theft etc. Everything else is sex appeal and gravy, as fantastic and valuable as it can be, and I can't fault anyone buying/building a race car when you only need a honda/toyota to get around . This last 'install' for me was probably the first time I had the confluence of knowledge, understanding, documentation, examples, code state, luck, and so on to get it all working and work in a way that wouldn't be an annoyance with zmninja/etc. And then it shutters (which I do not fault). But I probably owe you a few pints for the entertainment value, you're right. Again, the only real annoyance for me being told 'you're on your own' in the end is that docker, right now, is probably the 'easiest' way to share gpu power (caveat emptor) amongst home server tasks (plex,ml,tinkering,etc) but not as easy as spooling a VM from the development/deployment standpoint. I'll have to investigate this. I remember early days docker (for me) not understanding how docker is designed to be immutable, messing around inside docker, updating/upgrading it, and then wondering 'where did all the stuff I did go?' If this ends up being a solution one will have to be VERY careful not to accidentally kill this docker with an update/upgrade etc.
-
Unfortunately I spoke too soon. If I had read the FAQ with more comprehension, the current mlapi implementation still requires most if not all of the ML libraries be installed on the ZM install, so that isn't a solution just yet. The mlapi docker hasn't been updated in 7 months but you will probably have to setup/build the docker yourself because of the compile requirements of opencv so I don't think one click install app version of a ML docker is in the cards for most unraid users. A VM following the instructions would therefore be 'easier' for most users. And to continue to rain on the parade, it looks like the Google Coral TPU isn't really an interchangeable processor like Yolo and cpu/gpu, the coral runs different models and has a different performance profile (faster but less successful detections) and is more used as a separate suit of detectors, ,like object vs face vs alpr etc. I'm not entirely sure what all objects tpu can detect to be honest, it may or may not be the same list as the yolo list. So It's going to have to be a separate GPU and a VM for the foreseeable future if one wants 'max performance', at a TPU if you're curious, and wait for pliablepixels to continue development on the MLAPI advancing to a less kludgy (his words) implementation.
-
If it 'went back down' it would seem that it was temp files, perhaps package updates or something. Your database should be stashed in appdata so that shouldn't grow the image unless it's mirrored over for some reason. It does seem odd that your 1 day change originally was 'exactly' doubling in size, from 3.31GB to 6.62GB which seems more than coincidental. For reference I'm running 3.06GiB image for my 222GiB of video at the moment.
-
If it's still growing, My next best guess is that ZM config may have an error in it. Have you changed this? Does the rate of growth of the container match your expected rate of recorded video? Your config and run command looks correct to me. /mnt/disks/cctv/zoneminder has files in it, but does it have the LATEST files and ALL the files? If the cctv disk wasn't mounted at one point when the docker started some files might go into the image instead, I'm pretty sure I goofed and broke things that way one time.

-
Remind me again what's giving you this image/readout? I'm struggling today. EDIT: Oh FFS, 2 seconds after I post of course it comes to me, (Container Sizes) button on Docker page...(grumble grumble)
-
This is all the same problem. /EDIT (this sentence didn't leave my head) your ZM storage location needs to be corrected. /EDIT. /appdata/zoneminder/data is the default storage location for video/images that zoneminder stores. ZM will delete when (default 95%?) full, go to the filters tab in ZM and you can adjust. I highly recommend setting up a quota system to limit ZM's storage area, and recommend even more setting up an unassigned drive to be your video only storage. Unraid doesn't do quota's in the normal sense (this share shall be XXXGiB in size) so you'll have to do your own research on how to accomplish this. I use a separate unassigned drive for ZM storage (technically on another server). Keep in mind the 'until full' filter in ZM is just based on free space on your drive. If you add other stuff to the drive it will eat from your ZM storage. Again I don't recommend storing ZM footage on you main array, give it it's own drive/partition/etc to itself.
-
Are you trying to limit the RAM the container needs or the storage of video files on your array?
-
ES does support remote ML server as described here. Which if you go down the rabit hole, you get pliablepixels mlapi software, which does have a containerized version someone has made (and may have GPU support?). It may be possible even now to glue this all together. Obviously experimentation must ensue. The more I dig through stuff the more I tend to agree with dlandon that this container is doing a lot of 'init install' stuff that is more OS/VM behavior than docker pull/start behavior and I don't fault wanting to kick that to the curb. Having said that ZM is 'almost exclusively made useful' by ES's ML stuff for false positive rejection, so no ML = no ZM for me. So at the moment it looks like the options are spin up a VM and get a well supported installation (pliablepixels documentation), or investigate the aforementioned remote ML docker. My preference is for the latter because at the moment, containerization is about the only way in unraid to spread a GPU amongst multiple work loads (eg plex & ML) unless/until vGPU/SRIOV/etc support is added and VMs & docker can share. I guess the other solution would be to move ML processing to a Google Coral device, and give that device to the ZM VM. Or even go the route of a TPU & mlapi VM remoted to the ZM docker. The benchmarks seem to indicate the TPU is good but maybe hamstrung a bit by it's usb 2.0 (or slower) interface to get the data. Not sure if the M.2 versions would be any faster, if TPU can't saturate 2.0 that seem like the chip is the bottleneck and not it's interface... Hell of a device for the cost, size, and power draw though... Dlandon, I'm guessing you'll be dropping GPU support entirely from the docker? Like even for ffmpeg use directly by ZM and not for ML (h.264 decode etc)? Or is that something that doesn't require your direct support (give container gpu, ffmpeg sorts it out) and will work on its own?
-
I think I may have figured it out for some (most?) people having these problems, maybe? A) dlandon is right, you really need to go into the configs (specifically objectconfig.ini) and understand (at least somewhat) what is going on in there. Everyone's config is a little different (Yolo v3 or v4? tiny or not? cpu, gpu, or tpu?, etc) and will need to be setup for what hardware/software you're using. B) the default [object] section looks like this: [object] # If you are using legacy format (use_sequence=no) then these parameters will # be used during ML inferencing object_detection_pattern=(person|car|motorbike|bus|truck|boat) object_min_confidence=0.3 object_framework=coral_edgetpu object_processor=tpu object_weights={{base_data_path}}/models/coral_edgetpu/ssd_mobilenet_v2_coco_quant_postprocess_edgetpu.tflite object_labels={{base_data_path}}/models/coral_edgetpu/coco_indexed.names # If you are using the new ml_sequence format (use_sequence=yes) then # you can fiddle with these parameters and look at ml_sequence later # Note that these can be named anything. You can add custom variables, ad-infinitum # Google Coral tpu_object_weights={{base_data_path}}/models/coral_edgetpu/ssd_mobilenet_v2_coco_quant_postprocess_edgetpu.tflite tpu_object_labels={{base_data_path}}/models/coral_edgetpu/coco_indexed.names tpu_object_framework=coral_edgetpu tpu_object_processor=tpu tpu_min_confidence=0.6 # Yolo v4 on GPU (falls back to CPU if no GPU) yolo4_object_weights={{base_data_path}}/models/yolov4/yolov4.weights yolo4_object_labels={{base_data_path}}/models/yolov4/coco.names yolo4_object_config={{base_data_path}}/models/yolov4/yolov4.cfg yolo4_object_framework=opencv yolo4_object_processor=gpu # Yolo v3 on GPU (falls back to CPU if no GPU) yolo3_object_weights={{base_data_path}}/models/yolov3/yolov3.weights yolo3_object_labels={{base_data_path}}/models/yolov3/coco.names yolo3_object_config={{base_data_path}}/models/yolov3/yolov3.cfg yolo3_object_framework=opencv yolo3_object_processor=gpu # Tiny Yolo V4 on GPU (falls back to CPU if no GPU) tinyyolo_object_config={{base_data_path}}/models/tinyyolov4/yolov4-tiny.cfg tinyyolo_object_weights={{base_data_path}}/models/tinyyolov4/yolov4-tiny.weights tinyyolo_object_labels={{base_data_path}}/models/tinyyolov4/coco.names tinyyolo_object_framework=opencv tinyyolo_object_processor=gpu these are basically configs for each of the different setups you might have with Yolo, cpu, gpu, tpu, etc. And looking at the default ML_SEQUENCE: ml_sequence= { 'general': { 'model_sequence': 'object,face,alpr', 'disable_locks': '{{disable_locks}}', }, 'object': { 'general':{ 'pattern':'{{object_detection_pattern}}', 'same_model_sequence_strategy': 'first' # also 'most', 'most_unique's }, 'sequence': [{ #First run on TPU with higher confidence 'object_weights':'{{tpu_object_weights}}', 'object_labels': '{{tpu_object_labels}}', 'object_min_confidence': {{tpu_min_confidence}}, 'object_framework':'{{tpu_object_framework}}', 'tpu_max_processes': {{tpu_max_processes}}, 'tpu_max_lock_wait': {{tpu_max_lock_wait}}, 'max_detection_size':'{{max_detection_size}}' }, { # YoloV4 on GPU if TPU fails (because sequence strategy is 'first') 'object_config':'{{yolo4_object_config}}', 'object_weights':'{{yolo4_object_weights}}', 'object_labels': '{{yolo4_object_labels}}', 'object_min_confidence': {{object_min_confidence}}, 'object_framework':'{{yolo4_object_framework}}', 'object_processor': '{{yolo4_object_processor}}', 'gpu_max_processes': {{gpu_max_processes}}, 'gpu_max_lock_wait': {{gpu_max_lock_wait}}, 'cpu_max_processes': {{cpu_max_processes}}, 'cpu_max_lock_wait': {{cpu_max_lock_wait}}, 'max_detection_size':'{{max_detection_size}}' }] }, 'face': { 'general':{ 'pattern': '{{face_detection_pattern}}', 'same_model_sequence_strategy': 'first' }, 'sequence': [{ 'save_unknown_faces':'{{save_unknown_faces}}', 'save_unknown_faces_leeway_pixels':{{save_unknown_faces_leeway_pixels}}, 'face_detection_framework': '{{face_detection_framework}}', 'known_images_path': '{{known_images_path}}', 'unknown_images_path': '{{unknown_images_path}}', 'face_model': '{{face_model}}', 'face_train_model': '{{face_train_model}}', 'face_recog_dist_threshold': '{{face_recog_dist_threshold}}', 'face_num_jitters': '{{face_num_jitters}}', 'face_upsample_times':'{{face_upsample_times}}', 'gpu_max_processes': {{gpu_max_processes}}, 'gpu_max_lock_wait': {{gpu_max_lock_wait}}, 'cpu_max_processes': {{cpu_max_processes}}, 'cpu_max_lock_wait': {{cpu_max_lock_wait}}, 'max_size':800 }] }, 'alpr': { 'general':{ 'same_model_sequence_strategy': 'first', 'pre_existing_labels':['car', 'motorbike', 'bus', 'truck', 'boat'], 'pattern': '{{alpr_detection_pattern}}' }, 'sequence': [{ 'alpr_api_type': '{{alpr_api_type}}', 'alpr_service': '{{alpr_service}}', 'alpr_key': '{{alpr_key}}', 'platrec_stats': '{{platerec_stats}}', 'platerec_min_dscore': {{platerec_min_dscore}}, 'platerec_min_score': {{platerec_min_score}}, 'max_size':1600 }] } } you see that the sequence sets things up to use the TPU first, then to try the yolo v4 on gpu. If TPU fails (it will in many cases cause I don't see a lot about people using Google Coral) it tries the next in the sequence which is yolo v4, so on and so forth. I assume I know why pliablepixels is doing it this way, he's trying to make the configs more robust so they work without modification; eg imagine a config that is 'try whatever processor the user may have in order of processing speed' (TPU > GPU > CPU) and one will work and successfully detect of what hardware the user is running. It also adds growth for more dectection methods other than object, face, alpr, etc in the future. This extensibility and multiple dectors may be conflicting with the container, which certainly in my case, I have setup to only compile one model (yolo v4 full) for CPU (waiting on 6.9 stable before I try GPU). Keep in mind ES doc etc is written for a OS install and not a container. I think that when the config says: # Yolo v4 on GPU (falls back to CPU if no GPU) It isn't strictly true, either opencv doesn't compile code to allow this to happen or something similar maybe. I changed: yolo4_object_processor=cpu And simplified ml_sequence to ml_sequence= { 'general': { #'model_sequence': 'object,face,alpr', 'model_sequence': 'object', 'disable_locks': '{{disable_locks}}', }, 'object':{ 'general':{ 'pattern':'{{object_detection_pattern}}', 'same_model_sequence_strategy': 'first' # also 'most', 'most_unique's }, 'sequence': [ { # YoloV4 on CPU only 'object_config':'{{yolo4_object_config}}', 'object_weights':'{{yolo4_object_weights}}', 'object_labels': '{{yolo4_object_labels}}', 'object_min_confidence': {{object_min_confidence}}, 'object_framework':'{{yolo4_object_framework}}', 'object_processor': '{{yolo4_object_processor}}', 'gpu_max_processes': {{gpu_max_processes}}, 'gpu_max_lock_wait': {{gpu_max_lock_wait}}, 'cpu_max_processes': {{cpu_max_processes}}, 'cpu_max_lock_wait': {{cpu_max_lock_wait}}, 'max_detection_size':'{{max_detection_size}}' }] } } And things started behaving. Yes technically the gpu_max could probably go as well but I was being small and deliberate in changes to make sure I didn't goof. Anyways these are my findings so far.
-
Ah, good to know, thanks for that, completely missed it. Then yes it's probably good it's gone as it frees up space a reduces confusion in the extra parameters field.
-
All of them are still applicable, they're docker parameters (you can have a google about them if you like). Unless I completely forgot that I added them myself, I thought that they were originally in the template but had fallen off for whatever reason.
-
Just an FYI I noticed that the log file limitations that were in place have gone away from the template. Extra Parameters: --log-opt max-file=1 --log-out max-size=50m I know it probably junked up/confused the field that users would be adjusting the shared mem, but zoneminder will probably make some huge log files given the chance. Also a PSA, I recommend users add a cpu usage limit to the container, specifically when using object detect because of the opencv compile, which can lock up your server when it uses 100% CPU to compile. I'd recommend N-2 at most, where N is your cpu's threads so you leave 2 threads for all your other stuff to run on while ZM compiles. The number can be a float so fraction of threads is allowed. Extra Parameters: --cpus=X.X
-
Yes, it is exposed to the internet, you have to be exposed in order for zmninja to work 'as intended' getting picture notifications and the like. I was working on the assumption that you wanted certs because you wanted SSL, https, etc. I'm pretty sure you can't have a SWAG cert on your LAN because the cert has to be for a domain (eg yourdomain.url), and said domain has to be authenticated from an external source (ie cloudflare server on the net, it has to check you own the domain). There may be some way to point your router so that swag can authenticate your domain but then you only serve your domain on your LAN, but I haven't played with that sort of config. You can't have a cert for your LAN IP range eg 192.168.0.0 or 10.0.0.0 etc because they're not domains. dlandon, may I ask the mechanics of the shared memory setting for my edification? Trying to cross reference my understanding with this FAQ and the memory math wiki. Is it strictly necessary to tune it so that /dev/shm shows 50% in ZM, or could you tune it to leave 20% (80% used) as recommended in memory math wiki? Or are there temporary memory execs that you should leave 50% available for? Or does it really not matter to set it to 50% because any unused memory (the 20/50% that remains) isn't occupied and still available to the system anyways? Cheers mate, appreciate the work yourself and pliablepixels do.
-
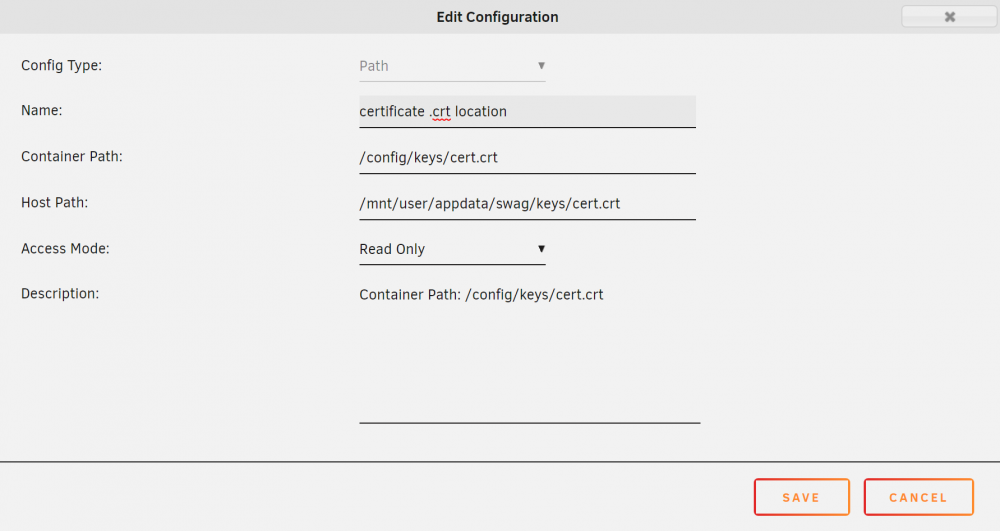
Yes. Not sure if this is best practice, but here's what I have configured and working: 1. You need to own your own domain so you can assign zoneminder.YOURDOMAIN.ETC 2. Also I have both SWAG and ZM on a separate bridged network per spaceinvanderone's video(s) (along with other stuff). 3. Assign a wildcard cert to yourself so you don't need more than one cert. 4. Point zoneminder's cert folder contents to your swag certs as below: 5. Make sure you setup as read only on both, just in case So far this works fine for me and doesn't seem to have any serious security faux pas. I'm pretty sure if your using a duckdns style setup that this will work with your subdomain only cert setup because ZM uses a subfolder, but I haven't used/setup that sort of config. Obviously this only covers ZM getting the cert and not swag rev proxy, for that I used the following for my subdomain config, which is basically the default subdomain config: zoneminder.subdomain.conf : server { listen 443 ssl; listen [::]:443 ssl; server_name zoneminder.*; include /config/nginx/ssl.conf; client_max_body_size 0; # enable for ldap auth, fill in ldap details in ldap.conf # include /config/nginx/ldap.conf; # enable for Authelia # include /config/nginx/authelia-server.conf; location / { # enable the next two lines for http auth #auth_basic "Restricted"; #auth_basic_user_file /config/nginx/.htpasswd; # enable the next two lines for ldap auth #auth_request /auth; #error_page 401 =200 /ldaplogin; # enable for Authelia # include /config/nginx/authelia-location.conf; include /config/nginx/proxy.conf; resolver 127.0.0.11 valid=30s; set $upstream_app zoneminder; set $upstream_port 443; set $upstream_proto https; proxy_pass $upstream_proto://$upstream_app:$upstream_port; # REMOVE THIS LINE BEFORE SUBMITTING: Additional proxy settings such as headers go below this line, leave the blank line above. } }

-
This seems to be the fix for the time being: https://github.com/dlandon/zoneminder/issues/145
-
Hate to trouble people with what I'm sure is me missing something in a config somewhere, but I'm completely stumped why I can't get object recognition working. Context: -Starting with a working ZM with notifications, images in notifications, proper SSL, basic revprox, etc. all that works. -I enable hooks and then no notifications, etc -Just trying to start simple with CPU opencv, Yolo v3 from the default in the objectconfig.ini, comment out monitor-999 stuff at the end -running in modect for now for debugging (notifications like having unique video sessions hence modect, mocord can make multiple triggers point to the same video session Iand then you don't get the new notification because you already 'read' that ID, end of that tangent) -I get the following in the logs: Dec 10 11:15:29 bda7008c85ba zma_m1[991]: INF [zma_m1] [Monitor-1: 2250 - Gone into alarm state PreAlarmCount: 0 > AlarmFrameCount:1 Cause:Forced Web] Dec 10 11:15:29 bda7008c85ba zma_m1[991]: INF [zma_m1] [Monitor-1: 2250 - Opening new event 49, alarm start] Dec 10 11:15:29 bda7008c85ba zmc_m1[986]: INF [zmc_m1] [Opening video storage stream /var/cache/zoneminder/events/1/2020-12-10/49/49-video.mp4 format: mp4] Dec 10 11:15:29 bda7008c85ba zmc_m1[986]: INF [zmc_m1] [some options not used, turn on debugging for a list.] Dec 10 11:15:29 bda7008c85ba zmc_m1[986]: INF [zmc_m1] [Event video offset is -1.735 sec (<0 means video starts early)] Dec 10 11:15:30 bda7008c85ba zmc_m1[986]: INF [zmc_m1] [Monitor-1: images:2300 - Capturing at 10.00 fps, capturing bandwidth 51431bytes/sec] Dec 10 11:15:31 bda7008c85ba zmeventnotification[1019]: INF [PARENT: New event 49 reported for Monitor:1 (Name:Monitor-1) Forced Web[last processed eid:48]] Dec 10 11:15:34 bda7008c85ba zma_m1[991]: INF [zma_m1] [Monitor-1: 2300 - Analysing at 10.00 fps] Dec 10 11:15:34 bda7008c85ba zma_m1[991]: INF [zma_m1] [Monitor-1: 2302 - Gone into alert state] Dec 10 11:15:34 bda7008c85ba zma_m1[991]: INF [zma_m1] [Monitor-1: 2300 - Analysing at 10.00 fps] Dec 10 11:15:34 bda7008c85ba zma_m1[991]: INF [zma_m1] [Monitor-1: 2302 - Gone into alert state] Dec 10 11:15:37 bda7008c85ba zma_m1[991]: INF [zma_m1] [Monitor-1: 2328 - Left alarm state (49) - 83(52) images] Dec 10 11:15:37 bda7008c85ba zma_m1[991]: INF [zma_m1] [Monitor-1: 2328 - Closing event 49, alarm end] Dec 10 11:15:37 bda7008c85ba zma_m1[991]: INF [zma_m1] [Updating frames delta by -1.74 sec to match video file] Dec 10 11:15:37 bda7008c85ba zmeventnotification[1070]: INF [|----> FORK:Monitor-1 (1), eid:49 Event 49 for Monitor 1 has finished] Dec 10 11:15:40 bda7008c85ba zmc_m1[986]: INF [zmc_m1] [Monitor-1: images:2400 - Capturing at 10.00 fps, capturing bandwidth 55194bytes/sec] Dec 10 11:15:41 bda7008c85ba zmeventnotification[1070]: INF [|----> FORK:Monitor-1 (1), eid:49 Not sending event end alarm, as we did not send a start alarm for this, or start hook processing failed] Dec 10 11:15:44 bda7008c85ba zma_m1[991]: INF [zma_m1] [Monitor-1: 2400 - Analysing at 10.00 fps] Dec 10 11:15:50 bda7008c85ba zmc_m1[986]: INF [zmc_m1] [Monitor-1: images:2500 - Capturing at 10.00 fps, capturing bandwidth 71043bytes/sec] Which seems to indicate the detection isn't returning which probably could be from numerous potential errors, so I appreciate that probably isn't so helpful. For context there is a car parked in the cameras view, and once upon a time I remember getting object detection working (before I had revprox/images/etc working and long since killed/lost that config) and it said 'car 99%' or what have so I don't think the error is as daft as 'nothing was detected'. I dug around a little bit in configs looking for the 'flow path' and noticed the base_data_path default points to /var/lib/zmeventnotification, went looking in there (within the container console) and did not find the start or end .py files, which instead are stored in /config/hook. Tried changing base_data_path to /config/hook but no joy with that change (probably because the changing base_data_path breaks some other file locations). Like I said I'm probably just missing a part of the instructions that say 'oh yah you need to change this part of the default ES/hook config because this is in docker and defaults assume an OS' but I'm pretty stumped. Any help would be much appreciated. EDIT Well, I feel incredibly silly. Figured it out. Bit of background, one of my followup questions to the above problems was why it seemed like every time I loaded up the container, opencv would have to recompile. So in an effort to debug I had turned off 'hooks' and 'v3' options thinking 'well, maybe it only needs to install once, or the install scripts are bugged, or I've misconfiged them and they're bugged'. Then I though back to first principles of understanding docker and remembered that the container is transient, don't count on anything 'inside' the docker to survive shutdown, because you might update, change config, etc. Docker is built on that assumption. So I went back into the container config and turned hooks and yolov3 again, and it's at least preliminarily working, obviously I need some more tuning and config work to my application. In hind sight it makes total sense with what I realized next. What was probably happening is I was taking 'crimes of opportunity' when I was changing the config files, I probably was also tuning the --cpus= value in the container options because compiling was maxing out the CPU and 'soft crashing' unraid which is why I kept changing that value (and re-issuing the container, triggering a opencv recompile). Maybe sometimes I wouldn't change the container settings and it wouldn't recompile, but by that point I had learned to make a change and come back in 15 minutes and wasn't paying attention. So yah, only mess with your container or your configs, not both at the same time. Really, don't mess with you container hardly ever. And leave your 'installs' on. And remember that you'll need to recompile opencv each time the container gets issued, and the container gets issued each time you change the config (including updates). Thanks to dlandon for generally having all this stuff glued together well and entertaining numpties like myself on our issues.
-
I'll need to go back and check. Random tangent, if you change the WEBUI link in app/docker->ADVANCED, does that not work? Once you have RevProx/Authelia up and running, there isn't need/you don't really want webui to go to the IP anymore (eg have to sign in separately). Am I crazy that if I change the webui line in the docker/app, it still goes to the IP:port instead? Can you not update the template that way? You can also leave the Redis out of the config and it will work as well, but is probably also in the 'not recommended for deployment' category. Am I understanding Redis (and it's use by Authelia) correctly that it's 'transactional database storage', which to me seems like SQL for 'more raw level data'? So Authelia uses SQL/MariaDB for the familiarity and 'easy stuff' (users, etc) databases and Redis for the 'fast stuff' (tokens, in-flight, etc) databases? Another Doc recommendation may be details on docker 'start order' and waits with Authelia being last (well, SWAG/LE truly last) after Redis and MariaDB. Look forward to LDAP, I probably don't need it but do any of us really need anything we implement on the sever? I need to deploy a few more things and I might have a few more lessons learned, been knee deep in Zoneminder setup/optimizations/issues since getting baseline Authelia stuff working.
-
Here's a few gotchas that I ran into that may help others. Caveat emptor, I'm using a hybrid of Sycotix and the LSIO instructions (I'm using swag for ssl/nginx) so your mileage may vary, etc, etc. >On Duo, you actually need TWO logins. The first is your admin account that sets-up your hostname/integration_key/secret_key via Partner Auth API. Now with with you need to go into the config for the Application->PartnerAuthAPI and add a user that is THE SAME NAME as the user you have in file/ldap and then EMAIL THEM which will give you the ability to enroll the phone app to that user. Then you can enroll that in authelia when you get to that point. This page sort of says this but it's a bit cryptic and doesn't fill in all the blanks. >I wasn't able to get to the second page of the 2FA enrollment when following Sycotix instructions as described. I was in the same position, but managed to get 2FA enrollment going by going one step further in the setup and setting up a quick hiemdall instance and going to heimdall.YOURDOMAIN.etc and trying to 'login properly' and get pointed back to the target page, and at that point I was able to get to the second factor page and setup OTP and Push.
-
I hate to ask, but I've had a devil of a time getting this container to work. I can never get the webgui to load (UniFi Controller is starting up... sometimes, other times won't connect). Can anyone provide any guidance? Trying to accomplish: -Clean install (no previous config info/folders/etc) -Running the container on a separate vlan/subnet (eg br0.XX with own net stack/ip). IP address has access to WAN so I don't think it's the container downloading from the 'net that's the issue. >Also tried 'all' the net options, host, bridge, no joy with any of these either -Tried various versions (eg unifi-control:LTS, 5.9, 5.10.24-ls21, etc) Tried the competing unifi controller container, which does work, but the latest 6 controller doesn't support wifi vlans yet (that I can tell) and that's a cornerstone of my network, so I need LTS or something else that still includes vlan support. Still no joy. Any ideas would be greatly appreciated. EDIT Found it. Turns out unifi-controller, for whatever reason, really, really doesn't like docker running from remote storage (I have docker.img and /appdata stashed on another server via NFS). My guess is probably mongoDB doesn't like the NFS bottleneck? Although I've had zoneminder (you would think plenty DB heavy) running over NFS like this for ages with no issues, dunno.






